
Random forest regression is an invaluable tool in data science. It enables us to make accurate predictions and analyze complex datasets with the help of a powerful machine-learning algorithm.
A Random forest regression model combines multiple decision trees to create a single model. Each tree in the forest builds from a different subset of the data and makes its own independent prediction. The final prediction for input is based on the average or weighted average of all the individual trees’ predictions.
In this article, we will explore the fundamentals of random forest regression and discuss how to use random forest in Python. We will explain why random forest regression is an important technique in data science. And also covers topics such as building a random forest regression model, evaluating its performance, and interpreting the results from the model.
Finally, we will discuss the advantages of regression random forest. By the end of this article, you should have gained enough knowledge to apply random forest regression models to your own projects successfully.
What is a Random Forest Algorithm?
Random forest is a supervised learning algorithm, meaning that the data on which it operates contains labels or outcomes. It works by creating many decision trees, each built on randomly chosen subsets of the data. The model then aggregates the outputs of all of these decision trees to make an overall prediction for unseen data points. In this way, it can process larger datasets and capture more complex associations than individual decision trees.
How Does Random Forest Regression Work?
Random forest regression is a supervised machine learning algorithm. It uses an ensemble of decision trees to predict continuous target variables.
The individual decision tree models are constructed using a technique called bagging random forest. It involves randomly selecting subsets of the training data and building smaller decision trees from them.
After the bagging random forest step, we combine the smaller models to form the random forest model, which outputs a single prediction value. The technique helps reduce variance and improve accuracy by combining the predictions from several decision trees.
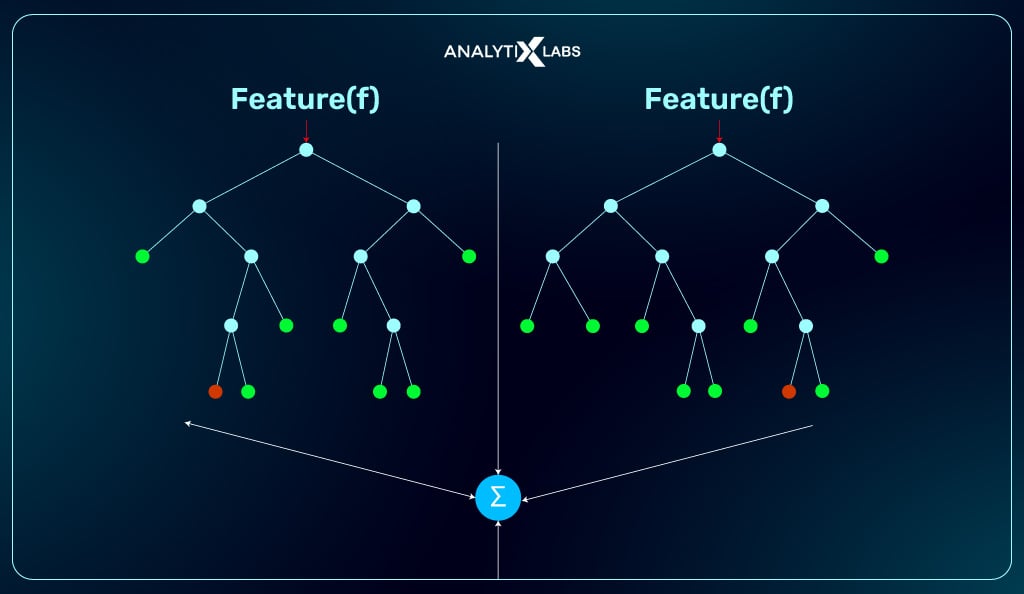
Building a Random Forest Regression Model
When building a random forest regression model, you need to identify several variables that represent potential features for your dataset. Furthermore, these variables should be related to the outcomes in some form so that they can provide meaningful information about how different features influence the predictions.
You also need to decide on the model’s size, which will determine the number of trees in the forest and their depth. Once these parameters are set, you can train the model on your dataset using various techniques.
Evaluating Random Forest Regression Performance
Once your random forest regression model is built, you need to evaluate its performance. It involves assessing how well it performs on unseen data points and measuring factors such as accuracy and precision. You can also use more advanced techniques, such as cross-validation, to ensure that your model is not overfitting or underfitting the data during training.
Interpreting Random Forest Regression Results
Finally, you need to be able to interpret the results from your random forest regression model. It involves understanding which features were most important in driving the predictions and how they interacted with each other to produce the final outcome. You can also use more advanced techniques, such as feature importance ranking and partial dependence plots to gain more insight into the model’s results.
When to Use Random Forest Regression?
