
In one of the articles, we had seen the fundamentals of Machine Learning, and although briefly, but very concisely, we have also seen the types of machine learning and their applications. In this article, let’s try to go further deep into the various machine learning types, the way they are designed, the inputs and outputs involved, different types of algorithm, their application areas, etc. for each of them.
Overview of Machine Learning
Machine Learning is defined as a set of computer algorithms that makes systems autonomously learn and yield outputs and further improve from various analysis and outputs. Data will be fed to these algorithms, by which they automatically get trained to perform a certain task, get a certain output, and hence we can apply that for our real-life business scenarios.
Machine Learning algorithms can be used to solve business problems like Regression, Classification, Forecasting, Clustering, and Associations, etc.

Based on the style and method involved, Machine Learning Algorithms are divided into four major types: Supervised Learning, Unsupervised Learning, Semi-Supervised Learning, and Reinforcement Learning. In the coming sections, let’s drill-down into different types of algorithm.
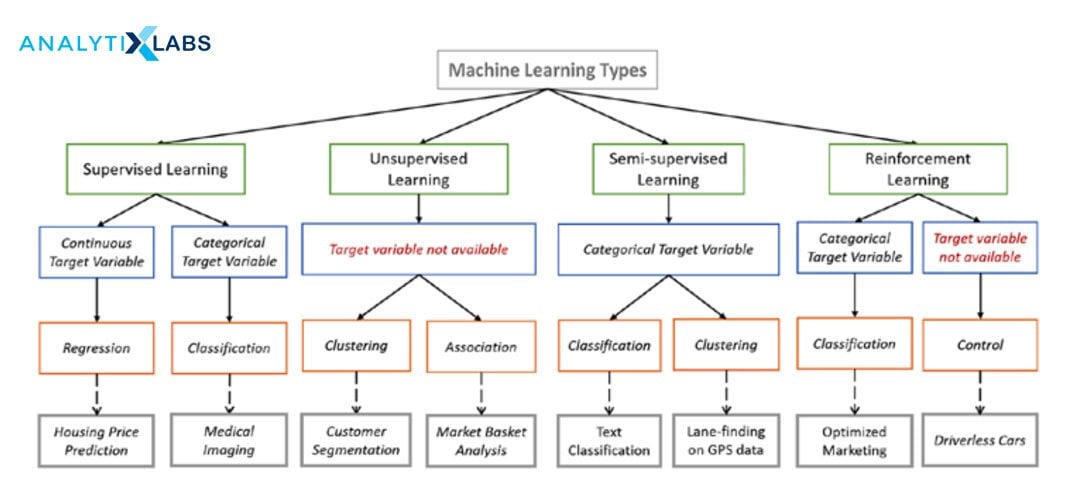
Supervised Learning
Supervised Learning is a method that involves learning using labeled past data and the algorithm shall predict the label for unseen or future data. A supervised machine learning algorithm is actually told what to look for, and so it does until it finds the underlying patterns that yield the expected output to a satisfactory degree of accuracy. In other words, using these prior known outputs, the machine learning algorithm learns from the past data and then generates an equation for the label or the value. This stage is called the training stage.
The learning algorithm tries to modify and improve the above function by comparing its output with the intended, correct outputs and calculate discrepancies and errors, a task which is known as testing. During the next phase which is the implementation phase, it will take in new inputs and will generate the values or determine the label based on the generated equation.
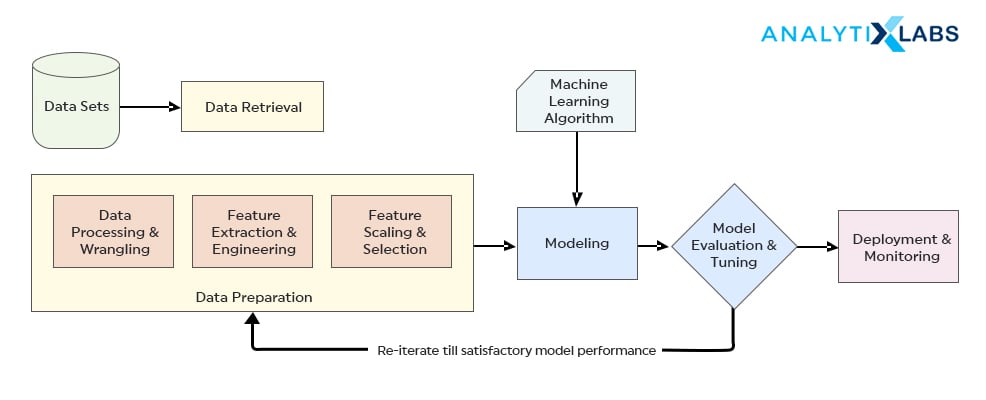
Phases of Supervised Learning
A Supervised Learning algorithm has the following set of tasks – data collection, data preparation, modeling, model evaluation, deployment, and monitoring.
