
Machine learning is a vast field of study that has allowed us to solve highly complex problems. One needs to know about many fields to master machine learning. These include knowledge of various algorithms, model evaluation, validation methods, and the various learning setups in which the models function.
- Get started with Machine Learning: Why Should You Learn Machine Learning?
This article will discuss supervised and unsupervised machine learning – the two most prominent learning setups. The discussion will include their definitions, types, examples, applications, and exploring supervised vs. unsupervised learning.
- For more detailed industry insights: Data Science Bible Report 2023
However, before you learn about them in particular, let’s first understand what learning steups are and their various types.
Types of Learning Setups
Any machine learning model aims to ‘learn’ from the data to produce outputs to solve complex business problems. This ‘learning’ can happen through various techniques known as learning setups.
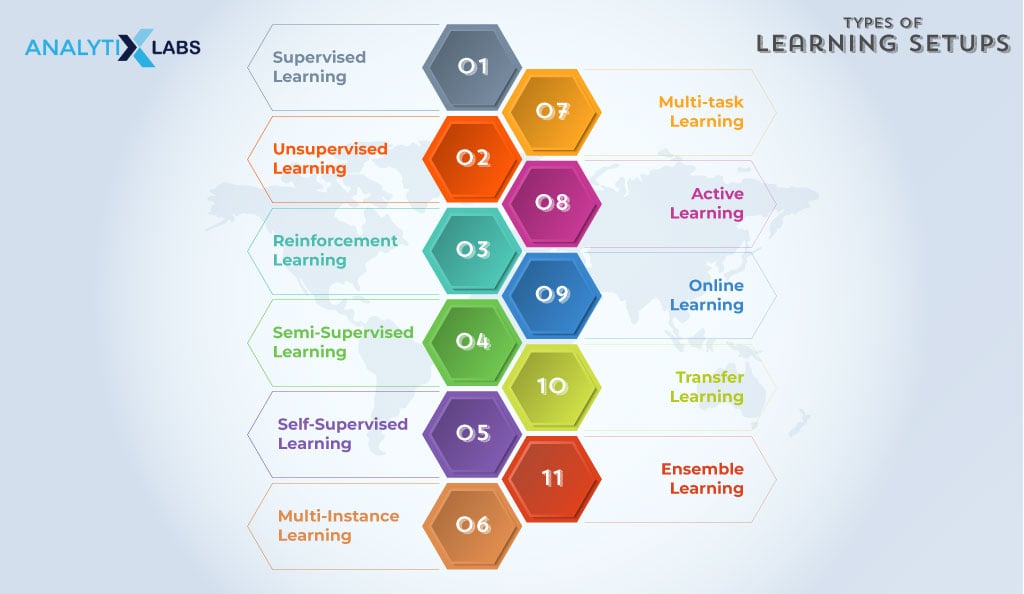
While there are over a dozen learning setups, it isn’t easy to discuss them all here. A few of the most prominent types of learning steps that you should be aware of are the following-
Supervised Learning
Supervised machine learning is a setup where the model ‘learns’ by mapping the input features (independent features) and the target (the dependent variable). An algorithm maps the relationship between the input features (x variables) and the target variable (y variable).
Unsupervised Learning
When understanding learning setups, you often focus on supervised vs. unsupervised learning, as unsupervised learning is the second major type of learning setup. Here, there is no y variable available. Thus, the algorithm working in such a learning setup operates only on the x variables, looking for patterns in the data to ascertain groups or associations.
Reinforcement Learning
It’s learning commonly used by deep neural networks. While it looks similar to supervised learning, it’s different as a feedback mechanism is introduced in such a setup, making the model improve with each iteration.
Semi-Supervised Learning
Semi-supervised learning can take many shapes and forms. It typically uses supervised and unsupervised machine learning and is considered a hybrid technique. It works by leveraging the unsupervised learning techniques to label data and then using the supervised learning techniques to map the relationship between the input and the plausible ground truth.