People use Random Forest Regression to predict continuous values, such as predicting stock prices, time series forecasting, sale price predictions, etc. The random tree model works well with large datasets and captures non-linear relationships between input and target variables.
It is less prone to overfitting than other regression methods since it builds multiple random trees independently and averages them out at the end of its prediction process. Random forest regression is more reliable than traditional linear models for complex problems involving high dimensionality.
In addition, a random forest decision tree performs well with missing data and categorical variables, which makes it an ideal choice for many businesses that work with data containing varying feature types.
Consider Random Forest Regression when the data contains multiple features or inputs, and there is a need for accurate predictions that are less prone to overfitting.
Random Forest Regression vs. Linear Regression

Two of the most popular algorithms for predicting numerical values are linear regression and random forest regression. Linear regression models a target or dependent variable as a linear combination of predictor variables. In comparison, Random Forest Regression builds multiple random forest decision trees, which generate averaged predictions.
Linear Regression is usually appropriate if you have a large sample size and low variance in your data set. It makes assumptions about the relations between predictors and target variables, such as constant variance, normality of errors, etc.
Also read: What is Linear Regression In ML? With Example Codes
On the other hand, Random Forest Regression does not make any assumption about the underlying data distribution and can handle nonlinear relationships better. Moreover, it is less prone to overfitting due to its ability to randomly select different subsets of the data to train on and average out its results.
Generally, Random Forest Regression is preferred over linear regression when predicting numerical values because it offers greater accuracy and prediction stability. However, since Random Forests tend to have more complex models than linear regressions, they can take longer to train and may require more resources, such as memory or computational power. Thus, selecting between the two algorithms will depend heavily on the nature of the data set at hand.
Important Features of Random Forest
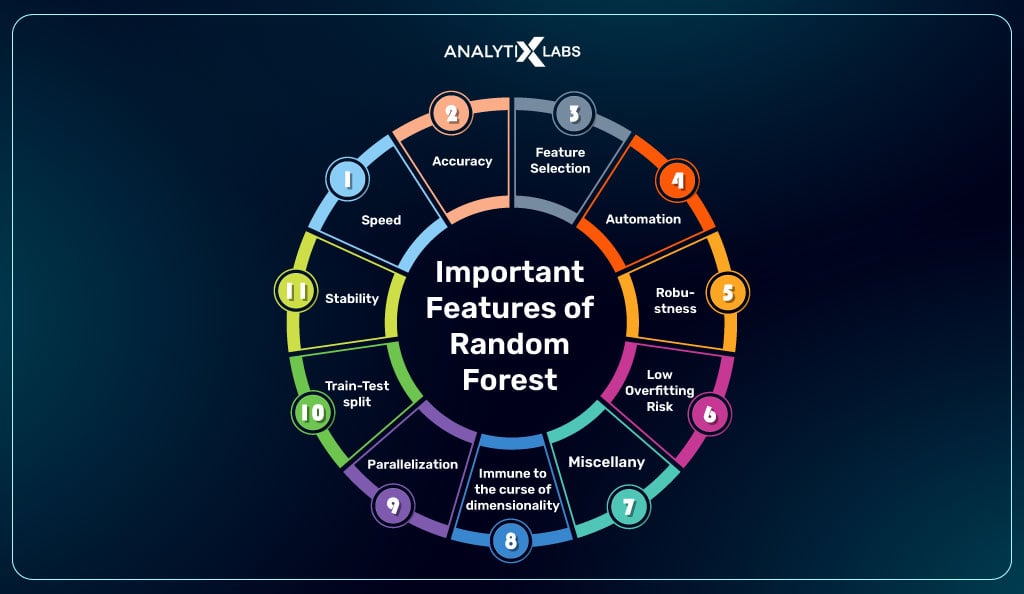
Some important features of this model are:
-
Speed:
Random forests are more efficient than other ensemble methods, such as boosting. The random forest algorithm can process large datasets with fewer parameters than competing algorithms, simultaneously making it fast and accurate.
-
Accuracy:
Random forests offer high accuracy when predicting outcomes due to their ability to create highly individualized decision trees that accurately classify data points based on their values across multiple features.
-
Feature Selection:
One key advantage of using a random forest is that it can select the most important features from a dataset for improved accuracy. This is done by constructing multiple decision trees and measuring the importance of each feature based on its contribution to accuracy.
-
Automation:
The random forest algorithm can be easily automated, making it an ideal choice for data scientists who quickly need efficient and reliable outcomes.
-
Robustness:
Random forests are resilient to noise in the data, meaning they will continue producing accurate results despite variable inputs or corrupted data points. It makes them an ideal choice when working with real-world datasets where there may be gaps or errors in the input values.
