
Big data is a phenomenon that has gripped the world, and every other organization is trying to deal with it. Therefore, you must know that the most crucial factor in big data operations is the framework of Hadoop. Learn everything on Hadoop prerequisites to get started.
Big data is a large, complex dataset and is typically difficult to manage and process. Let’s look at some numbers to put the sheer volume of data generated in context. As of 2020, a person generates 1.7 megabytes of data every second.
By 2025, the world is expected to generate 181 zettabytes of data. It’s the reason that 95% of businesses consider dealing with large unstructured data as a problem, and almost 97.2% are investing in big data.
Let’s start with the journey by first briefly understanding the functioning of Hadoop.
Introduction to Hadoop
Hadoop has been developed to resolve the issues posed by Big Data. The idea for creating Hadoop started when Google invented a data processing methodology called MapReduce and published a whiter paper explaining the framework.
Later, Doug Cutting and Mike Cafarella drew inspiration from the paper and created Hadoop, an open-source framework for implementing the concepts outlined.
-
Definition
Apache Hadoop is the most famous application of Hadoop.
The engineers designed Hadoop as a framework for processing data in a distributed computing environment. Applications can be developed that can process large datasets across clusters of commodity computers. As commodity computers are cheap and readily available, they allow for much greater computational power at a reasonable cost.