Self-Supervised Learning
Such a learning setup doesn’t require labels but still approaches the problem like it would in a supervised learning setup. Here, a supervised learning algorithm is used, but it solves an alternative task as the labels aren’t available. The output is then used to solve the actual problem. A common example of self-supervised learning includes-
- Computer vision – making images colorful or grayscale
- Autoencoder – making image compressed to reduce the size
- Generative Adversarial Networks – making synthetic photographs using a collection of unrelated images
Multi-Instance Learning
In this learning setup, we use supervised learning with a distinction: instead of assigning labels to individual samples, we assign labels to bags (groups) of samples.
This technique typically involves multiclass learning, associating each bag with a unique class, and determining the relationship of the samples within the bag with the associated class during the learning process.
Unlike a typical multiclass supervised learning setup, a bag can have duplicate samples with the same label.
Multi-task Learning
It is a simultaneous learning setup for implementing neural networks for tasks like NLP and voice recognition.
Active Learning
Implementing supervised learning actively requires maintaining a heightened awareness of the model’s utilized data, proactively removing unwanted data, and enhancing processing speed compared to the ‘passive’ approach of supervised learning.
Online Learning
Online Learning, a newer approach, contrasts with traditional setups that use a batch of data for offline machine learning. In this setup, we stream data and update estimates with the arrival of each new data point.
Observers can see supervised and unsupervised learning in data mining applications working in such a setup where we constantly mine data in real-time.
Transfer Learning
An interesting learning technique in the field of artificial intelligence is Transfer Learning. Here, a model is trained for a task and then used as a starting point for performing other tasks.
For example, an image classification model based on CNN can be trained on a big corpus of general images. The weights of such a network can then form a starting point to classify specific images, e.g., differentiating apples from oranges.
Also read: Convolutional Neural Networks- Definition, types, and more
Ensemble Learning
Lastly, ensemble learning techniques can also be used, as many learning techniques can be combined to solve peculiar problems. Examples of algorithms working under such a setup include bootstrap aggregation (bagging), boosting, stacked generalization (stacking), etc.
Before we proceed to understand the types, processes, and examples of supervised and unsupervised learning, important note ⬇️
With the increasing technological advancements in AI, having a firm grip on the concepts of machine and deep learning has become a basic need. AnalytixLabs can be your starting point here. Whether you are a new graduate or a working professional, we have machine learning and deep learning courses with syllabi relevant to you. Explore our signature data science courses and join us for experiential learning that will transform your career. We have elaborate courses on AI, ML engineering, and business analytics. Engage in a learning module that fits your needs – classroom, online, and blended eLearning. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
As you would have noticed from the discussion, the two major types of learning techniques are supervised and unsupervised, with all other learning techniques only being based on these two. So, you must have a greater knowledge of these two learning techniques.
Let’s start by answering what supervised learning is.
Supervised learning
A supervised learning setup is where a machine learning algorithm maps the relationship between the independent input features and the target-dependent variable.