-
Low Overfitting Risk:
Random forests reduce the risk of overfitting since they create multiple independent decision trees that are unlikely to all make the same mistake. It helps ensure the model is more generalizable and can accurately classify data points it has never seen before.
-
Miscellany:
Not all trees are the same. Each tree of a random forest has its unique attribute, purpose, and variety concerning other trees.
-
Immune to the curse of dimensionality:
A tree is a conceptual idea and requires no features to be considered. Hence, the space for a feature is minimized.
-
Parallelization:
Since each tree is created autonomously from varying data and features, a random forest can be easily built using the CPU.
-
Train-Test split:
There is no need to differentiate the data for train and testing. This is because the decision tree never acknowledges 30% of the data.
-
Stability:
The final outcome is based on a Bagging random forest based on the overall average of the initial outcomes.
Random Forest in Python
Random Forest in Python can be used to make predictions and improve the accuracy of various models. With its flexibility and ease of use, the random forest regressor Python model is one of the most popular machine learning algorithms in use today.
In random forest regressor Python, scikit-learn provides a convenient interface for random forest regression. Scikit-learn uses a DecisionTreeRegressor library to create and train a random forest regressor object, which will be used to make predictions on new data points.
To create the regressor:
From sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
The parameters for the model are specified as arguments when creating the regressor object. For example, the number of trees in the forest can be specified using n_estimators.
Once the regressor is created, it must be trained on data by calling its fit() function.
This function takes two arguments: X (the set of features for each sample) and y (the target values corresponding to each sample):
rf.fit(X, y)
Finally, predictions can be made on new data points by calling the predict() function. This function takes a single argument, X (the set of features for each sample):
predictions = rf.predict(X)
Random Forest Algorithm Use Cases
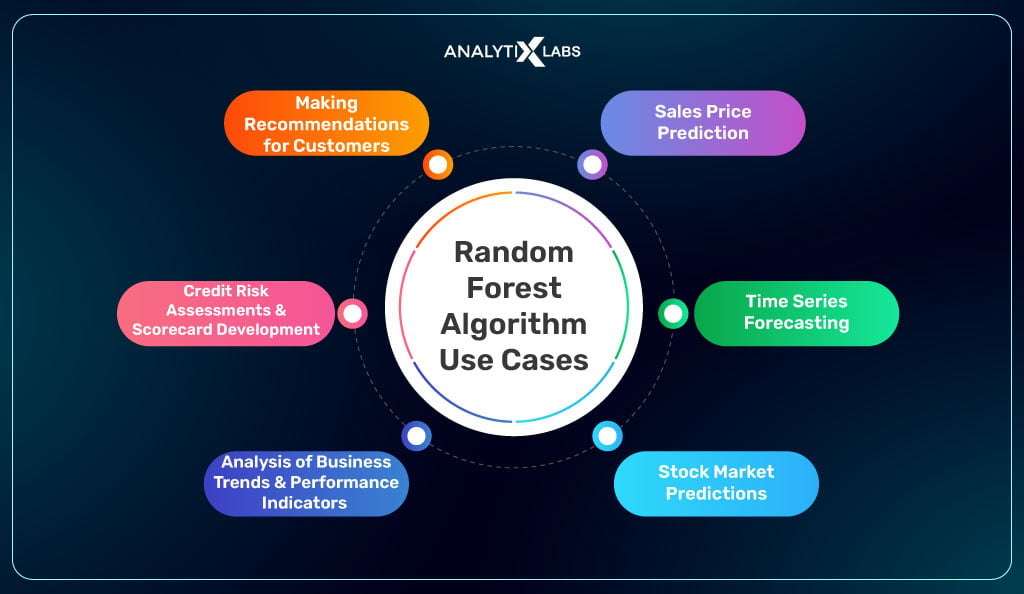
It is a powerful tool for making accurate predictions from data with multiple features or inputs. Random forest regression is reliable in complex problems involving high dimensionality and works well with missing data and categorical variables. It can be used in the following scenarios:
-
Sales Price Prediction
Random Forest Regression can be used to predict the amount a customer is willing to pay for a product or service. The prediction can help businesses determine pricing points that optimize profits or offer customers discounts that are attractive without sacrificing too much margin.
-
Time Series Forecasting
Random Forest Regression can be used to model the data trend over time to inform decisions about future business strategies. It does this by building multiple trees independently and averaging them together at the end of its prediction process. The approach enables it to capture complex patterns that can be elusive in linear models.
-
Stock Market Predictions
We can use Regression Random Forest for predicting stock prices and other financial instrument values. It does this by considering various factors related to the financial market, such as economic data, news events, and company fundamentals. The method has been shown to produce reliable results with less overfitting compared to traditional linear models.
