
Embarking on a journey into data science, particularly in the dynamic realms of machine learning and deep learning, introduces us to many new concepts and terminology. Gripping the essence of various terms, among which “parameters” hold significant importance, is fundamental to this exploration.
Whenever you learn model development, you must understand the concept of parameters, as the success of a data science project often depends on how well you understand it. For example, leading data science organizations conducted a survey revealing that 85% of successful projects attributed their success to teams demonstrating a deep comprehension of parameters and their implications.
This article will focus on understanding the meaning of terms such as “model parameters”, “model hyperparameters”, “hyperparameter optimization,” etc. However, you must familiarize yourself with basic model development concepts to understand these terms.
Mastering Hyperparameters: Key Concepts
A few key concepts of model building that you need to know to understand the concepts around parameters are as follows.

#1. Dependent and Independent Variable
Businesses want to know about future events to prepare themselves better and maximize their chances of survival. One way to do this is to look at the past, i.e., use historical data to understand what can happen in the future.
For instance, if a bank aims to predict loan defaults, it analyzes past data. This involves examining applicant details like age, income, location, and loan amount, comparing them against loan defaults. The goal is to comprehend the relationship between these factors and loan default. These factors are independent variables, while loan default is the dependent variable.
Data modeling seeks to grasp how independent variables impact the dependent ones, aiding accurate predictions with new data. Classification models are used for categorical dependent variables, while regression models handle continuous ones.
#2. Types of Models
Many models exist, such as statistical, machine learning (ML), and deep learning (DL). Statistical models use statistical theory to map the relationship between the dependent and independent variables.
ML models learn patterns from the data to make predictions using complex mathematical equations. DL, often considered a subset of ML, mimics the human brain and uses neural networks to map relationships and perform predictions.
#3. Types of Algorithms
Different types of algorithms are associated with different types of models. Algorithms are computational procedures that use a particular mathematical or statistical technique to learn the relationship between the dependent and independent variables.
For example, linear regression and logistic regression are algorithms associated with statistical modeling, whereas algorithms associated with ML are random forest, support vector machines, K nearest neighbor, etc. Common DL algorithms include Multi-Layer Perceptron (MLP), Convolutional Neural Networks (CNNs), and Recurrent Neural Networks (RNNs).
Also read:
- Random Forest Regression – How it Helps in Predictive Analytics?
- KNN Algorithm in Machine Learning
- Convolutional Neural Networks
#4. Model Fitting
Model fitting is an important concept in ML/DL. It refers to the model’s training on data to map the relationship between the dependent and independent variables. The model’s performance with new, unseen data is determined by how well it “fits” the training data.
#5. Underfitting vs Overfitting
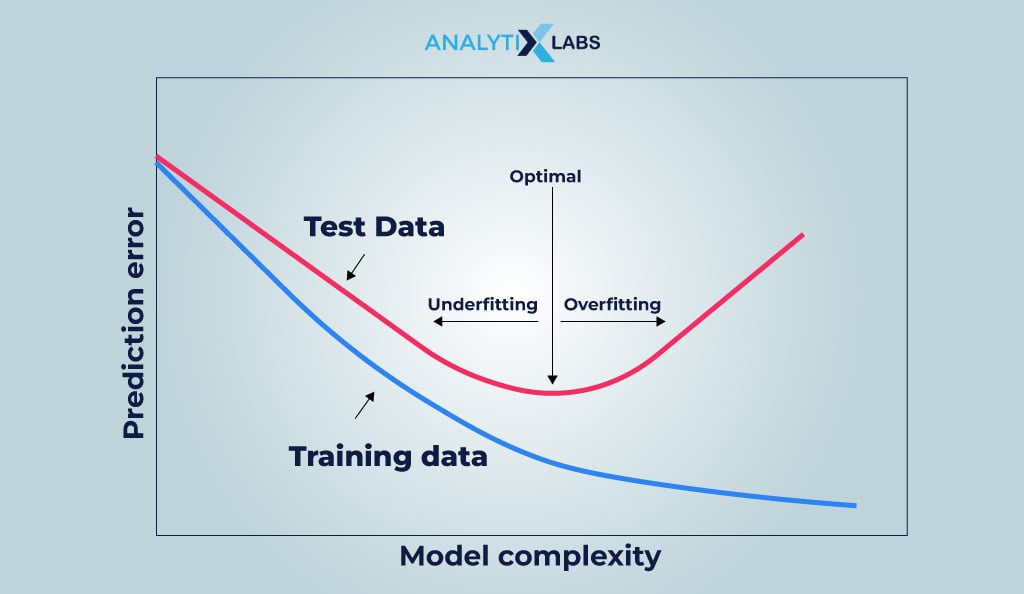
When a data model is built, the data for model development is split into training and testing. The training data is used to “fit” the model. In contrast, the testing data acts as the unseen data on which the model’s performance is judged. Underfitting happens when the model has bad training and testing performance.