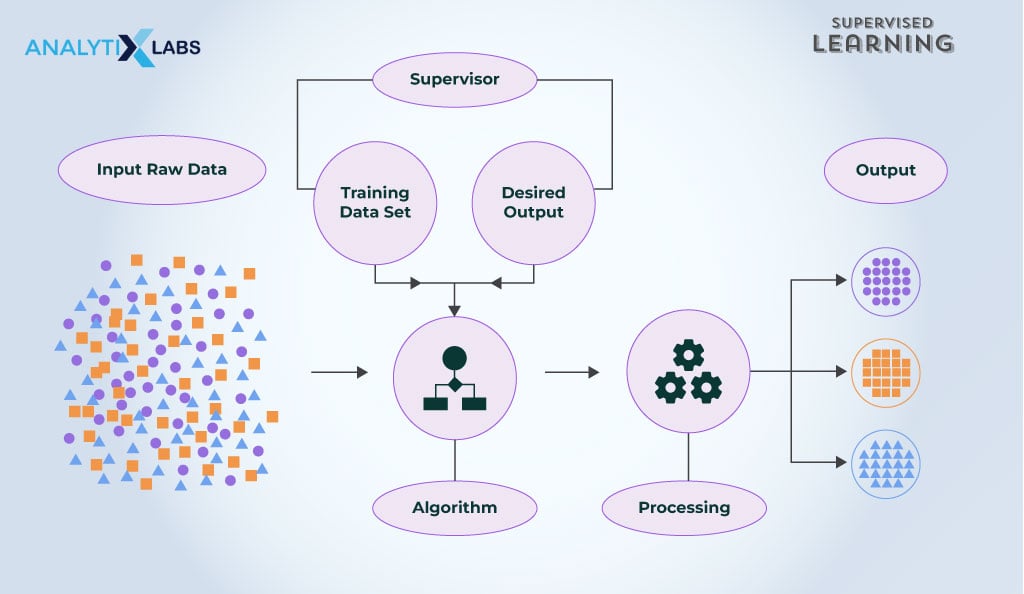
The dependent variable is labeled that ‘supervises’ the algorithm to make its predictions more accurate by tuning the hyper-parameters or identifying the correct value of coefficients.
Let’s explore a few important aspects of supervised learning.
Process
The typical process for performing supervised learning in machine learning is the following.
- Collect Data
The first step is to collect data. The labeled target variable, i.e., the values the model must predict given a set of predictors (independent input features), must be present in the collected data.
- Train Model
The next step is to split the data into train and test. The training data fits the model, while the testing data serves as unseen data for implementing the model and evaluating its performance.
- Evaluate Model
Once the model scores the testing data, it is evaluated on multiple parameters. Evaluation is particularly easy in supervised learning as the expected and predicted labels are both available, and you can compare them to evaluate the model performance. Other factors, such as overfitting, are also considered at this stage.
Typically, hyperparameter tuning involves data splitting into training, test, and validation sets and utilizing cross-validation methods. Alternative algorithms are explored if a model performs poorly with a specific algorithm.
- Deploy Model
Once the desired performance from a model is achieved, the model is deployed to use the unseen unlabeled data and solve real-world problems.
- Model Monitoring
Once the ground truth is available for unseen data, the model’s performance is evaluated to ensure its relevance or identify degradation, necessitating retraining. This monitoring occurs regularly.
Types of Supervised Learning
The backbone of a supervised learning setup is the availability of a well-labeled dependent variable. The type of supervised learning and the choice of algorithm heavily depend on the dependent variable you are dealing with.
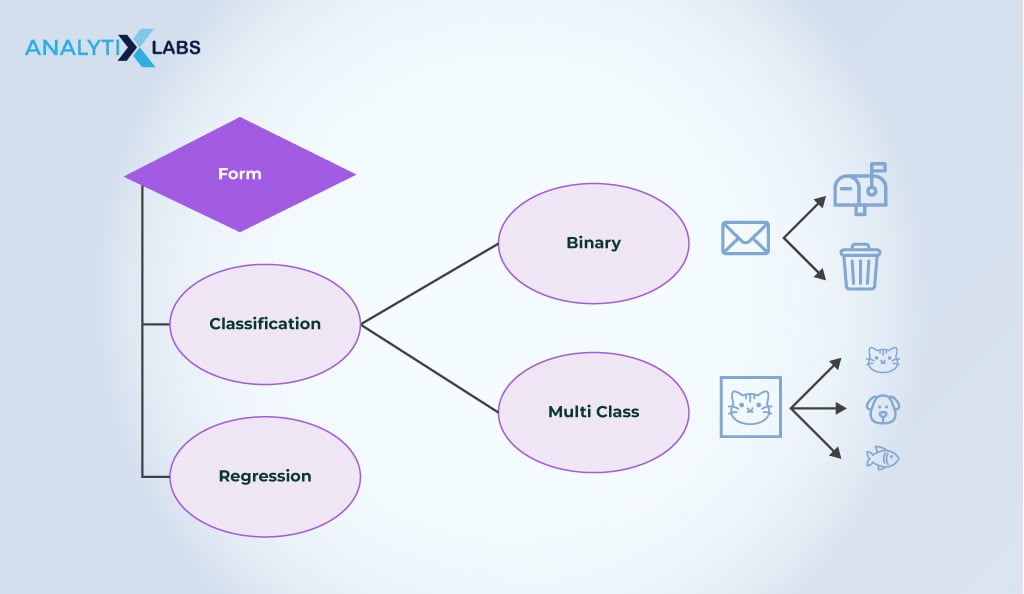
Regression and classification are the two types of supervised learning, and each has certain associated algorithms.
