
Introduction
Any learning – be it be an animal, human or a machine for that matter, begins with an initial set of observations or as we call it – raw data. This kind of data can originate from interactions, transactions, information exchange, examples, experiences, or instructions. A brain – whether it belongs to a human or animal, tries to look for hidden patterns inside that initial data and then uses that processed information to perform further actions like taking decisions, getting values, getting details, distinguish between things and feelings like life-threatening events vs. safe event, etc.
Over time, people tried to devise out methods to implement the same using machine – methods whose primary aim is to allow the computers to learn automatically and enable them to take decisions on our behalf. Right from the early days of Bayes’ Theorem in 1763 and its further research was done by Pierre-Simon Laplace circa 1805, to the Turing’s Learning Machine which was proposed by Sir Alan Turing in 1950, huge research has been done to create machines that can learn and become “intelligent”. The very first Machine Learning algorithm is credited to Arthur Samuel of IBM for his work on programs that can play checkers in 1952. These systems and algorithms enabled computers to learn from initial data and that too with no human intervention whatsoever.
This gave rise to an all-new world of Machine Learning and Artificial Intelligence which is all set to be the most important component of present modern-day computing and day-to-day activities.
| Pre 1950s | Development and implementation of Statistical Methods |
| 1950s | Extensive research on Machine Learning algorithm development is conducted and simple algorithms were developed. |
| 1960s | Introduction of Bayesian methods for probabilistic inference in machine learning algorithms. |
| 1970s | Questions on the effectiveness and feasibility of ML algorithms stalls all the active research and projects that were scrapped. |
| 1980s | The rediscovery of back-propagation causes a resurgence in machine learning research. |
| 1990s | The paradigm shift from a knowledge-driven approach to a data-driven approach. Programs for computers to analyze large amounts of data were created to draw conclusions. Development of Support vector machines (SVMs) and recurrent neural networks (RNNs) |
| 2000s | Support Vector Clustering and other Kernel methods and unsupervised machine learning methods become widespread. |
| 2010s | Development of Deep Learning algorithms, which paved way for machine learning to become an inseparable entity to many widely used software services and applications. |
Machine Learning Definition
In all raw and basic terms, Machine Learning is defined as a set of methodologies that enables systems to automatically learn and improve from various analyses and outputs without being explicitly programmed.
To understand what is Machine Learning, we can look at it as the science of making computers to learn and act like a brain does or as humans do, and autonomously improve their learning over time by feeding them data. A machine learning process involves using algorithms to parse data, learn from it, and then make a determination or prediction about something in the world without any explicit rule-based programming.
The basic building blocks of Machine Learning algorithms involve three important components – Representation, Evaluation, and Optimization. While Representation is the first step of an ML algorithm’s implementation where we define a set of classifiers or we define finite automation that a computer can understand, Evaluation involves various scoring functions that can represent predictions of either future values or a future outcome and finally, Optimization which involves a Loss/Cost function that helps in minimizing faults and maximizing efficiency.
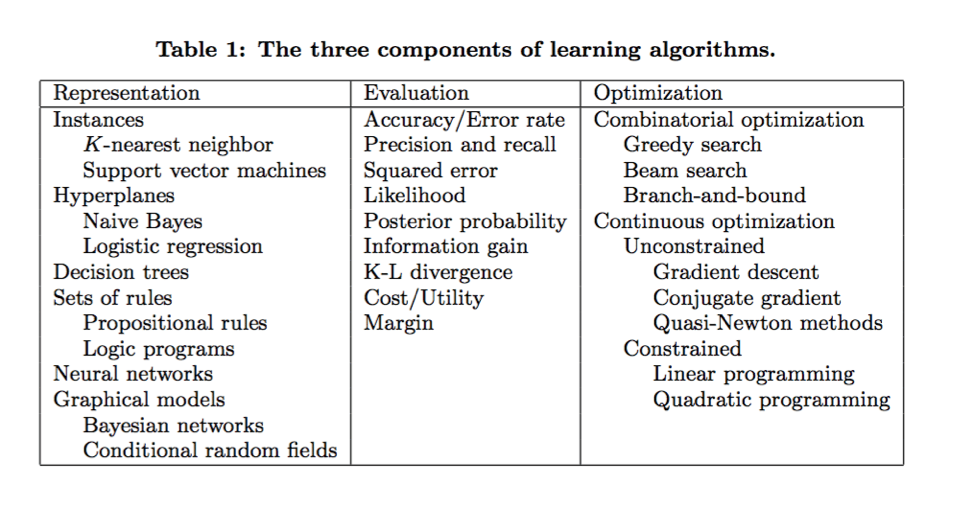
The end goal of machine learning algorithms is to make use of the past data, implement each of the above three components and then successfully interpret any new or unseen data – thus proving its worth and might in solving a plethora of business problems.