This happens because the model cannot properly map the relationship between the dependent and independent variables, mainly due to the model being simple, i.e., less complex, or insufficient availability of training data. In overfitting, the model performs well with the training dataset but poorly with the unseen data (testing data).
This happens because the model fits the training data extremely well, capturing even the random fluctuations and noise when understanding the patterns in the data. Overfitting can also happen because the model is highly complex or the training data has too many features.
#6. Bias vs. Variance
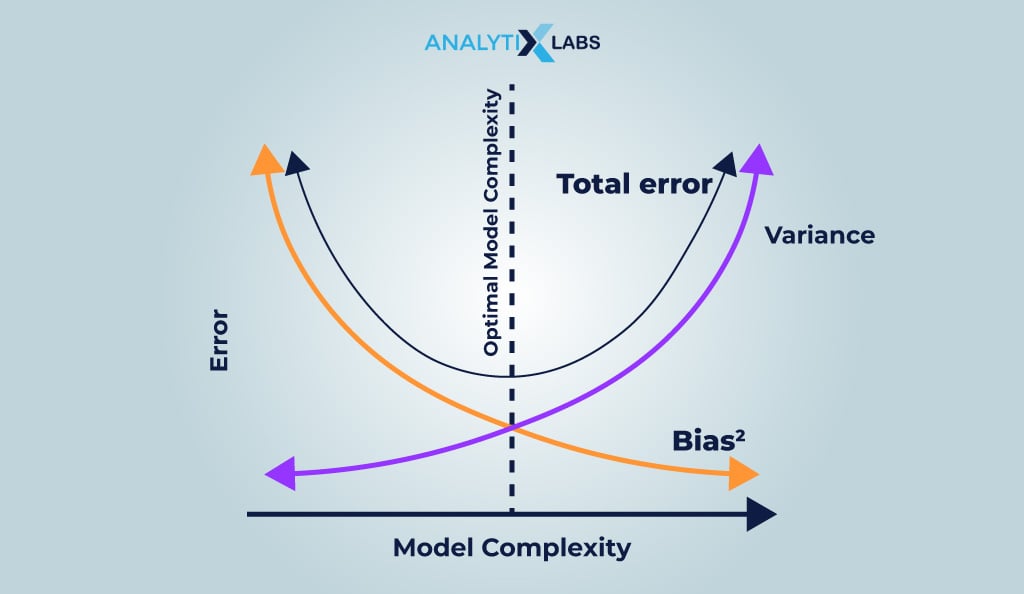
Underfit models exhibit high bias and low variance, while overfit models show low bias and high variance. In machine learning/deep learning, bias refers to the error stemming from oversimplified models that cannot capture complex data relationships. This can be likened to a naive individual who fails to grasp surrounding events.
Variance arises when complex models overinterpret data, detecting patterns that don’t exist due to random noise. Analogous to a conspiracy theorist, such models perceive connections where there are none, influenced by minor fluctuations in training data.
Thus, there is a trade-off between bias and variance. A model with high bias is too simple and fails. As the model complexity increases, the bias decreases, consequently increasing the variance. If this goes too far, the model becomes too complex and fails again. Therefore, one needs to strike a balance between bias and variance. The concept of parameters helps with this process.
#7. Parameters
Parameters are the tuning knobs that regulate the complexity of the model and the environment in which they function. There are two kinds of parameters- model parameters and hyperparameters.
By manipulating these parameters, the data science professional can create conditions that increase the bias (thereby decreasing the variance) or reduce it to ultimately reach the optimum balance between them. Achieving such a balance is important as it allows the model to generalize the data well.
When we say a generalized model, we imply that it effectively handles both the training and testing data, ensuring it can reliably perform when encountering new, unseen data in the future.
As the basic concepts are done, let’s start understanding the two most crucial aspects of machine and deep learning modeling: model parameters and hyperparameters. We’ll start by exploring model parameters, but before that, a short note-
Explore our signature Data Science and Analytics courses that cover the most important industry-relevant tools and prepare you for real-time challenges. Enroll and take a step towards transforming your career today. We also have comprehensive and industry-relevant courses in machine learning, AI engineering, and Deep Learning. Explore our wide range of courses. P.S. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
What is a Model Parameter?
The most fundamental parameter in model building is the model parameters (sometimes called “parameters”). These internal parameters are discovered by fitting the model to the data and making predictions, allowing it to learn from it.