1) Regression
Regression is a type of problem that can be solved through supervised learning. Here, the dependent variable is a continuous numeric variable.
As the target is numeric in regression problems, evaluation involves assessing the magnitude of the difference between actual and predicted values. Common metrics include R-squared (coefficient of determination), Adjusted R-squared, and MAPE (mean absolute percentage error).
The common supervised learning algorithms for solving regression problems are linear regression, regression trees, non-linear regression, bayesian linear regression, polynomial regression, gaussian process regression, SVM regression, and decision tree regressor.
2) Classification
The next type of supervised learning is classification, where the dependent variable has categories/classes. If the y variable has two classes, it’s a binary class problem; if more than two, it’s a multi-class problem.
Binary examples include yes-no or Male-Female, while multiclass involve categories like movie genres or types of animals. Evaluating classification
models is tricky as actual and predicted labels may or may not match, with no ascertainable ‘magnitude of difference.’
Also read: How Univariate Analysis helps in Understanding Data?
While one can count the number of instances where the labels match, it comes up with limitations and challenges. The common evaluation metrics used for evaluating and solving classification problems are accuracy, sensitivity, specificity, f1 score, AUC score, lift, etc.
The common supervised learning algorithms for solving classification problems are logistic regression, random forest, decision trees, support vector machines, k nearest neighbor, naïve Bayes, discriminant analysis, etc.
Also read: What is Classification Algorithm in Machine Learning?
Advantages of Supervised Learning
There are certain major advantages of supervised learning in machine learning. Some of them are the following-
- Use Prior Experience
Typically, historical data is considered for training a model in the supervised learning setup. For example, suppose you’ve had loan defaulters in the past. In that case, you can take the historical data and map the credentials and demographic details of the loan applicants with their loan repayment outcomes.
This way, the prior experience of a financial institution can make them accurately predict the outcome of the upcoming loan applicants.
- Know classes
A big advantage of supervised learning is knowing exactly what you are trying to predict as you are already aware of the classes. This, in turn, helps in removing the uncertainty of what the model output would be.
- Easy Evaluation
Evaluating models in supervised learning is straightforward because both the expected and predicted values are available, enabling easy assessment of a model’s performance through comparison.
This capability of performance evaluation allows for other techniques, such as hyper-parameter tuning, to function in supervised learning that can exponentially increase the predictive capability of a model.
- Solve Real World Problems
Common real-world problems are solved using supervised machine learning as often we know what we are looking for and want to be answered based on a given set of inputs.
Disadvantages of Supervised Learning
The supervised learning setup comes with its own set of disadvantages, too. These include the following-
- Difficult for solving complex tasks
While many real-world problems can be solved under supervised learning, complex tasks are typically difficult.
- Dissimilarity between training and serving data
The model trains on a specific set of input features in supervised learning. The model, therefore, needs to have the same features in the serving dataset if it has to produce output.
Any dissimilarity in features can render the model useless, and ensuring this is becoming increasingly difficult in the shifting real-world landscape where certain information might not be available due to technological, political, regulatory, ethical, or other reasons.
- Computation Cost
As the algorithms map the input and the target, the computation cost of training a model in supervised learning is high.
- Knowledge of Labels
Lastly, the essential supervised learning component is knowing classes, i.e., the labeled dependent variable.