-
Analysis of Business Trends and Performance Indicators
Businesses can make informed decisions about their operations and future strategies by analyzing business trends such as customer satisfaction ratings or product quality ratings.
Random Forest Regression can predict performance indicators like revenue growth or cost savings, helping businesses optimize their operations for maximum efficiency and profitability.
-
Credit Risk Assessments and Scorecard Development
Lenders can use the Regression Random Forest method to build credit scorecards that estimate the likelihood of a customer defaulting on a loan or making regular payments. It does this by considering various factors related to the borrower’s creditworthiness, such as past payment history, income, debt-to-income ratio, etc.
-
Making Recommendations for Customers
By considering customer behaviors such as product preferences, purchase histories, and demographics, businesses can make more informed recommendations about products or services that customers may find attractive. As a result, it can help businesses increase sales and build customer loyalty through personalized experiences.
Advantages of Random Forest Regression

Random forest regression has several advantages over other traditional methods of regression.
- First, it is less prone to overfitting than other linear models, such as multiple linear regression or support vector machines. This means that random forests can accurately predict outcomes on unseen data, reducing the risk of errors in predictive modeling.
- Second, trees are built incrementally and not by a single formula, so they naturally handle non-linearities in the data more effectively than linear models. This makes them better equipped for complex problems that involve multiple variables with varying degrees of importance or interaction.
- Third, random forest models are also computationally efficient and require fitting fewer parameters compared to other algorithms, such as neural networks or support vector machines. Additionally, the algorithm itself is relatively easy to implement and requires minimal user tuning. This makes it a great tool for quickly building models with good predictive accuracy without spending too much time tweaking parameters.
- Finally, random forest regression can be used as an ensemble method to create more robust models. Combining multiple trees can reduce bias and variance in your predictions. It is especially beneficial when dealing with high-dimensional data where overfitting may be problematic. Additionally, ensembles can capture interactions between variables that individual trees might miss.
By leveraging these advantages of Random Forest Regression, machine learning practitioners can build better models that accurately predict outcomes on unseen data. Such accurate and robust prediction models can be used to make more informed decisions in real-world applications.
Conclusion
Random Forest Regression is a highly versatile and reliable model for predicting outcomes in regression tasks. Its ability to handle non-linearities and its resistance to overfitting makes it an ideal choice for many predictive applications.
Additionally, the computational efficiency of the algorithm makes it easy to implement with minimal tuning required from the user. By leveraging these advantages, data science practitioners have far more options when selecting a model for their data science project.
Frequently Asked Questions
-
Does random forest work with regression?
Yes, the random forest can be used for regression as well. In this case, the algorithm creates a set of decision trees from randomly chosen subsets of the data and then averages out their results to get a more accurate prediction.
The regression random forest technique, or bagging random forest, reduces prediction variance by creating multiple estimates of the same question. Random forests are also less prone to overfitting than standard decision trees, so they can produce better results with fewer training cycles.
-
Why is random forest better than linear regression?
Random forest is a powerful machine-learning technique that has the potential to yield better results than linear regression. It is an ensemble of decision trees, which are much more powerful at capturing non-linear relationships between features and target variables than linear models.
Random forest works by constructing numerous decision trees. Each with different random subsets of features, then combining their predictions to produce a single prediction score. The ensembling process allows random forests to account for complex interactions in data sets and also helps reduce variance in the final prediction.
In addition, it offers several other advantages. Such as being robust against overfitting and providing excellent accuracy even when dealing with large datasets. Random forests can handle various data types, including categorical and numerical features, making them ideal for dealing with complex data sets.
-
How do you use random forest for regression problems?
Random forest is a helpful machine-learning algorithm for regression problems. It combines multiple decision trees to create a more accurate and reliable prediction model. To use a random forest for regression, you need to select the right hyperparameters. Like the number of trees, the maximum depth of the tree, or the number of features used in each split.
It is also important to pre-process your data by normalizing numerical values and encoding categorical variables. Once you complete these steps, you can apply the random forest algorithm using scikit-learn or R packages.
You can evaluate the model by calculating the Root Mean Square Error (RMSE), which measures how well the model fits the given data set. By finding an optimal combination of hyperparameters, it is possible to create an accurate random forest model for regression problems.






1 Comment
One of the standout features for me is its robustness against overfitting, thanks to the ensemble approach of using multiple decision trees. This leads to more reliable and stable predictions, even with complex datasets. Moreover, the interpretability factor, like feature importance, helps in understanding the underlying patterns and influences within the data. Overall, Random Forest Regression not only enhances predictive accuracy but also provides valuable insights, making it an indispensable tool in my analytics toolkit.