Manual setting or tuning by an external process doesn’t apply to these parameters. Instead, they are determined as the algorithm maps the relationship between independent and dependent variables, becoming part of the learned model.
Finding the values of model parameters involves an optimization algorithm like gradient descent. In this process, the initial values of the model parameters are first set to 0 or some random values, then updated using the optimization algorithm that uses a cost function to find the optimal value. The optimal value is the one that minimizes the cost (i.e., maximizes the accuracy of the model and best fits the training data).
Common examples of model parameters include slope/coefficient (b) and intercept (c) in linear regression or weights (w) and bias (b) in neural networks.
Let’s now look at another and the most crucial type of parameter- hyperparameter in machine learning and deep learning.
What is a Hyperparameter?
The second major type of parameter in machine learning is known as hyperparameters. The model developers explicitly define these parameters to control the learning process and determine model parameter values that the algorithm uses to learn.
The prefix “hyper” in hyperparameters indicates their role as top-level parameters controlling the learning process. Hyperparameters exist externally in the model and cannot be estimated using the data. This is because the developer sets the hyperparameter values before the model training begins, and their values do not change during the learning phase.
In the search for optimum hyperparameter values for a specific problem, practitioners typically discover them through the rule of thumb, trial and error, or by adopting values employed in solving similar problems previously.
Next, we will discuss a few more aspects of hyperparameters in machine learning, such as their categories, hyperparameter space, and types of distribution.
Categories of Hyperparameters
Hyperparameters can be grouped into the following categories.
1) Model Hyperparameters
Certain hyperparameters are specific to certain models as they are involved in the model’s structure. Therefore, such hyperparameters define the construct of a model itself. For example, model hyperparameters in deep learning can be attributes of a neural network, such as the number of hidden units, layers, filter size, padding, pooling, stride, etc.
2) Optimizer Hyperparameters
The other type of hyperparameter is the optimizer hyperparameter, used in the optimization process. We call them optimizer hyperparameters because they optimize the model’s performance by dictating how the model learns the patterns in the data. Examples of optimizer hyperparameters in deep learning include the optimization algorithm, learning rate, batch size, etc.
3) Data Hyperparameters
Data hyperparameters deal with data to be used for training. Often, data is not enough, doesn’t have enough variation, or is not in the required shape or form. This is where data splitting, data sampling, and data augmentation techniques like resizing, cropping, binarization, etc get involved. Examples include train test split ratio, the value of k in k-fold cross-validation, etc.
Understanding Hyperparameter Space
The hyperparameter space encompasses all possible combinations of hyperparameters in training an ML/DL model. It is conceivable as a multidimensional space where each dimension represents a hyperparameter. Approaches like random search, grid search, etc., find the optimal result from this hyperparameter space.
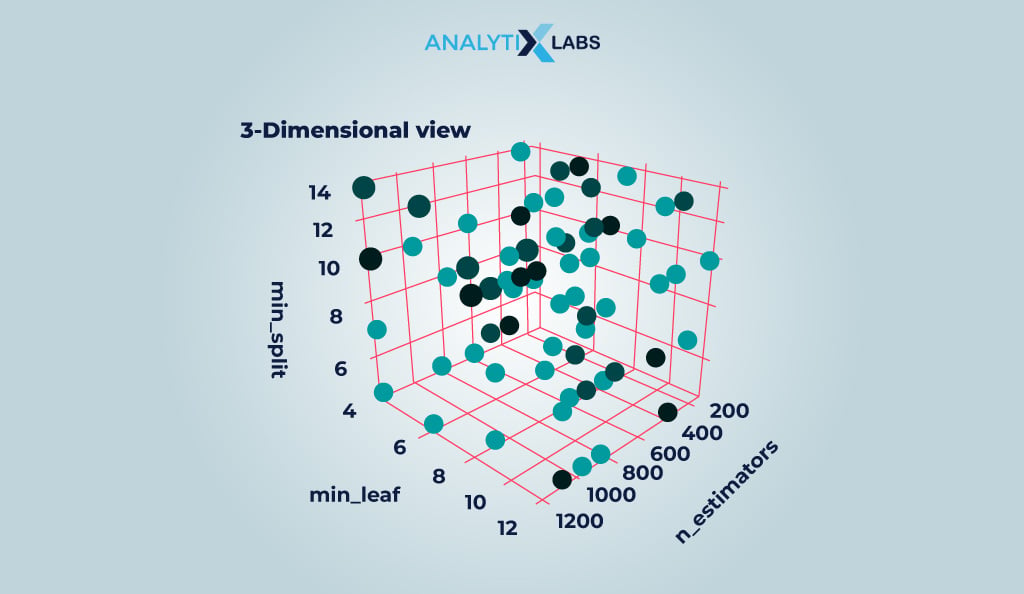
Hyperparameter Distributions
Hyperparameter distribution refers to the distribution of hyperparameter values within the hyperparameter space. It defines the values each hyperparameter can take and provides the probability of each value occurring.