Types of Machine Learning Algorithms
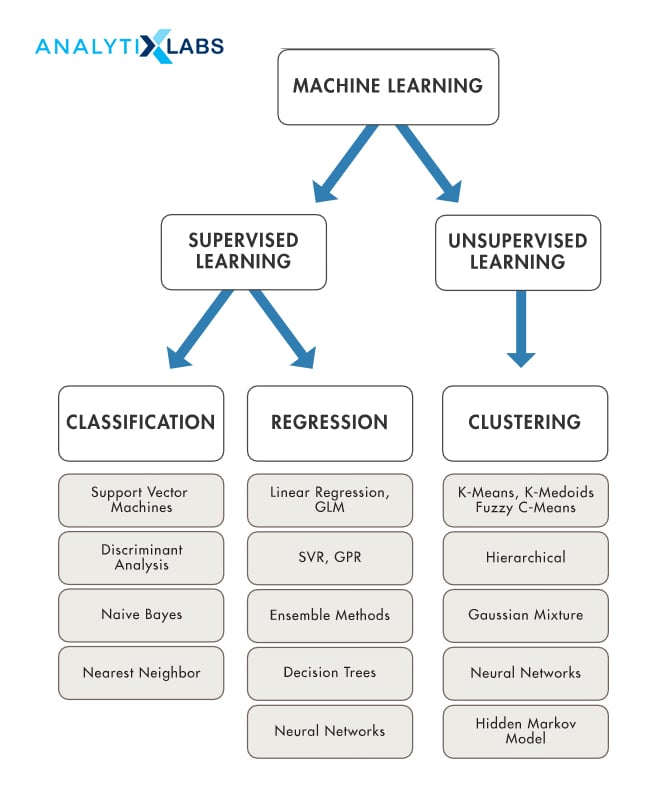
In the previous section, we have got a glimpse into what is Machine Learning – that it is a way in which the computer “learns” through input data and tries to get correct outputs. Hence, the types of Machine Learning algorithms are both fundamentally and predominantly classified and identified by their method or style of learning. The different types of machine learning algorithms are – Supervised Learning, Semi-Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning
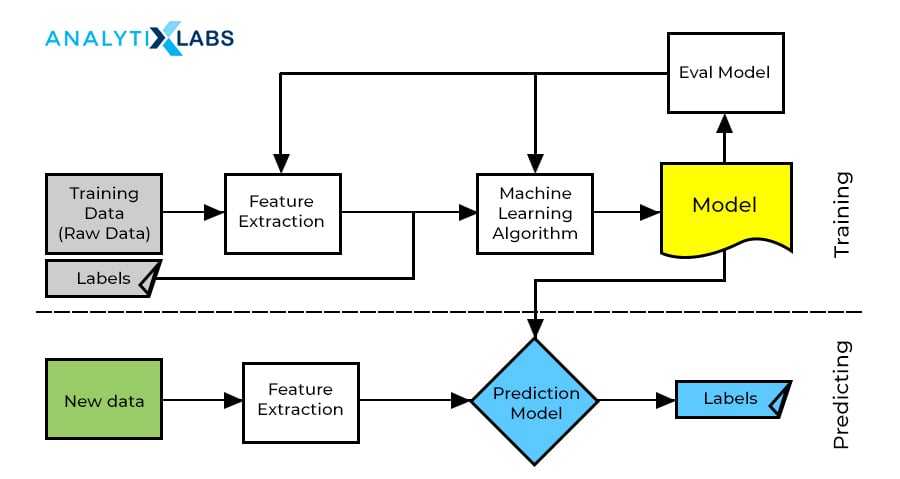
This class of algorithms makes use of the past data and uses that analysis for future predictions for values or events. However, the crisp and obvious feature of these set of the algorithm is that the data which is used for learning comprises of labels. This is the definitive and inseparable entity of supervised learning. Using these pre-labeled and priory known outputs from the data, these sets of algorithms learn from the past and creates a function that defines the driving factors for that label.