- Data collection or gathering is collecting relevant data required for the supervised learning algorithm. This data can be originated via regular activities like – transactions, demographics, surveys, etc.
- Data Preparation is where we modify and transform the data using the necessary steps. It is highly required to remove unwanted data points and fill-in the inconsistencies in the data. This step ensures accuracy.
- Modeling or training phase where the relationship between label and other variables are established.
- In the Evaluation phase, we check for errors and try to improve the model.
- Deployment and monitoring happen on unseen data, a stage where the model is implemented and prediction outputs are generated.
Business Problems addressed by Supervised Learning
Supervised Learning is primarily used for classification and regression problems.
A classification algorithm aims to determine the pre-defined category of the data. For example, based on certain parameters in an image of a fruit, we can know whether the image contains a tomato or does it contain an apple. For this to work for a presented image, the machine learning algorithm would have been trained earlier on various images of tomatoes and apples, with the user explicitly specifying the vegetable during the training. Hence, for a new image, the algorithm can determine the name of the vegetable. This concept can also be applied for email classification, whether an email should end up in Spam or any of the allowed Inbox categories like General, Social, and Promotions etc.
A Regression algorithm, on the other hand, finds the driving parameters for a numerical value, builds a function and thus, helps in the prediction of that value. For instance, how much should be the selling price of a house, depending on factors such as its location, number of bedrooms, area of the house, amenities, etc. For this to converge, the algorithm is initially trained with data that contains all the information related to the driving factors for the price and most importantly, the price of the house, which is of course known at that point in time. The machine learning algorithm learns the patterns, creates an equation, and then finally it is able to know the price of a newly constructed house for which we know every information except of course the price.
Commonly used Supervised Learning Algorithms
We have seen how supervised learning algorithms can help us predict a value and an event, various forms of supervised learning algorithms are designed to solve those business problems
1. Linear Regression
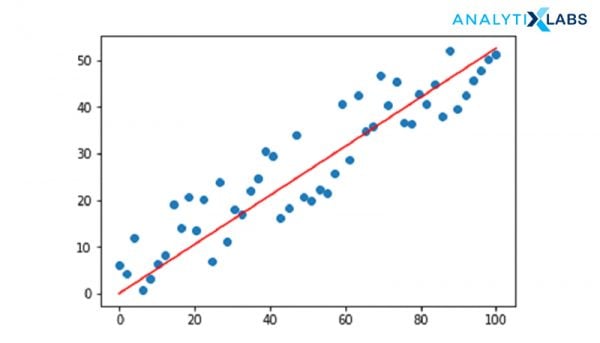
Linear Regression is a Machine Learning algorithm that maps numeric inputs to numeric outputs, by fitting a line into the data points. Simply put, Linear Regression is a way of modeling the relationship between one or more independent variables in a way that they come together to form a driving force for the dependent numerical variable. It is typically identified by the linear equation:
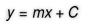
And in business terms for the House Price problem, it looks somewhat like:
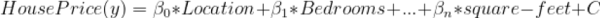
2. Logistic Regression
While Linear Regression typically works for a numerical variable, the Logistic Regression algorithm builds a relationship between variables and a class. It is typically used to predict an event class, where we have a predefined and known category of events. The dependent variable is indeed a categorical variable but the inner working of the Logistic regression algorithm actually transforms the variable by making use of a logit function, which calculates the log odds ratio for the events and hence building a linear equation for the same.
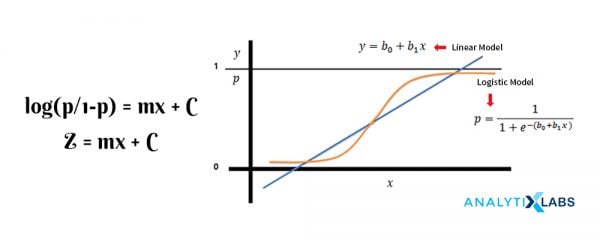
3. Decision Trees
It is a non-parametric supervised learning technique that can be used for both Classification and Regression problems, by identifying suitable methods to split data based on various conditions into a tree-like structure. The end goal is to predict an event or a value by leveraging the obtained conditions.
The tree-like structure is actually a graph where the nodes represent an underlying question about an attribute, the edges which typically contain the answers and the leaves represent the output which as we said earlier, can be a value or a class. Thus, enabling us to predict values and events. The algorithm usually follows a top-down approach, by choosing a variable at each step which can split the next set of data items and usually represented by a metric such as GINI impurity, Information Gain, Variance Reduction, etc. to measure the best approach for splitting.