Types of Hyperparameter Distributions
Different probability distributions can define the hyperparameter space in ML/DL. These distributions help determine the range of values for a hyperparameter and the probability of different values occurring. Common hyperparameter distributions are as follows-
- Uniform distribution: All hyperparameter values have an equal chance of being chosen.
- Gaussian (Normal) distribution: The values of a hyperparameter follow a normal distribution. This is often the case when certain factors influence the values.
- Log-normal distribution: When a hyperparameter’s values are positive and skewed (allowing for a greater range), they follow a distribution whose logarithm is normally distributed.
In the next section, we will explore model parameters vs. hyperparameters.
Model Parameter vs. Hyperparameter
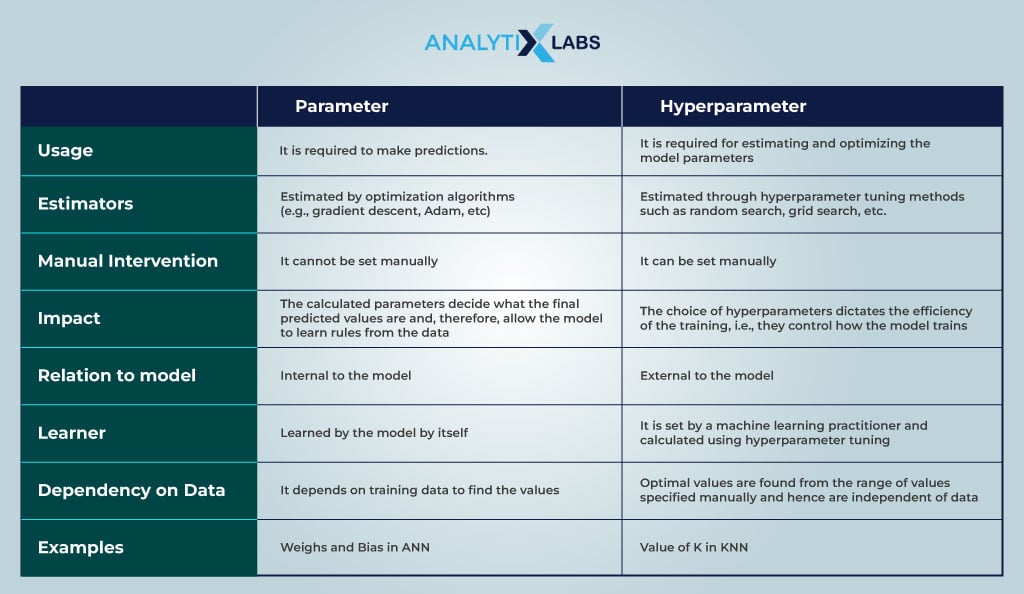
Now, let us understand the difference between the two types of parameters, model parameters, and hyperparameters. This is important for a machine learning practitioner because you must be clear about how they differ. The table below summarizes the difference between the two.
Examples of Model Hyperparameters
Understanding model hyperparameters is crucial, as they are vital in machine learning and deep learning. When it comes to hyperparameter tuning, model hyperparameters are often the focus. Exploring examples of these hyperparameters and key optimizer hyperparameters is essential. Adjusting certain model hyperparameters can increase variance, while others may have the opposite effect.