This function is then implemented on unseen and new data, where labels are predicted and outputs are obtained. The learning algorithm can also compare its output with the intended, correct outputs and calculate discrepancies and errors in order to modify the above function accordingly.
When training a supervised learning algorithm, the training data that takes part consists of inputs that are matched with their correct outputs – and hence, the algorithm will identify patterns in the data that linearly match with the desired outputs. During implementation, it will take in new inputs and will determine which label the new inputs will be classified into, based on the training data.
There are two types of Supervised Learning, and they’re Regression and Classification. Regression is a task where the end output is continuous in nature. It is typically used to predict a value, forecast, and find relationships for and in quantitative data. Classification on the other hand involves classes categorical output, either binary or more than two classes.
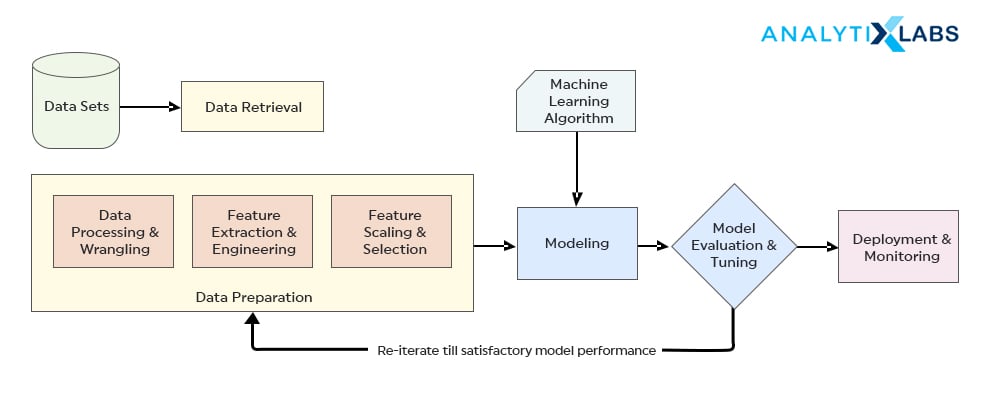
A typical Supervised Learning algorithm has the following phases – data collection, data preparation, modeling, model evaluation, deployment and monitoring.
- Data collection is one of the crucial phases of supervised learning. Any naturally occurring data – transactions, demographics, etc. can be a relevant source for Supervised Learning.
- Data Preparation is necessary to weed out unwanted components and fill in data inconsistencies in the data and this step ensures increased accuracy.
- Modeling is a phase where the algorithm converges and finds the relationship patterns between the data and labels – this phase is also known as training.
- Evaluation phase we check the errors and other corrective metrics and try to improve the model.
- Deployment and monitoring happen on new, unseen data – where the model is implemented on the same and prediction outputs are obtained.
Some of the challenges faced in supervised machine learning are irrelevant input data components – which are a leading cause of inconsistency and if present, the training data could give inaccurate results. Apart from that, like any Statistical Modelling, data preparation and pre-processing are always a challenge – like Missing Values, Outliers, etc. If this is overcome, then supervised learning is indeed stronger and easier to implement than any traditional Statistical Algorithm.
To overcome most of the challenges, some best practice techniques are followed – such as prior identification and collection of data that is to be used as a training set is performed before implementing the algorithm. It’s always better to decide the structure of the learned function and learning algorithm. A level of heuristically determined outputs and if available, mathematically derived outputs can be added to have better labeling of data and hence that can result in improved accuracy.
The most widely used algorithms in Supervised Learning are Linear Regression, Logistic Regression, Decision Trees, Naïve Bayes, Linear Discriminant Analysis, k-Nearest Neighbor, Support Vector Machines etc. Most of the supervised learning algorithms in Python are implemented using the Scikit Learn module and in R it is implemented via the caret package.