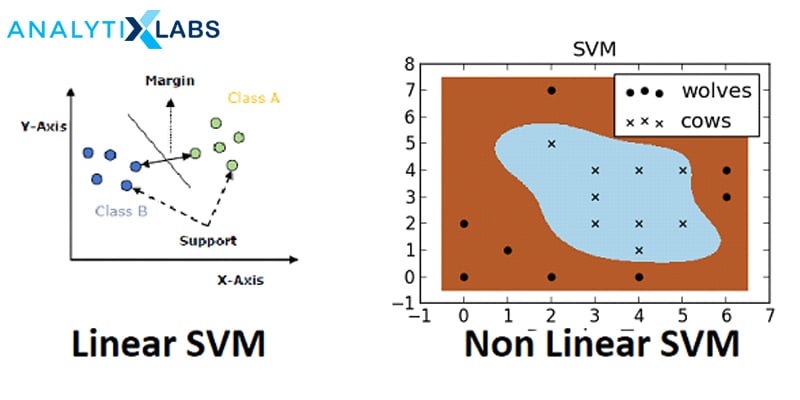
4. Support Vector Machines
This supervised machine learning algorithm is also designed for both classification and regression problems but predominantly used for Classification. It uses a technique which is known as Kernel Trick to transform the data and based on the transformation, it then finds an optimal splitting boundary between the possible outputs. The boundary can be as simple as a linear margin (Linear SVM) for binary classes, to a more complicated splitting which involves multiple classes.
The algorithm represents the classes in a hyperplane in multi-dimensional space and finds the perfect divider for the classes known as a maximum marginal hyperplane. Support Vectors are the data points closest to the hyperplane, which in turn is a decision plane that gets divided, and margin means the gap calculated between the two classes. To learn more about SVM, check out: Introduction To SVM – Support Vector Machine Algorithm in Machine Learning
Other Supervised Machine Learning Algorithms include Random Forests, Artificial Neural Networks, and Naïve Bayes Classification, k-Nearest Neighbors, Linear Discriminant Analysis, etc. Many of the supervised learning algorithms in Python are implemented using the Scikit Learn module and in R it is implemented via the caret package.
Application Areas of Supervised Learning
The typical application areas of supervised learning are
- Image Segmentation – where various image classification actions are performed using image data and pre-identified labels that we are looking for.
- Medical Diagnosis – by making use of medical imagery and past labeled data which contains labels for disease conditions, we can identify a disease for the new patients.
- Fraud Detection – classification algorithms can be used to detect fraud transactions, fraud customers, etc. using historic data to identify the patterns that can lead to possible fraud.
- Spam detection – again, classification algorithms are leveraged to classify an email as safe or as spam.
- Speech Recognition – The algorithm is trained with voice data and various identifications can be done using the same, such as voice-activated passwords, voice commands, etc.
Unsupervised Learning
Unsupervised learning is a type of Machine Learning algorithm that involves training a machine typically using unlabeled data, and that forms the major point of difference with supervised machine learning algorithms which typically use labeled data. In this form of machine learning, we allow the algorithm to self-discover the underlying patterns, similarities, equations, and associations in the data without adding any bias from the users’ end. Although the end result of these is totally unpredictable and cannot be controlled, Unsupervised Learning finds its place is advanced exploratory data analysis and especially, Cluster Analysis.
Unsupervised learning can find the hidden and unknown patterns in the data, and thus helps to find the features that are highly beneficial for auto-categorization of the data. Added to that, it is absolutely easy to get unlabelled data through various sources. For example, in a corpus of text, an unsupervised learning algorithm can get similar patterns and will be able to categorize the texts into various unknown groups – hence helping the user with discovering Topics involved in a text – like, what does a certain review about a product is talking about etc.