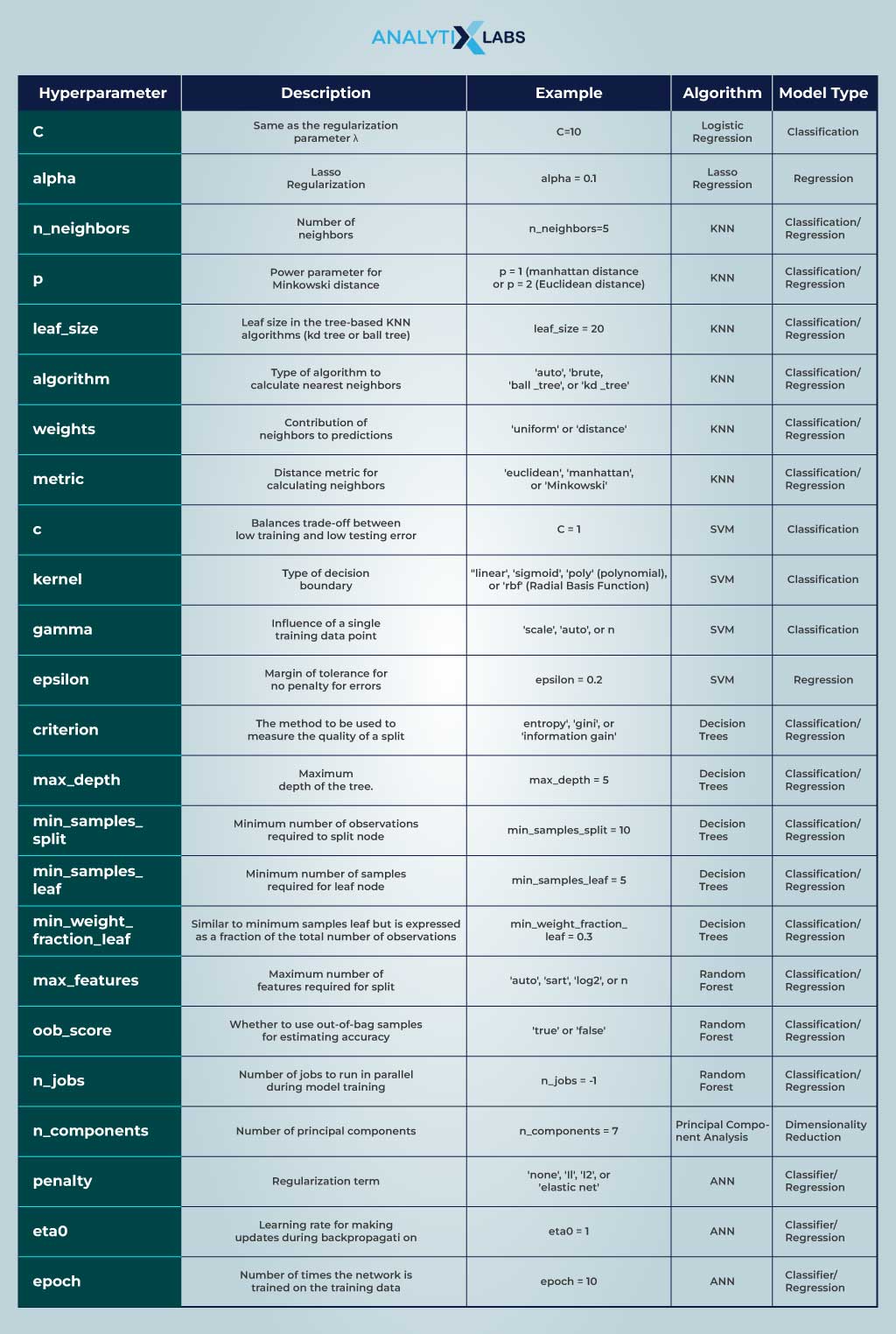
While there are many more examples of hyperparameters in machine learning, the ones mentioned are used most often. However, hyperparameter tuning is needed to find their optimum values.
What is Hyperparameter Tuning?
Optimizing hyperparameters is crucial for enhancing machine learning model performance, ensuring it generalizes well to training data without underfitting or overfitting. This process, known as hyperparameter tuning, aims to find optimal values that maximize reliable accuracy within a reasonable timeframe.
However, it’s challenging due to hyperparameters’ diverse impact on different algorithms. Despite its time-consuming nature, hyperparameter tuning controls a model’s function, structure, performance, and resource consumption, making it an essential aspect of model development.
Let’s understand hyperparameter tuning in machine learning with a simple example. Suppose you have data on which you want to train a decision tree classifier. You split the data with 80% training and 20% testing data. You choose the following three hyperparameters viz.
Maximum depth
-
- Control the maximum depth of the tree with a deeper tree capturing more complex relationships
- To search from 1 to 3.
Minimum samples split
-
- Control the number of samples required for splitting a node
- To search from 4 or 5
Min weight fraction leaf
-
- Control the minimum size of the leaf node
- To search from 0.1 to 0.4
Given the above-specified hyperparameters configurations, the decision trees are made to fit on the training data 25 times using the different combinations of hyperparameters to get the following training and testing accuracy.