One can understand Hadoop by understanding how data resides in the local file systems on our personal computers. Similarly, in Hadoop, data resided in distributed file systems. This distributed method of storing data is known as Hadoop Distributed File System or HDFS.
Hadoop uses a processing model that runs on the ‘Data Locality’ concept to process such distributed data. In this concept, the cluster nodes receive the computational logic (a compiled version of a program written in Java or any other high-level programming language), i.e., a server that contains the data.
-
Eco System
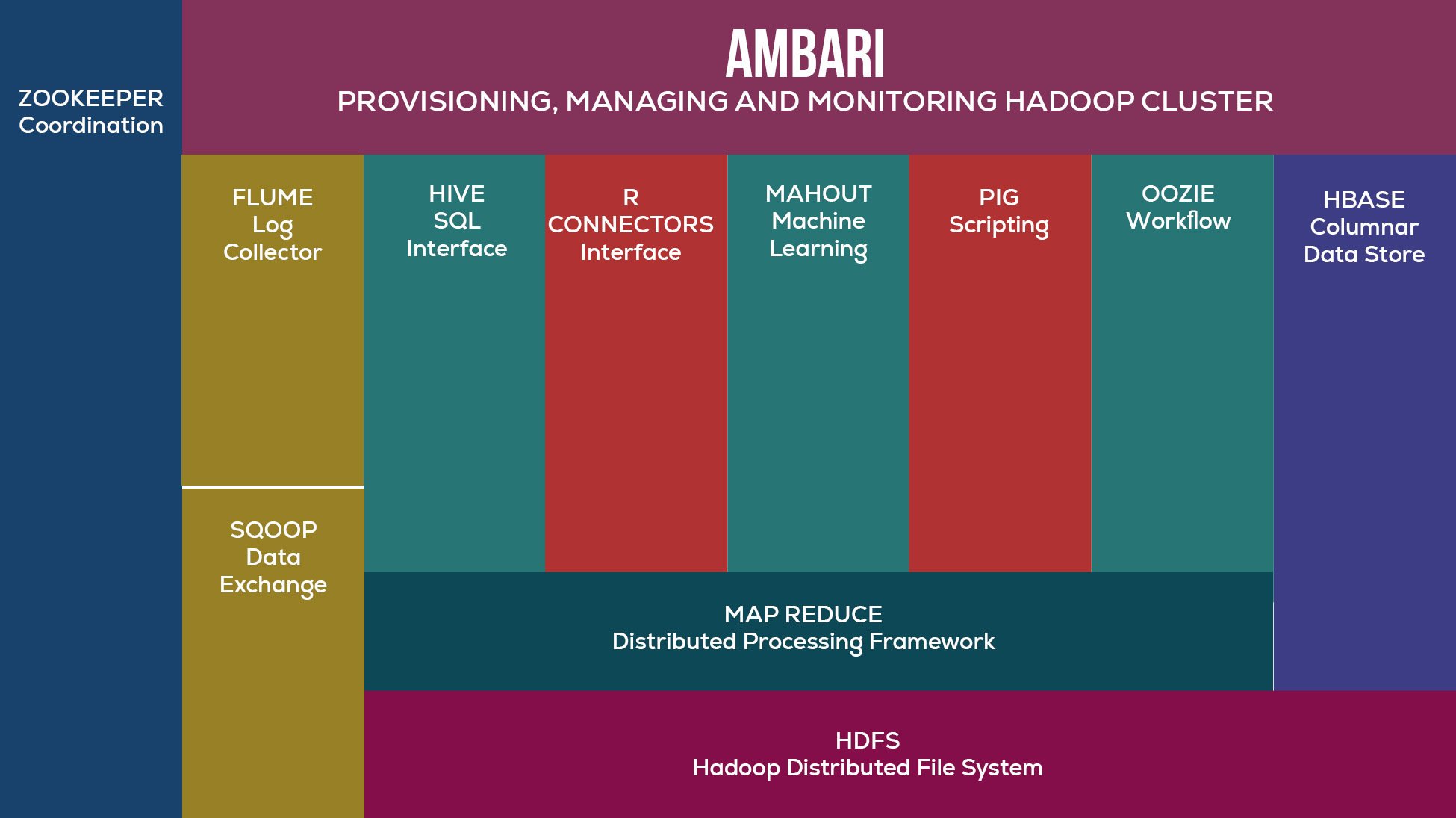
Hadoop can’t function stand-alone and requires several tools and techniques to work efficiently, creating the Hadoop ecosystem. The most common tools and techniques in the Hadoop ecosystem are the following-
- Zookeeper: for coordination
- Sqoop: to enable data exchange
- Hive: to provide a SQL interface
- Mahout: for performing machine learning
- Pig: for scripting
- MapReduce: to provide a distributed processing framework
- HDFS: for storing data in a distributed framework
-
Hadoop Common
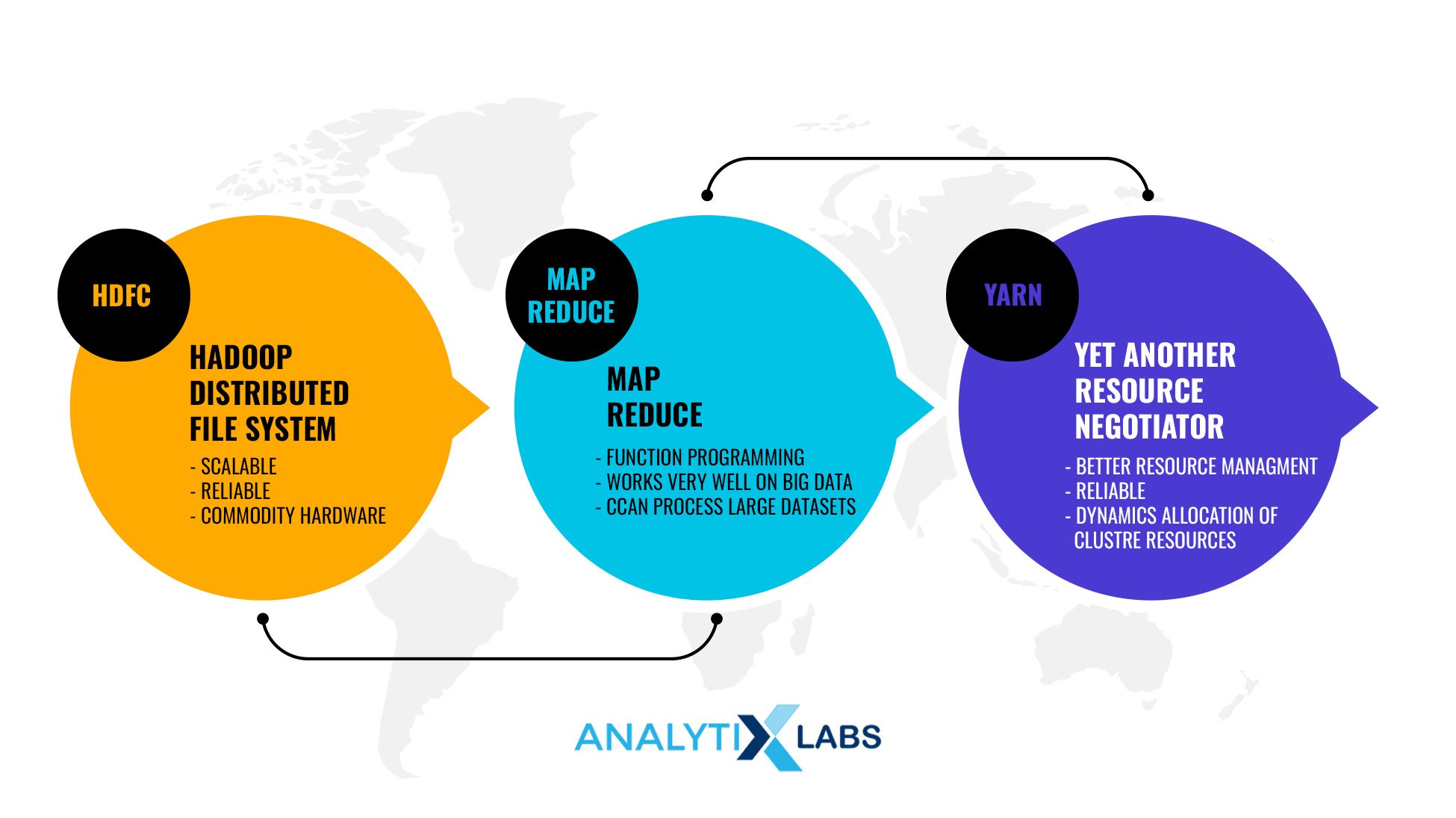
Apache Hadoop has three standard utilities known as the Hadoop common, enabling working with several other Hadoop modules. They are-
- HDFS: As mentioned before, HDFS is responsible for the data storage aspect of Hadoop. It creates multiple replicas of data blocks and then distributes them on computer nodes in a cluster allowing for high-speed and unrestricted access to data applications.