Performing supervised learning is impossible without labeled data. Labeling data is often challenging, requiring manual efforts, making it a time-consuming, labor-intensive, and costly process, limiting the applicability of supervised learning.
Examples of Supervised Learning
The examples of supervised learning revolve around regression and classification problems. These problems can further have their subtypes.
- Image Classification
It’s a common classification problem where the input is the image, and the objective is to classify it. A common example would be to distinguish between the image of a cat and a dog.
Also read: What is Image Segmentation?
- Sentiment Analysis
A classification problem can be assessing the sentiment of customers. A common application of supervised learning is with natural language processing.
For example, a user leaves a product review on an e-commerce website where they can click on the ‘thumbs up’ or ‘thumbs down’ option that acts as the satisfied or dissatisfied label, and the detailed comment of the user acts as the input.
Based on user comments, a model can be trained to understand whether the customer was satisfied.
Also read: How To Perform Twitter Sentiment Analysis – Tools And Techniques
- Risk or Value Assessment
The common example of supervised learning is whenever a value or risk is to be estimated. This can include assessing the repaying capacity of an individual, the monetary value of an object or person, etc.
Real-Life Applications of Supervised Learning
There are numerous real-life applications of supervised learning. Supervised learning can be leveraged for any business problem where the labels are available and must be predicted. Common application areas include-
- House Price Prediction
In a regression problem, the task is to estimate the house price by analyzing various aspects like square footage, amenities, room count, construction type, locality, and proximity to important sites based on the pricing of similar houses.
- Weather Forecast
Different parameters affecting weather can be considered as inputs to estimate weather. These can include considering historical data on temperature, precipitation, humidity, wind, etc. Based on them, the weather can be classified as sunny, rainy, humid, etc.
Hopefully, now you have an informative answer to the question – what is supervised learning? The discussion above on supervised learning pointed to its several limitations. Its disadvantages are mainly addressed by another major type of learning – unsupervised learning. Let’s now discuss it.
Unsupervised learning
An unsupervised learning setup is where the labeled dependent variable is unavailable; hence, the model has nothing for supervision, and what needs to be predicted is not certain.
Therefore, a model in an unsupervised learning setup works with the independent variables to find hidden patterns and insights about the data.
The patterns are found by assessing the underlying structure of data, the similarity between different data points, and processing data in different dimensions.
Let’s look at the various aspects of unsupervised learning.
Process
The process followed in unsupervised learning differs from supervised learning in various ways.
- Collect Data
The data collected here is without labels. While the data can be split into training and testing, it doesn’t have the same purpose as supervised learning.
- Train Model
The model is trained by finding hidden patterns in the data. The algorithm is selected based on the kind of data and the initiative’s goal.
- Evaluate Model
Model evaluation is difficult. While the elbow method can help find the right model and its optimum configurations in clustering problems, evaluating the results requires human intervention. It involves understanding and determining if the characteristics of clusters or associations make sense.
- Deploy Model
The model can generate labels for supervised learning. In the case of an association or dimensionality reduction models, they can be deployed in real-time to address various problems.
- Validate Model
Model validation typically takes place on user feedback, the effectiveness of the initiative, etc.
Types of Unsupervised Learning
The unsupervised learning setup has three types- clustering, association, and dimensionality reduction.
1) Clustering
In clustering, the data is analyzed to find hidden patterns, and based on the similarity of the data point, the samples are clustered into groups. There are various ways of clustering, such as exclusive, agglomerative, overlapping, probabilistic, etc. Various algorithms can solve clustering problems, such as K-means, Fuzzy K-means, Gaussian Mixture Models, Hierarchical clustering, and DBSCAN.
Also read: What is Clustering in Machine Learning: Types and Methods
2) Association Rules
Researchers use unsupervised learning called ‘association rules’ to discover relationships between different features or data points. Whenever recommender engines are needed, they create models based on association rules. The common algorithms in this category include the apriori algorithm, frequent pattern growth algorithm, etc.