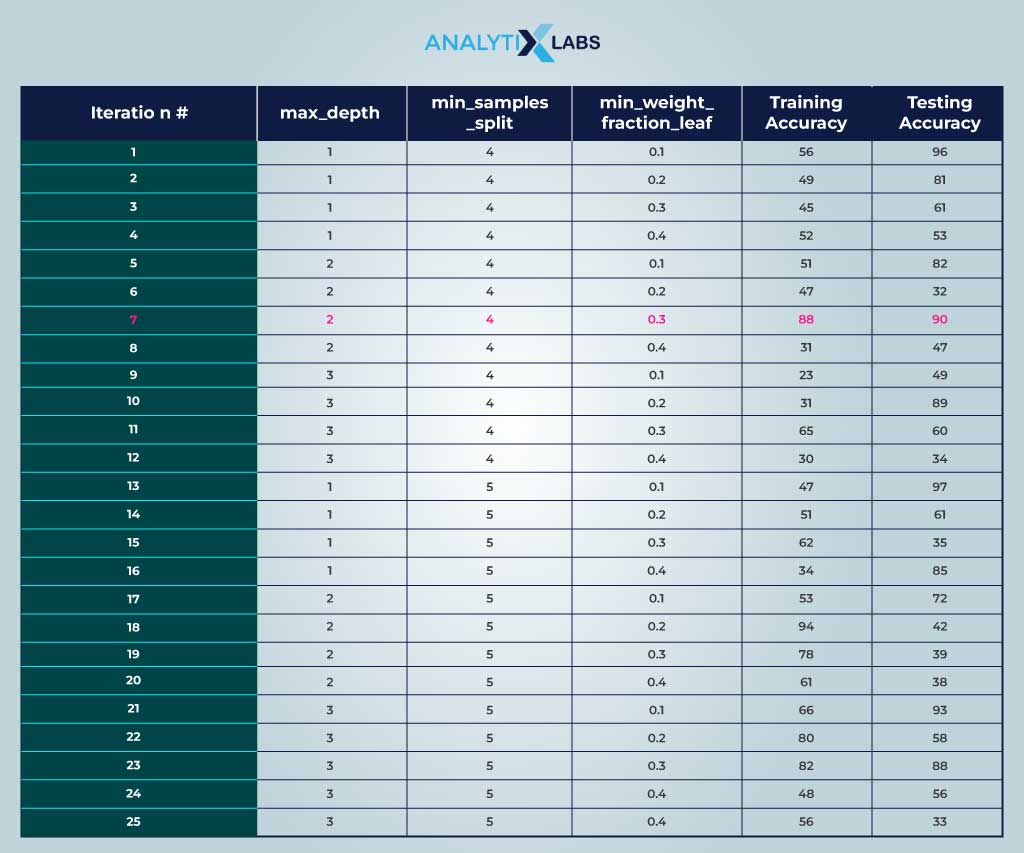
In such a case, you will go with decision tree #7 as the combination of hyperparameters seems optimal because the training and testing accuracy is decent, indicating that such a model has generalized well.
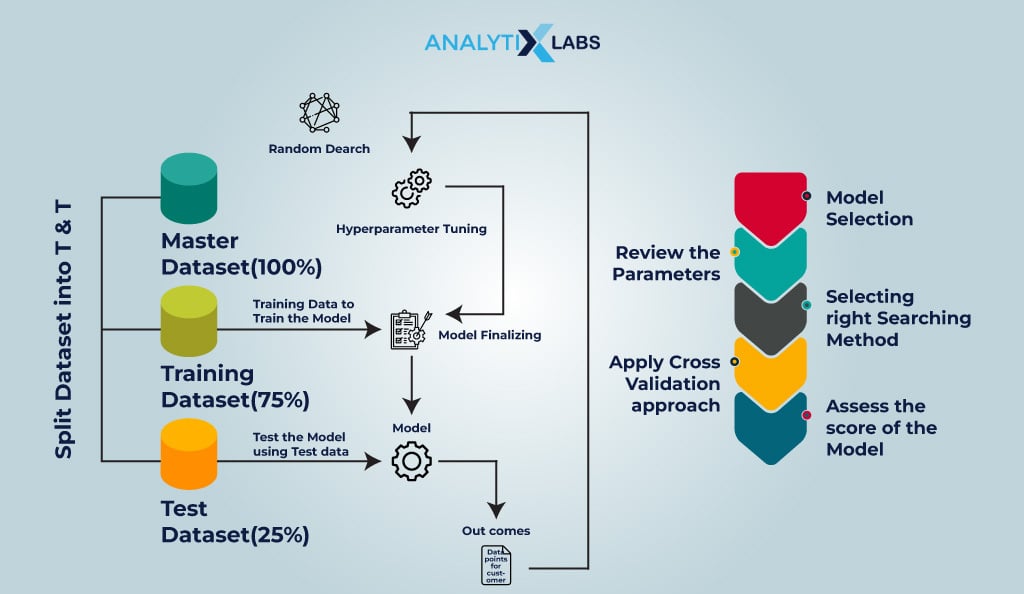
Typically, hyperparameter tuning in machine learning is performed by following the steps mentioned below-
- Step 1: Select the model type based on the data type.
- Step 2: Select the appropriate algorithm based on the business objectives and domain understanding.
- Step 3: Review the list of parameters associated with the model and choose the appropriate hyperparameters.