Unsupervised Learning
Unsupervised learning is a type of machine learning algorithm which are implemented to extract inferences from datasets consisting of input data without labeled responses. As opposed to supervised learning, it uses data that is not labeled at all. The primary goal of unsupervised learning is to find concealed and unknown patterns from the data. The ML algorithm system infers and discovers various information from the data and describes these hidden internal structures. There are no incorrect outputs for this class of algorithms, nor there any error metrics that can be calculated as such.
The value proposition of Unsupervised Learning is improved exploratory data analysis as it helps in finding all kinds of unknown patterns in data. They help us to find variables that can be useful for categorization. The two major types of Unsupervised Learning are Clustering and Association Rules. And others include Anomaly Detection and Latent Variable Detection.
- Cluster Analysis is the most commonly used unsupervised learning implementation, which is used for finding hidden patterns or groups in data. The clusters are modeled using a similarity or a distance measure such as Euclidean Distance, Cosine Similarity or probabilistic distance. Common clustering algorithms are Hierarchical clustering, k-Means clustering which partitions data into k distinct clusters based on the distance to the centroid of a cluster, Gaussian mixture models, Self-organizing maps that make use of neural networks that learn the topology and distribution of the data, Hidden Markov models: uses observed data to recover the sequence of states.
- Association Rules help to find interesting relationships and associations in a large set of data and discover correlations in data that is generated through various transactions in retail, banking, medical, insurance, etc. Majorly used association rule algorithms include the Apriori algorithm, FP-Growth, etc.
- Anomaly Detection techniques can detect unwanted, inconsistent, extreme, and missing data points in the data. A few of the important applications of such algorithms can be seen in Data Preparation like imputing missing values (MICE package in R/Python), Cyber Security, and Transactional Frauds, etc.
- Latent Variable Models are a family of algorithms that can help in reducing dimensionality and most widely used in conjunction with Clustering Algorithms. Common algorithms include Principal Component Analysis, Factor Analysis, etc.
| Parameters | Supervised Learning | Unsupervised Learning |
| Input Data | Trained using labeled data. | Used against data which is not labeled |
| Computational Complexity | Supervised learning is a simpler method – involves creating linear or noon linear equations.Algorithm Convergence time is lessResults are easily interpretable | Unsupervised learning is computationally complex Algorithm convergence is relatively slow and much inaccurate.Results cannot be interpreted by mathematical proof alone – needs to have heuristic sense as well. |
| Accuracy | Highly accurate and trustworthy method. | Less accurate and least trustworthy method. |
Semi-Supervised Learning
Semi-Supervised Learning as the name suggests, it’s a combination of the worlds of supervised and unsupervised learning algorithms. It uses a small amount of labeled data and a large amount of unlabeled data. The major contribution of these algorithms is that they provide improved efficiency to the unsupervised learning models. And not only that, they are able to add a layer of control for the Unsupervised Models.

An important aspect of semi-supervised learning algorithms is that they can be used to create proxy labels. Whenever we don’t have sufficient labeled data to perform supervised learning, we can add the unlabeled data to increase the training data size, get new labels, and then used the newly formed data for Supervised Learning. These include self-training, multi-view learning, and self-ensembling, and Pseudo-Label. This technology has been widely and famously used in Amazon’s Alexa.
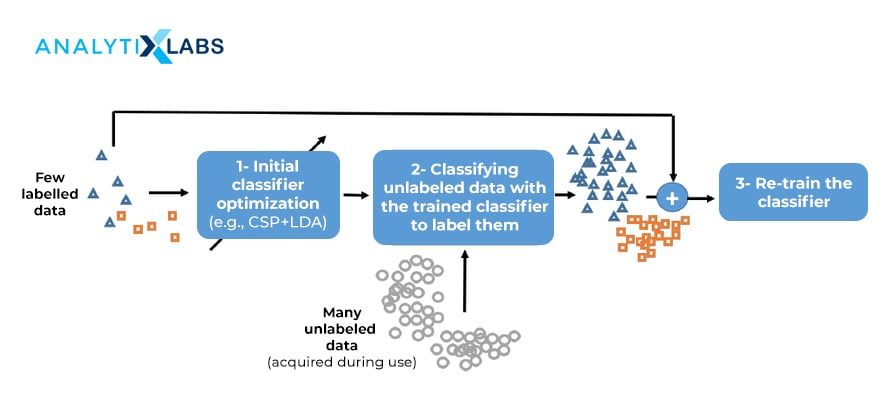
Some important applications of Semi-Supervised Learning are in:
- Speech Analysis: To detect various labels and identification like person identification, tone identification, identifying a music note, etc.