3) Dimensionality Reduction
Another type of unsupervised learning is dimensionality reduction. In dimensionality reduction, we identify the similarity between features to compress them, leading to a reduction in the dimensions of the data, unlike clustering, which finds the similarity of the rows (data points) to group them. Common algorithms include principal components analysis, independent component analysis, etc.
Advantages of Unsupervised Learning
There are several advantages of unsupervised learning. These include-
- Unavailability of Label
There is no dependence on the need for data to have often difficult and expensive labels.
- Easy Data Availability
Unlabelled data is easily available. Thus, the data required for performing unsupervised learning is readily available.
- Complex Tasks
Complex tasks can be easily performed in an unsupervised learning setup. It’s because labels aren’t readily available when solving complex real-life tasks.
- Easy works with Raw Dataset
Algorithms in supervised learning setup require a lot of data cleaning, assumptions to be fulfilled, etc., so the mapping of x and y variables can happen. This makes working with raw data difficult, which is not the case with unsupervised learning.
- Work in Real-time
While supervised learning can also be performed using streaming data, it is much easier in unsupervised learning.
- Cost-effective
It’s much more cost-effective to run a supervised learning setup than supervised learning, as no complex mapping needs to occur here.
Disadvantages of Unsupervised Learning
There are severe disadvantages of unsupervised learning that you must also remember. These include-
- Intrinsically Difficult
There are no labels, so it’s intrinsically difficult to understand and work with unsupervised learning algorithms’ workings.
- Less Accurate and Unpredictable
As there is nothing to supervise, the accuracy and reliability of model output in unsupervised learning are severely compromised. There is always some uncertainty about what to expect from the model.
- Requires Validation of humans
The lack of labels means there is no straightforward mathematical equation to evaluate the output of the models working in an unsupervised learning setup. Therefore, the model needs to be typically validated by humans where, for example, in the case of clustering, the characteristics of clusters are analyzed to see if they make any sense. This need for human intervention causes a lack of consistency in evaluating unsupervised models, creating a big issue.
Examples of Unsupervised Learning
Numerous examples showcase the understanding and appreciation of unsupervised learning.
- Segmentation
The primary example of unsupervised learning is segmentation, where clustering algorithms group similar data points together. Segmentation has multiple real-life examples that will be discussed later.
- Anomaly Detection
Anomaly detection is another unsupervised learning example. Here, clusters are formed based on density, and data points unusually distant from the dense cluster region are identified and treated as anomalies.
Also read: Ultimate Guide To Anomaly Detection- Definition, and more
- Feature Extraction
The curse of dimensionality and the problem of multicollinearity are all issues that arise from having a lot of features in the data. Unsupervised learning can reduce dimensionality, where information of similar features can be combined and represented in a lower dimension.
- Recommendations
Today, you are constantly bombarded with recommendations, from buying products on E-commerce websites to typing anything on your mobile. Recommendations can be generated using association algorithms, and this is one of the most prominent examples of unsupervised learning.
Real-Life Applications of Unsupervised Learning
The real-life applications of unsupervised learning stem from its different types, viz. clustering, association, and dimensionality reduction.