- Step 4: Build the hyperparameter space, i.e., specify the values for hyperparameters from which the optimal value will be chosen.
- Step 5: Choosing the cross-validation approach. The range of techniques can vary from simple methods like holdout validation (which involves splitting data into train and test sets) to k-fold cross-validation (which divides data into k subsets, training and testing the model k times on different folds).
- Step 6: Tuning Hyperparamers and fitting the model to the training data.
- Step 7: Evaluate the model performance score and assess the final hyperparameters.
- Step 8: If the model performance is inadequate, the steps from step #2 are performed again.
Step #6 is crucial and multifaceted in the above steps. Several techniques can optimize the hyperparameters. The next section will discuss how to perform hyperparameter tuning.
Techniques for Hyperparameters Tuning
There are multiple techniques for hyperparameter tuning. The most prominent ones are as follows.
#1. Manual Search
The most basic way to optimize hyperparameters is using manual search. In this method, the machine learning practitioner manually selects the hyperparameter values based on their knowledge and experience.
In this approach, the model trains and evaluates for each combination of hyperparameters. The model developer doesn’t need to rely on any library, yet it’s solely beneficial when the hyperparameter count and value range are constrained.
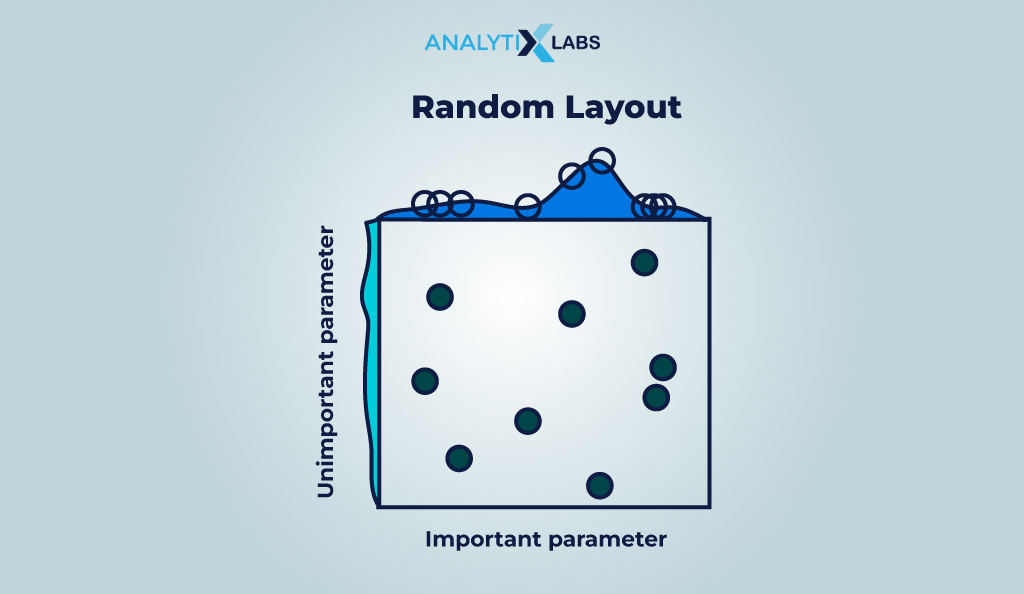
#2. Random Search
Random search defines a range of possible values for different hyperparameters. Then, from all the possible combinations (i.e., from the hyperparameter distribution), different combinations are picked randomly to train the model and evaluate the results.
Based on the results, the best set of hyperparameters is identified. While less systematic and effective in finding the true best hyperparameters, this method works well when a set of hyperparameters is large and the model is complex.
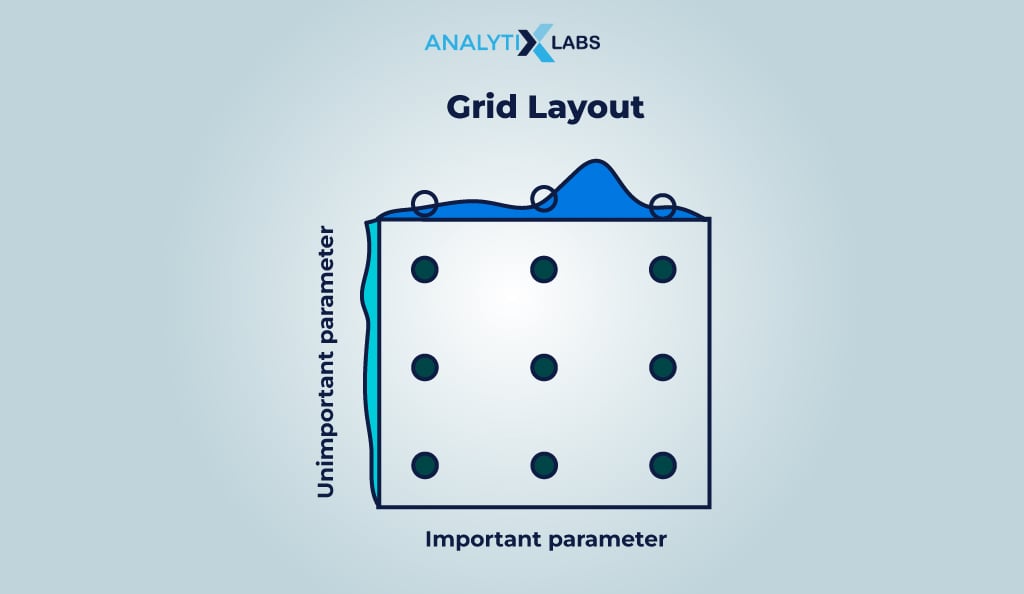
#3. Grid Search
Grid search fits the model using all the possible combinations available in the user-defined hyperparameter distribution, which is why this method uses brute force.