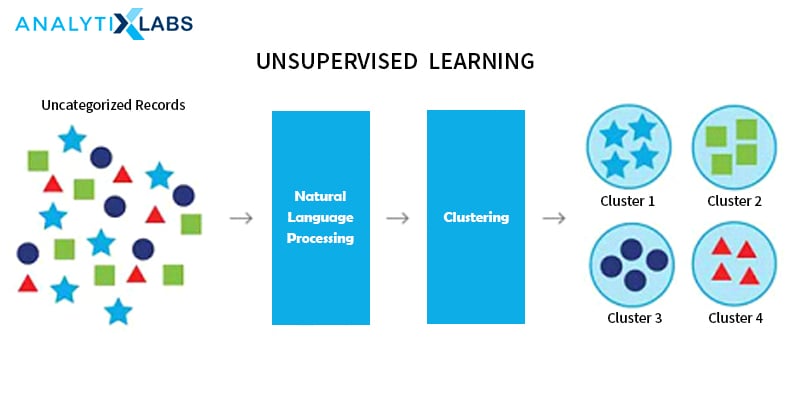
Business Problems addressed by Unsupervised Learning
The biggest contribution of Unsupervised Learning is in improved exploratory data analysis because it helps in finding all kinds of unknown patterns in data. The two major types of business problems that can be addressed by Unsupervised Learning are Clustering and Association Rules. Other problems include Anomaly Detection and Latent Variable Detection.
- Cluster Analysis is the most commonly used unsupervised learning implementation. It is used for fetching unknown and hidden patterns and ambient groups residing inside of the data. Some of the common clustering algorithms are k-Means clustering which partitions data into k distinct clusters based on the distance to the centroid of a cluster, Hierarchical clustering, Gaussian mixture models, Self-organizing maps that make use of neural networks that learn the topology and distribution of the data, Hidden Markov models: uses observed data to recover the sequence of states.
- Association Rules are useful in finding associations in a large set of data and discover correlations and dependencies in data. Usually, this is applied to various transactional data from various industries such as retail, banking, medical, insurance, etc. Few examples of association rule algorithms include the Apriori algorithm, FP-Growth etc.
- Anomaly Detection techniques have the ability to detect unwanted, inconsistent, extreme, and missing data points in the data.
- Latent Variable Models are a set of algorithms that can reduce dimensionality and they are most widely used along with the Clustering Algorithms. Example, Principal Component Analysis, Factor Analysis, etc.
Commonly used Unsupervised Learning Algorithms
Unsupervised learning typically involves similarity and association detections. One distinct observation about this approach is its black-box nature of the operation – where most of the input and output steps cannot be controlled by the user. In this section, let us see the most commonly used algorithms that can solve a plethora of business problems.
1. The k-means Clustering
The k-means clustering is a process that helps to partition the data points or observations into k unknown clusters in such a manner that each observation distinctly belongs to a cluster. This cluster associativity is determined by the proximity of that data point with the nearest mean, otherwise known as cluster centroid. Due to the involvement of proximity measure in the data, various distance algorithms are used in the process to measure the closeness of data to the cluster center.
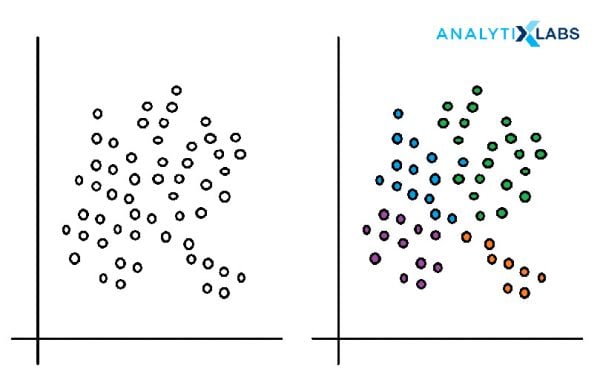
The only and major drawback of k-means is the fact that the algorithm cannot start without the user specifying the required number of clusters apriori. Added to that, there is no mathematical or scientific method to determine the optimal number of clusters. The implementation typically occurs based on the trial and error method, where a set of “K” values are considered initially and the best one is chosen according to the heuristic knowledge.
Despite that drawback, k-means is one of the most simpler, yet powerful algorithms that has been applied to many business cases, like Customer Segmentation, Image Segmentation, Text Segmentation, etc.
2. DBSCAN Clustering
k-means Clustering employs an approach which is known as Centroid based clustering and on the contrary there are approaches to clustering which make use of density as a factor to differentiate the data points. A typical implementation of such a process can be seen in DBSCAN.
There are two major underlying concepts in Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm – one, Density Reachability and second, Density Connectivity. This helps the algorithm to differentiate and separate regions with varying degrees of density – hence creating clusters.
For implementing DBSCAN, we first begin with defining two important parameters – a radius parameter eps (ϵ) and a minimum number of points within the radius (m).