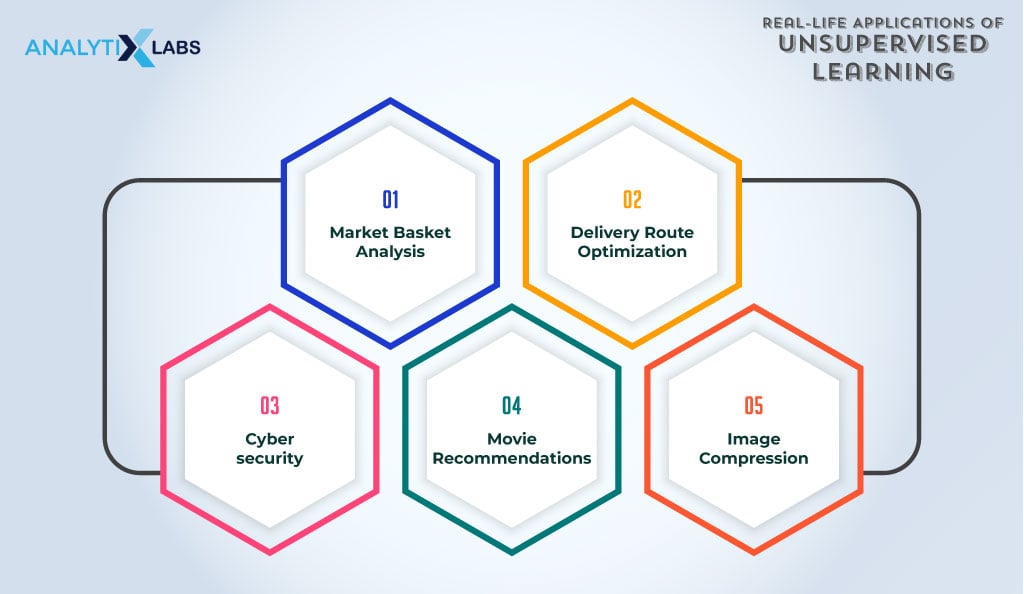
Following are a few of the most prominent applications of unsupervised learning-
-
Market Basket Analysis
Retailers use market basket analysis to understand purchasing patterns. In this process, they analyze customer transaction data through clustering. They assign a description to each cluster, making discount offerings and cross-selling accordingly.
-
Delivery Route Optimization
Route optimization can also leverage clustering to enhance efficiency. Grouping stops with similar characteristics reduces travel time and eliminates unnecessary detours.
For instance, when packages need delivery in a city, applying clustering groups of similar stops to formulate a strategic route minimizes the distance traveled.
-
Cyber security
Cybersecurity utilizes the concept of anomaly detection. For instance, algorithms like DSCAN perform density-based clustering to identify fraud transactions.
The bank can deem any data point unusually far from a cluster as anomalous, prompting them to alert the customer and implement preventive measures against fraud. Similarly, computer networks apply similar principles to detect and address unusual activities, enhancing cybersecurity.
Also read: Roadmap to Becoming a Cyber Security Expert in India in 2024
Cyber Security Salary 2022 – India Edition
What is Cybersecurity? Importance, Types, Challenges, and Course
-
Movie Recommendations
The association rules recommend movies to a user active on an OTT platform. Understanding the association between movies involves analyzing genre, cast, duration, and language. After a user watches a movie, closely associated recommendations are provided.
-
Image Compression
Applying the principles of dimensionality reduction, we conduct unsupervised learning to decrease the size of the image. Each pixel functions as a feature in this process, and dimensionality reduction algorithms such as PCA are employed to extract features. This involves combining similar features (pixels), resulting in the compression of the image.
Hopefully, you would have understood what supervised and unsupervised learning setups are. However, before this discussion is concluded, let’s summarize these two learning steps by understanding the difference between supervised and unsupervised learning.