While this method has the highest chance of providing the most optimized hyperparameter values, it can be extremely computationally expensive and time-consuming, especially if there are many hyperparameters or the dataset is large.
#4. Halving
Halving represents a computationally less expensive approach for discovering the optimal hyperparameter configuration, where it tries multiple combinations of hyperparameters with minimal resources (such as training iterations). It allocates more resources to the hyperparameter configurations, demonstrating the best results to refine the tuning process further.
The two most common halving techniques are as follows-
- Grid Search
In halving grid search, we employ a successive halving approach on a specified list of hyperparameters. Here, we try all possible hyperparameter combinations (configurations) on a small sample of data, selecting the best-performing one to run with larger samples. This iterative process enables us to choose the best combinations, significantly reducing the time consumption.
- Randomized Search
Halving randomized search is similar to halving grid search. Still, it is much more efficient as it doesn’t consider all the hyperparameter configurations but selects the combinations randomly and uses the successive halving approach.
#5. Bayesian Optimization
Bayesian optimization uses a probabilistic model of the machine learning model’s performance based on the various hyperparameter configurations. Here, after one, the next set of hyperparameters is tried based on the probability of their performance.
This is an iterative process that is stopped once the best hyperparameter confirmation is found. This method uses past evaluation results (previous knowledge) and constraints of the hyperparameter values to find the best hyperparameter configuration candidates efficiently. It is, however, much more complex and computationally expensive than others.
#6. Genetic Algorithms
Genetic algorithms can also be used to find optimized hyperparameter values. They use the survival of the fittest concept, where the fittest individual (in this case, the hyperparameter configuration) produces a new generation of candidates. This process is repeated until the strongest, i.e., the most optimized hyperparameter configuration, is found.
Also read: A Complete Guide to Genetic Algorithm
#7. Hyperband
Hyperband employs a bandit-based approach to efficiently searching the hyperparameter space. It conducts bracketed trials, randomly selecting hyperparameter configurations from the space and training models.
Subsequently, these models undergo evaluation based on specific performance metrics like F1 score or accuracy. The least-performing half of the models are discarded while the top-performing models are retained, iterating this process.
This method iteratively narrows down the search for the best hyperparameter configuration. It combines the random search and successive halving strategy, which saves computational resources and time.
There are several other techniques that you should explore, such as
- Sequential Model-Based Optimization (SMBO)
- Tree Prazen Estimators
- Population-based Training (PBT)
- Bayesian Optimization and HyperBand (BOHB)
- Artificial Neural Networks Tuning
Conclusion
Hyperparameters and their optimization (tuning) are crucial aspects of a machine-learning process. The hyperparameters can significantly alter the ML model’s workings, either making it perform exceedingly well or causing it to fail.
Finding the optimal set of hyperparameters can be difficult, and you need to study the algorithm in detail to understand how the various parameters impact the model’s performance.
Once you identify the hyperparameters, discovering the values that yield the best results becomes another challenging task, where various hyperparameter tuning mechanisms come into play. Different mechanisms have pros and cons, and you need to select them based on the problem at hand, the scope of your project, and the availability of resources.
FAQs
- What are examples of hyperparameters?
Different algorithms have different hyperparameters. Some common examples of hyperparameters are the depth of trees (decision trees), the number of trees (random forest), the number of neighbors (KNN), batch size (neural networks), and alpha (lasso regression).
- What do hyperparameters do?
Hyperparameters alter the behavior of ML and DL models. A data science professional can ensure that the ML/DL models fit well with the training data and generalize wells by tuning the hyperparameters. Hyperparameters are the primary way the models can avoid underfitting or overfitting.