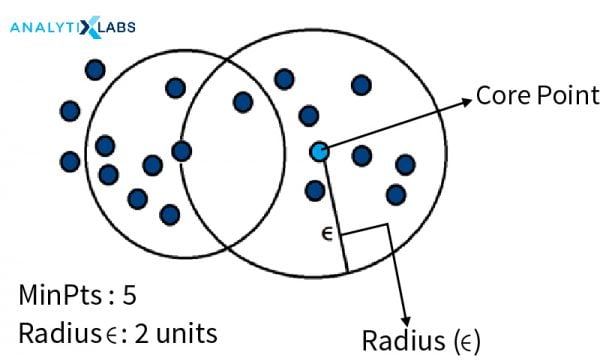
a. The algorithm starts with a random data point that has not been accessed before and its neighborhood is marked according to ϵ.
b. If this contains all the m minimum points, then cluster formation begins – hence marking it as “visited” – if not, then it is labeled as “noise” for that iteration, which can get changed later.
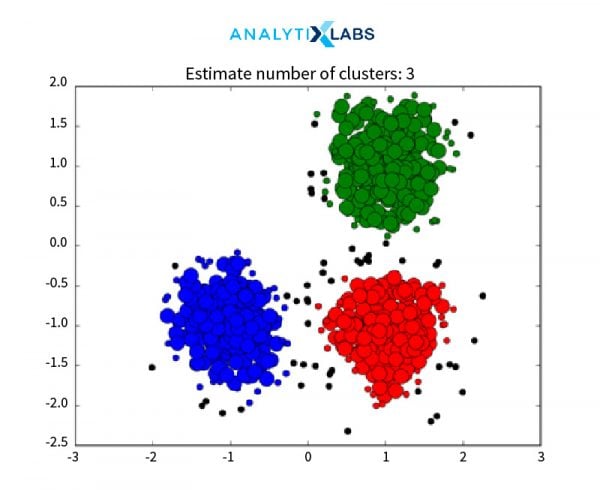
c. If a next data point belongs to this cluster, then subsequently the ϵ neighborhood now around this point becomes a part of the cluster formed in the previous step. This step is repeated until there are no more data points that can follow Density Reachability and Density Connectivity.
d. Once this loop is exited, it moves to the next “unvisited” data point and creates further clusters or noise.
e. The algorithm converges when there are no more unvisited data points remain.
3. Principal Component Analysis
PCA is a dimensionality reduction algorithm that is useful to reduce the number of variables in a huge dataset – by transforming a group of variables into one larger variable, and at the same time, retaining the original characteristics of that set of variables. All of these processes happen with minimal or next to zero information loss, although, there is always a risk of loss in the accuracy of the data. Hence, PCA is mostly used in conjunction with Unsupervised Learning although it also has good applications with Linear Regression.
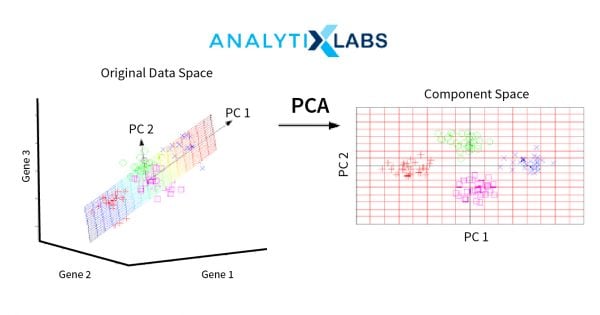
As stated previously, a set of variables are grouped together into a single unit which is known as Principal Components (PCs). They’re orthogonal, a linear combination of the variables, the weights of which are defined using an eigenvector. PCA finds its use in business that has high dimensional data involved like Finance, Bio-informatics, Psychology, Image Processing, etc.
4. Association Rules
Association rules are generally a set of conditional statements that help to show the relationships between data items within large data sets generated in various business scenarios. Association rule is widely used to help discover correlations in transactional data. So, for a given set of transactions, Association rules can help to find rules that will predict the occurrence of an item based on the occurrences of other items in the transaction. The typical terms used in the algorithm are Support, Confidence and Lift.
Support quantifies the frequency of a certain collection of data items within a transaction as a ratio of total transactions. Confidence is the number of times a condition evaluated to True. The lift measures the performance of a rule in terms of its predictive power.
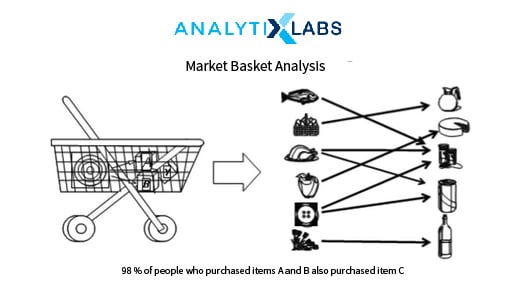
Association Rules are useful in analyzing typical retail related data, for example, the data collected using bar-code scanners in supermarkets, or data generated via transactions in an e-commerce website, etc. This data typically comprises numerous transaction records. Eventually, we can mine various patterns such as certain groups of items are consistently purchased together, similar items to the items that one is viewing, etc. This in turn helps in appropriate placement of the items on the website or inside of a physical establishment.