Supervised vs. Unsupervised Learning
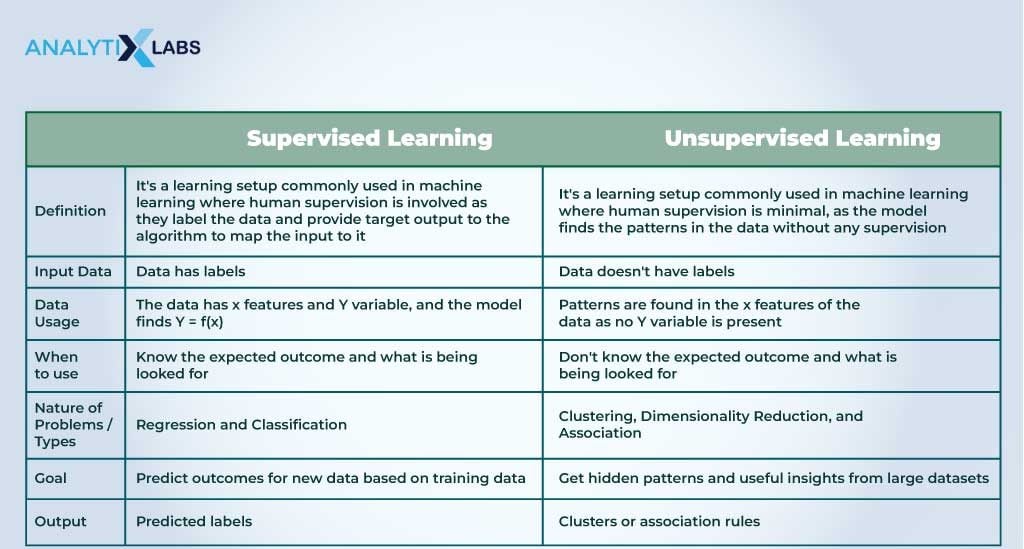
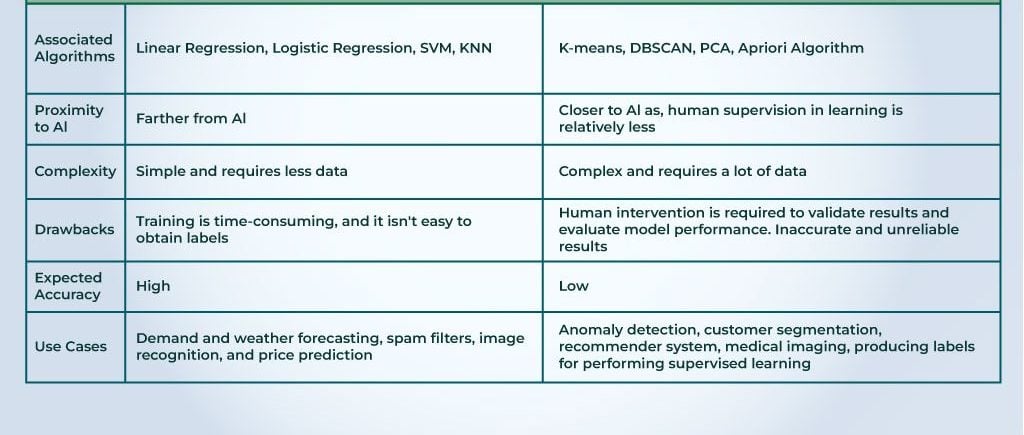
Supervised and Unsupervised are two main types of learning setups. They have their distinct characteristics, uses, merits, demerits, etc. To understand the difference between unsupervised and supervised learning, refer to the table below-
Conclusion
Learning setups play a crucial role in any machine learning practitioner’s life. Designing a comprehensive initiative in machine learning involves determining data collection methods, selecting algorithms, and experimenting with evaluation methods based on learning techniques.
Thus, knowledge of learning setups is crucial. You must be aware of the two most crucial learning setups – supervised and unsupervised- as all other learning techniques are rooted in these two techniques.
FAQs:
- Which is a supervised learning algorithm?
A supervised learning algorithm is any algorithm that maps the relationship between the independent input features and the target-dependent variable so that the model can predict outcomes on the unseen dataset. A common supervised learning algorithm is linear regression.
- What is an unsupervised learning example?
Analysts analyze customer data in customer segmentation, including demographic details, transaction information, and survey responses, to uncover hidden patterns and group customers. Customers in each cluster, i.e., the group, have certain common characteristics that help perform targeted marketing. Through such effort, appropriate products can be offered to members of each cluster.
We hope this article helped you understand learning setups and their types and expanded your knowledge about supervised and unsupervised learning setups.
- Machine Learning Vs. Deep Learning: Types, Working, and Differences
- Top Machine Learning Trends To Follow – 2024 Edition
- KNN Algorithm in Machine Learning
- Confusion Matrix in Machine Learning
- Fundamentals of Cost Function in Machine Learning
- Decision Tree Algorithm in Machine Learning
- List Of Popular Machine Learning Tools In 2024