- Internet Content Classification: Used widely in Network Analysis where documents such as News Articles, White Papers, etc. are labeled according to their contents.
- Protein Sequence Classification
- Image Segmentation: To detect and identify components that are usually left unmarked by the user prior to training.
Reinforcement Learning
These algorithms perform dynamic implementation and evaluation simultaneously during the learning process – meaning, learning takes place in an interactive environment by hit, trial and error, using feedback from its inputs and outputs. It interacts with the environment by producing actions and results and in the same instance, it discovers errors and accuracy.
This method empowers machines and software agents to automatically determine the ideal behavior within a specific scenario, with an aim to maximize its performance – the decisions here are taken sequentially as opposed to Supervised Learning where the decisions are independent of each other.
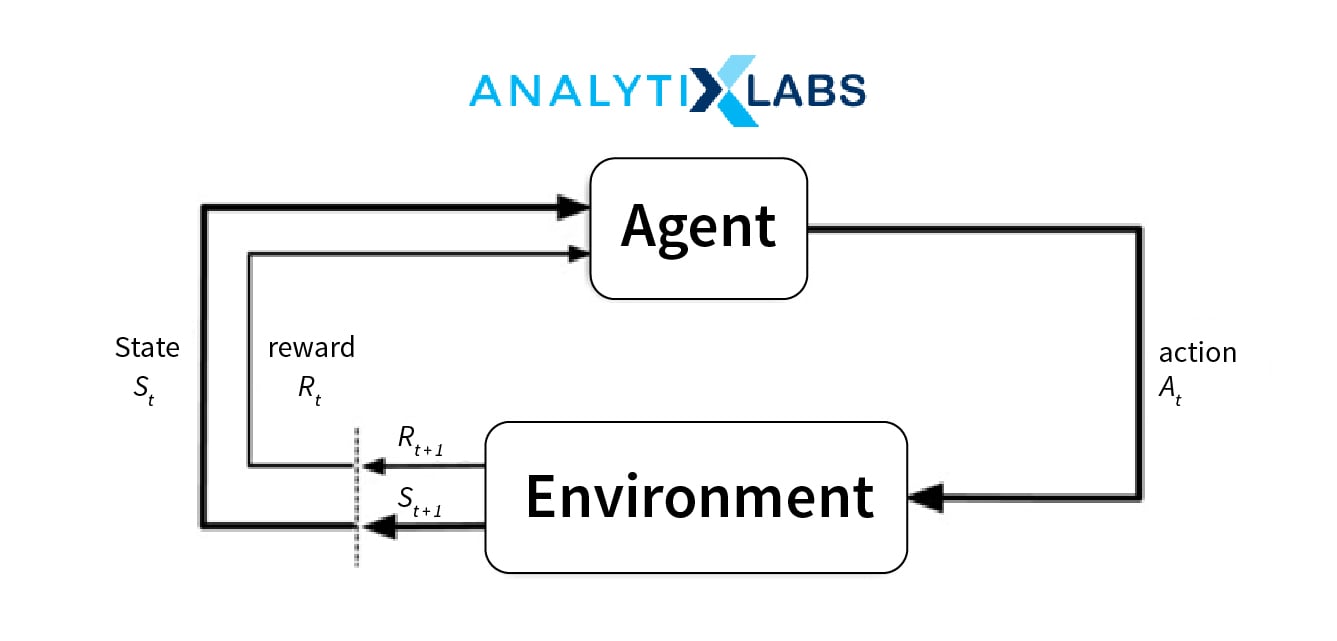
In RL, we use the following components – environment, state, reward, policy and value. The major implementation challenge is in the design of the simulation environment – which in turn is highly dependent on the type of task being performed and the kind of business problem being addressed. Also, this environment needs to be translated into a real-life scenario. The rest of the implementation process is concerned with scaling and optimization which can be easily addressed with existing implementations of the same. Some of the most widely used RL algorithms are Q-Learning, State-Action-Reward-State-Action (SARSA), Deep Q Network (DQN), Deep Deterministic Policy Gradient (DDPG).