Application Areas of Unsupervised Learning
The key application area of Unsupervised Learning is all about “advanced” exploratory data analysis. One can see that being applied on various domains and data.
- Network Analysis: Used in document Network Analysis of text data for identifying plagiarism and copyrights in various scientific documents and scholarly articles.
- Recommendation Systems: Widely used in recommendation systems for various web applications and e-Commerce websites.
- X-ray Crystallography: Used to categorize the protein structure of a certain protein and to determine its interactions with other proteins in the strands.
- Social Sciences: Clustering in Social Network Analysis is implemented by DBSCAN where objects (points) are clustered based on object’s linkage rather than similarity.
- Search Engine: where objects that are similar to each other must be presented together and dissimilar objects should be ignored. Also, it is required to fetch objects that are closely related to a search term, if not completely related.
Reinforcement Learning
Reinforcement Learning is a subset of machine learning that enables a component of the system, called agent, to learn in a simulated, interactive virtual environment by trial and error, reinforcing the results using a reward-punishment system that is generated using feedback from its own actions and experiences.
This method sounds really close and similar to Supervised Learning but there is one major difference between them that sets them apart. We have seen how in a supervised machine learning algorithm, the program knows the answers and accordingly it designs patterns and creates a model. In Reinforcement Learning, however, there are no predefined labels. It operates inside of a virtual environment, which is supplemented by a set of rewards for correct answers and a set of punishments for incorrect answers. The goal of the algorithm is ultimately to maximize the rewards for the software generated agent.
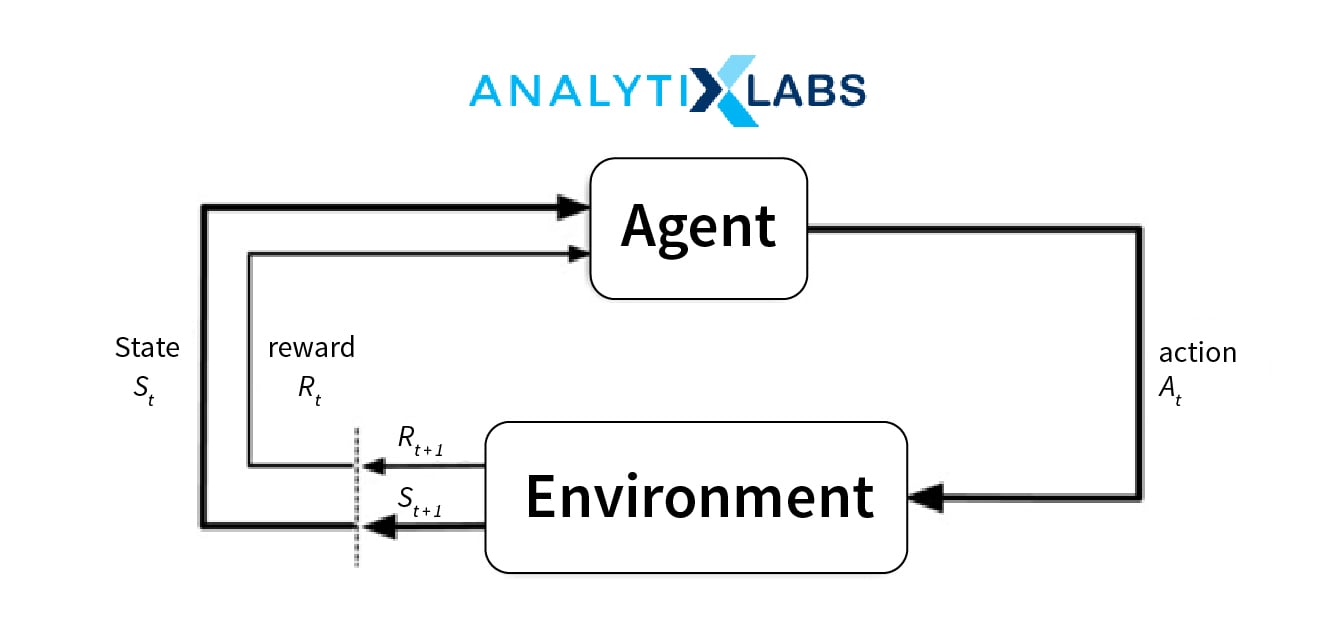
In other words, an agent “learns” from the results of its actions in the virtual environment, rather than being explicitly presented with the correct outputs (Supervised). It then selects the best course of action on basis of past experiences (exploitation) and also by new choices (exploration), which is essentially carried out by trial and error learning.