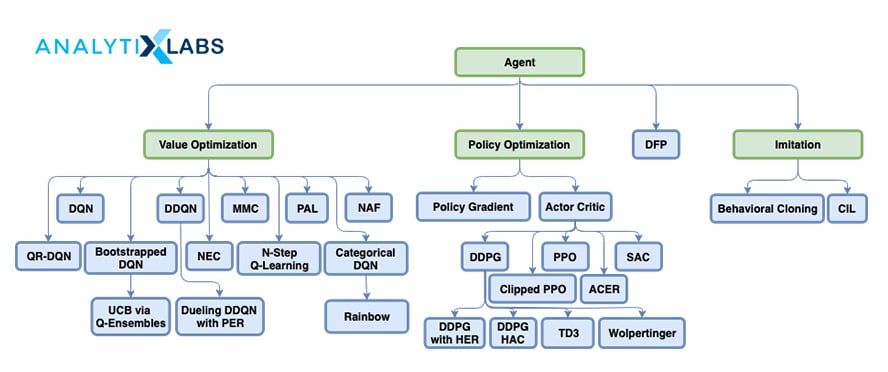
In Python, RL is implemented using various packages like pyqlearning, KerasRL, Tensorforce, rl_coach, ChainerRL, MAME RL (MAMEToolkit) and MushroomRL, etc. In R, we make use of packages such as reinforcementlearning, MDPtoolbox, etc.
Reinforcement Learning is used in automation processes mostly – robotics, online games, interactive guided instructions or tours, text summarizations, etc.
| Supervised Learning | Unsupervised Learning | Semi-Supervised Learning | Reinforcement Learning | |
| Definition | Learning takes place by using known and labeled data to predict a value or an event for unseen data | Learning patterns and similarities and hidden groups from an unlabelled data | Making use of a little amount of labeled data and combined with a large amount of unlabeled data for improved exploratory data analysis | A predefined agent interacts with a simulated environment and performs correct actions which the machine learns through trial and error methods |
| Type of Business Problems | Regression and Classification | Association and Clustering | Data Labelling | Reward-Based Learning |
| Data Used | Labeled Data | Unlabeled Data | A mix of Labeled and Unlabeled Data | No predefined data as such |
| Training Method | External Supervision | No Supervision | No supervision or Limited Supervision | No Supervision |
| Convergence Approach | Maps the inputs to known labels | Understands patterns, similarities, and associations | Understands patterns, similarities and associations which is controlled by the labels given as input | Follows a trial and error based learning method to reach to the correct output. |
| Algorithms | Linear Regression, Logisctic Regression, Support Vector Machines, Naïve Bayes, KNN, Decision Trees etc | K-Means, Hclust, PCA, Factor analysis, UBCF, IBCF, Arules | Pseudo-Labeling, Semi-Supervised Generative Adversarial Network (SGAN) etc. | QLearn, SARSA, etc. |
| Applications | Insurance Underwritting aud Detection | Customer Segmentation Recommendation Engine | Medical Predictions | Gaming AI Decision Problems Reward Systems |
You may also like to read: Different Types of Machine Learning Algorithms With Examples
Applications of Machine Learning
Image Recognition:
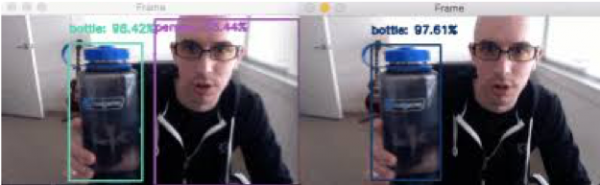
Image recognition is one of the most common applications of machine learning which makes use of image segmentation techniques. We have done a detailed discussion on the same, where we have seen its wide applications and the concepts around Image Segmentation and how Machine Learning makes it feasible. It is used to identify objects, persons, places, digital images, etc.
Speech Recognition
Speech recognition is a process that involves converting voice instructions to text and then perform subsequent classification, segmentation, etc. Various virtual assistants like Google Assistant, Siri, Cortana, etc. make use of this technique.