Now, this trial and error need an indicator to prove whether it is correct or not, and that is provided by a reinforcement signal. This signal is in for of a reward, which denotes the success of an action’s outcome. And of course, the end goal is to maximize this reward.
In RL, we use the following components – environment, state, reward, policy and value. The major challenge that we can face when implementing these algorithms lies in the design of the correct environment – which is, in turn highly reliant on the type of business problem being addressed.
Furthermore, the challenges continue because the virtual environment so defined should be correctly translated into the real-life scenario. If these problems are addressed, Reinforcement Learning can be highly pivotal in solving various business problems that are discussed in the next section.
Business Problems addressed by Reinforcement Learning
In many industrial applications, emulated agents are being created to perform the tasks instead of a human in order to minimize errors or most important, reduce risks to human life. These agents have proven to be an inseparable part of major businesses like manufacturing, metallurgy, finance, etc. Some of the business problems addressed by reinforcement learning are:
- Automation refers to a set of processes and methodologies which enable a task to be performed by having minimal or zero human interference. While various methods are employed to achieve automation, machine learning using reinforcement learning algorithms is one of the most rewarding approaches to implement automation across various industries. Automation can be applied to various functions within the industry like installation, operations, maintenance, design, procurement, and management.
- Optimization is a procedure in that finds an optimal solution to a problem by iteratively executing and comparing solutions until a satisfactory solution is found. They can be Deterministic, which makes use of predefined set rules for navigating from one solution to another and Stochastic, where the transitional rules make use of a probability-based score to find the best move from one solution to another.
Commonly used Algorithms for Reinforcement Learning
Some of the most widely used RL algorithms are Q-Learning, State-Action-Reward-State-Action (SARSA), Deep Q Network (DQN), Deep Deterministic Policy Gradient (DDPG), etc.
Q-Learning
This is one of the simplest and most widely used reinforcements learning algorithms. Q-learning aims to find the best possible action to be taken at a given machine state. It follows an approach which is known as Off-policy learning, because it learns from actions that may not be a part of current policy definitions, without compromising on the end goal, i.e., maximizing the reward policy for a software agent. The Q stands for Quality – which denotes the usefulness of a given action in gaining a reward in the future. Q-Values are defined for all states and actions which will be iteratively computed using the Temporal Difference – Update rule.

Rewards and Episodes determine the transition from one state to another and thus quantifying the efficiency of a transition for a given action. The reward is defined as the value that is assigned after completing a certain action at a given state and it can be done at a given step or after the completion of a major action.
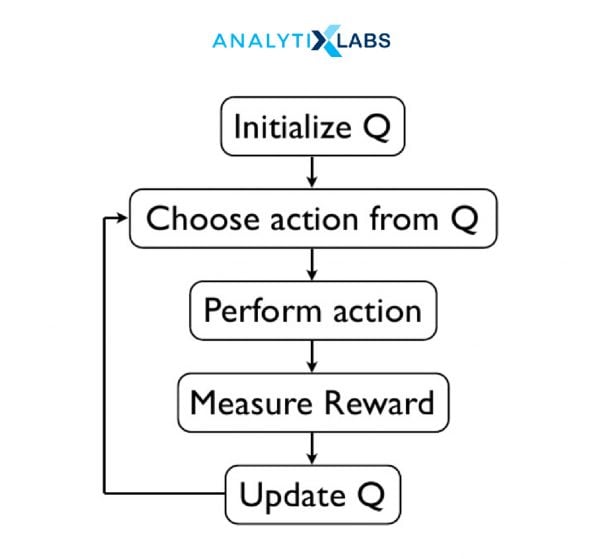
Temporal Difference or TD-Update is a process where q-values are adjusted based on the difference between the discounted new values and old values. The new values are discounted using gamma and the step size is adjusted using the learning rate
State-Action-Reward-State-Action (SARSA)
It is an algorithm for learning a Markov decision process policy. The learning begins at a state, let’s say state S1 where a certain action, say A1 is taken. As we know in reinforcement learning, after completion of every action, a reward is assigned to that action. So, for A1, let’s say a reward R is given to the agent for performing that action. Once this is done, the agent transfers to a new stage S2 which shall be followed by an action A2. This process is a combination set of State S1, Action A1 which gets a reward R, followed by State S2 and action A2, hence the acronym SARSA.
This algorithm overfits to current states and removes any old experiences so that when it encounters a state-space that an agent has not visited recently, the algorithm will relearn. This makes it more efficient. Different forms of linear function approximations, like linear programming, could be used to further improve the selection and control the overfit.
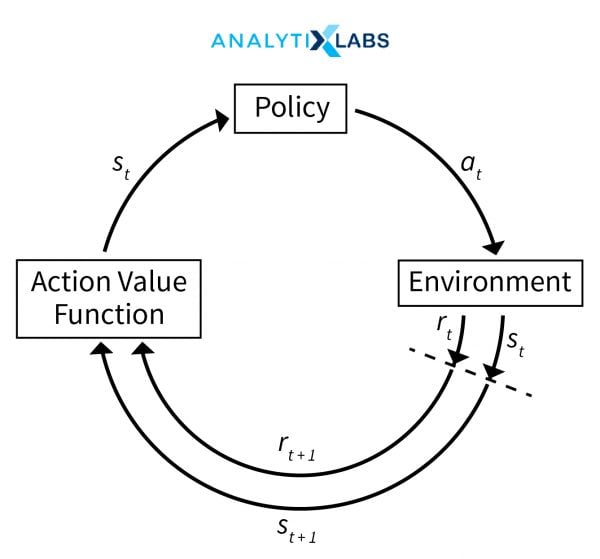
Applications of Reinforcement Learning
Reinforcement Learning is best used in cases where the application scenario is known, along with the best possible as well as unwanted outcomes but it is impossible to build any feasible mathematical model using supervised learning nor finding similarities can help solve any problems. Some of the best application of Reinforcement Learning are:
- Dynamic Pricing – a method by which prices are adjusted based on supply and demand, so as to maximize the revenue and sales. Q-learning is majorly used for pricing models.
- Industrial Automation using Robotics
- Advanced training and learning environment in academics and vocational training like pilot training, train driver simulations, etc.
- Gaming Solutions and logic, where most of the in-game logic can be defined using reinforcement learning.
- Optimizing Delivery routes and finding the best possible routes for last point delivery.
- Financial investment decisions for finding out the best possible trading strategies.
Influence of Various Algorithms on Machine Learning
We have seen what Machine Learning is, the different types of Machine Learning algorithms, and some of the commonly used algorithms in the industry. Let’s look into their collective drive on the Machine Learning process and see how they help in the basic functioning of Machine Learning. Various functions in industry generate various varieties of data, various forms of data, numerous levels of data, and different sizes and structures of data.
This data needs to be tamed! In the sense, that the data thus generated needs to be put to a beneficial use instead of letting it go in vain. Various methods to do so are finding patterns, finding hidden similarities, finding associations, optimizations, simulations, generating derived data, etc.
Finding patterns in data can answer a lot of questions about an event or value, like which transaction is most likely to be fraudulent, whether an incoming tweet is said in a positive sense or a negative sense, why are many employees quitting the company, or in the next five weeks, what could be my Weekly Sales or how much spend is expected by a customer who uses a credit card.
The above questions can be answered by Classification and Forecasting problems. Both of them can be implemented using Supervised Learning. Linear Regression, Logistic Regression, Support Vectors, Random Forest, Decision Trees, K-Nearest Neighbors as discussed in the previous sections, are of great importance for these business problems.
While finding patterns involves building a model – which is basically an approach where we feed the machine with “correct” answers, on various occasions we need to find the hidden similarities in the data. This can include finding similar regions in an image, getting Customers together into buckets that follow certain hidden closeness, finding associated items from the list of transactions – so that we can know what items are similar to each other or what items are purchased along with the current item, etc. Unsupervised Learning provides a feasible solution to the above problems. As discussed earlier, some of the important unsupervised algorithms include k-means, k-medians, Fuzzy C Means, DBSCAN, AGNES, ARules, and Collaborative Filtering, etc.
Moving aside the above industry scenarios where abundant data and even sometimes, adequately labeled data is available to build models to solve business problems, there are certain aspects where either the given data is so minimal and run-of-the-mill that getting a mathematical function is not possible. In these scenarios, we can create a simulated environment and find correct or wrong answers by providing a reward system and we have seen that this class of algorithms is known as Reinforcement Learning. This can be a boon for applications like dynamic optimization of flight fares, gaming decisions by auto players, taking trade decisions, robotics, etc.
We can utilize and harness powerful tools like Python and R to implement various types of machine learning algorithms to make the most out of the data. In modern times, machine learning using Python and machine learning in R has become much popular due to various packages available for implementation in both the languages for implementing classification, regression, and clustering and reinforcement learning, etc. Apart from that, we can also integrate these models into various end-user applications.
You may also like to read:
1. How to Choose The Best Algorithm for Your Applied AI & ML Solution
2. Machine Learning vs Deep learning- What Is the Difference?