Traffic predictions:
Using map-related data such as traffic density, road signs, traffic signs, etc, various applications have been developed that efficiently convey map-related information to users. E.g. Google Maps, Waze, OpenMaps, etc.

Product recommendations:
By making use of various association rule engines, various retail, eCommerce and entertainment services are able to develop recommendations for their users based on various levels of associativity. Eg. Amazon product recommendations, Netflix etc.

Email Filtering:
Various text classification techniques can be applied to emails for effective classification into spam and non-spam. Apart from that, a multi-class classification of email can also be done, for example, the way how Google classifies an email and makes it land into the inbox, Social, Promotions, or Spam. Segmentation can also be used for email data to put them into n number of unknown groups which can be used as a personalization tactic to deliver relevant emails to subscribers based on their geographic location, interests, purchase history, etc.

Self-driving cars:
Machine learning plays a pivotal role in self-driving cars. Tesla, the most popular car manufacturing company is working on self-driving car. It is using unsupervised learning methods, reinforcement learning methods to train car models to detect people and objects.

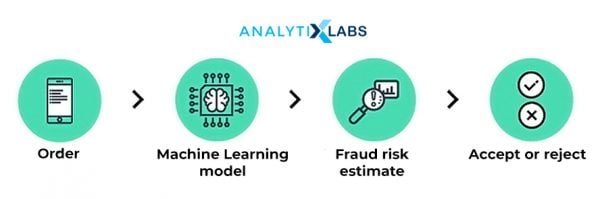
Online Fraud Detection:
Fraudulent transactions have features and characteristics that separate them from legitimate transactions. Using regression and classification techniques, we can implement the various levels of Fraud Detection, Fraud Reporting, and Fraud Prevention applications.
Stock Market:
Machine learning’s long short term memory neural network is used for the prediction of stock market trends by taking into consideration the fluctuations, patterns, dependent factors, external factors, moving averages, etc.
Read this blog to know more about Stock Market Prediction Using Machine Learning Techniques
Medical Diagnosis:
By implementing various Image Segmentation algorithms of Machine Learning, we can perform effective medical diagnostics by recognizing patterns that usually escape the human eye. This has helped in the early detection of tumors, cancers, artery blockages, etc. by implementing ML algorithms on medically generated data.
Automatic Language Translation:
Machine translation is a task that generally uses machine learning models developed using highly sophisticated linguistic knowledge and other related data to achieve a correct translation of text from one language to another. Combined with Natural Language Understanding – which also uses Supervised Learning – Machine Translations have become a crucial part of business transactions.

Examples of Machine Learning in the Industry
- Netflix Recommendation Engine uses Association Rules to suggest shows based on the viewer’s past history, browsing history, etc.
- Customer Lifetime Value metric calculation by Retail Companies to better understand a customer and help retain them.
- Cross-sell and Up-sell used by Amazon which uses recommendation engines.
- Predicting Disease using a patient’s medical diagnosis reposts based on past data of hundreds of other patients.
- Credit Risk Score and Creditworthiness calculation using the transactional data and identifying fraud customers.
- Targeted email campaigning by tools like Optimail – which uses unsupervised learning to identify the hidden similarities in the customers and use that information for tailor-made emails.
- Ranking posts on Twitter and Facebook and showing relevant and important comments, posts, etc. and as a by-product hide spam and other harmful and abusive content.
- Computer vision in the food processing plant to detect defective products or packaging etc.
- Quora’s answer ranking system to enable users to get the most relevant answers to a question.
- Data driven marketing used by brands like Heineken to improve operations, marketing, ads and customer service.
- AI-powered chef developed by IBM that can help in getting unique flavor combinations.
- Song and music recommendations by Spotify.
- Data driven systems to improve productivity, ensure safety and increase the performance by energy giant British Petroleum.
- Real-time fraud and anomaly detection by American Express, which analyses millions of transactions at a given instance and classifies them into varying levels of risk/safety classes.
- Improved content discovery, spam detection, detecting sources of monetization from images by Pinterest
- Smart sales machine by HubSpot allows them to identify important events or “trigger events” such as changes to a company’s structure management, incorporations, etc., to effectively pitch prospective clients and serve existing customers.
- Traffic alerts by Google by making use of the enormous data generated by Google Maps – such as location, traveling speed, supervised labeling like mini questionnaire, surveys, enabling users to report an event on the road such as road closure, route diversions, accidents, etc.
- Sentiment analysis where open-ended surveys can be classified as a good review or a bad one and further performing Intent Analysis to see the reasons that are driving the sentiment.
- Automated Speech Assistants and Chatbots that provide faster attendance to customer’s needs online – are implemented by machine learning.
- Google Translate makes use of Google’s Neural Machine Translator to enable users to get accurate translations.
AI VS ML (Major differences)
Machine Learning and most predominantly, Artificial Intelligence are two hot and trending skills and requirements in the industry, and wrongfully so, the usage of both buzzwords has been done interchangeably. Till now, we have thoroughly seen what Machine Learning is, now let’s understand the major differences between Artificial Intelligence vs. Machine Learning. To begin with, Machine Learning is an application of Artificial Intelligence, which relies on data and enables computers to utilize this data and learn patterns. On the other hand, Artificial Intelligence is an umbrella term for various methodologies like ML, Deep Learning, etc. that makes a machine smarter.
| Artificial Intelligence | Machine Learning |
| Artificial intelligence is a set of methods that enables a machine to simulate human/ animal brain behavior. | Machine learning is a part of AI which allows a machine to learn from data without autonomously, i.e., without explicit programming. |
| The goal of AI is to make a self-aware system that can solve complex problems without any human intervention | The goal of ML is to enable machines to learn from past data in order to obtain the accurate output. |
| Once developed and deployed, an AI system is aimed at solving a plethora of interrelated tasks. | Machine learning on the other hand can perform only those specific tasks for which they are trained. |
| AI system is concerned about maximizing the chances of success by “rewarding” the systems on each successful event. | Machine learning is mainly concerned with accuracy and patterns. |
| AI has a very wide range of implementation scope. | Machine learning is limited to mostly traditional data sources |
| It includes learning, reasoning, and self-correction. | It includes learning and self-correction when introduced with new data. |
| AI can deal with Structured, semi-structured, and unstructured data. | Machine learning deals with Structured and semi-structured data only. |
| AI can be divided into three types: viz., Weak AI, General AI, and Strong AI. | Machine learning, on the basis of the process involved, is divided mainly into four types: Supervised, Unsupervised, Semi-Supervised, and Reinforcement learning. |
| The main applications of AI are Image Segmentation, Expert systems, Online game playing, an intelligent humanoid robot, etc. | The main applications of machine learning are Online recommender systems, Google search algorithms, Facebook auto friend tagging suggestions, etc. |
Learning ML
The mammoth importance of Machine Learning is Data Science stack has been talked about by many people, by many entities that implement it, so much that words actually fall short of it. This clearly implies that Machine Learning is *the* most important skill set that one needs to acquire to enter into the Data Science realm. Right from someone who is working in various Business Intelligence and Visualization tools for Exploring Data to someone who has implemented Predictive Modelling using traditional Statistical methods, Machine Learning concepts are a must learn.
The industry implements the said techniques, majorly in Python, for most of the practical aspects and also in R, if the work requires some orthodox touch and research work. Hence, the Machine Learning certification course has been one of the most sought out courses by many.
From the recruitment perspective, a job seeker can target a plethora of jobs as a Data Scientist, Machine Learning Engineer, AI Engineer, and the likes. To become a Data Scientist, which is an inclusive term for a job role that requires proactive decision-making in conjunction with scientific methods, Machine Learning is of primary importance.
For someone who is looking for deep-diving into Artificial Intelligence, one needs to know the core concepts obviously but the major driving force here again is Machine Learning and the best part is that there are no difficult hurdles in form of the pre-requisites to learn AI in particular and Machine Learning in General.






3 Comments
Good information.I would like your article.Keep share more articles and pass information. very informative related to machine learning. in business analyst this concept plays very important role. so its helps me to study all basic concept of business analyst
hello
i really appreciate the way you expressed your knowledge of machine learning through this article. i got to know alot of new things about machine learning, hope you will keep on posting more related articles.
thank you
Hello
Thank you very much for sharing this valuable knowledge with us. i appreciate your work. can you please share your knowledge on future scope of machine learning.