- MapReduce is the computational model responsible for processing large amounts of data on multiple computer nodes, and it consumes the data from HDFS.
- Hadoop YARN: It stands for Yet Another Resource Negotiator. It is used to schedule the job and manage cluster resources efficiently.
-
Architecture
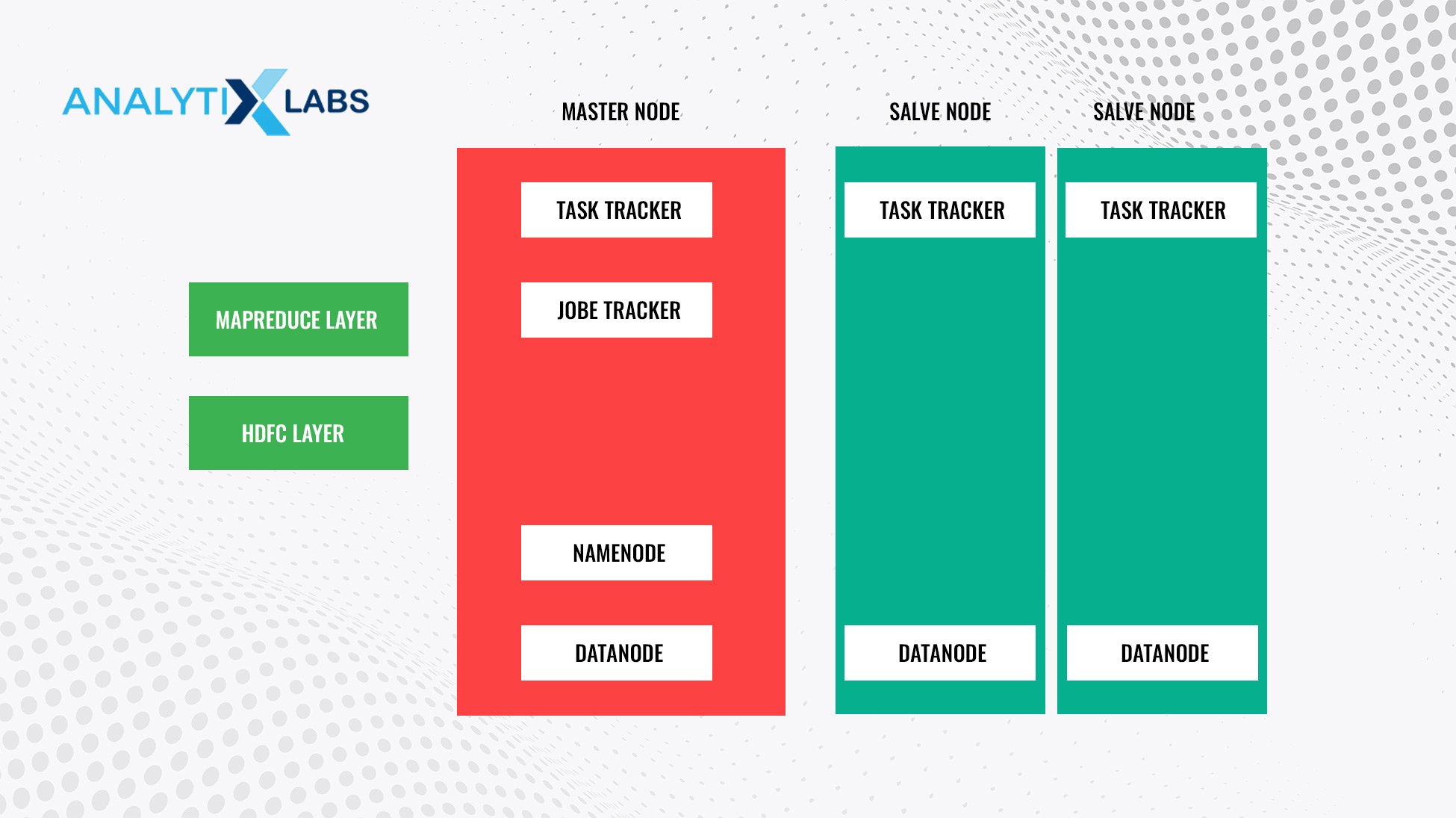
Hadoop uses the Master-Slave architecture for data storage and processing. The essential components of this architecture are the following-
- NameNode: In the namespace, it represents every file and directory.
- DataNode manages the HDFS node’s state and allows users to interact with the blocks.
- MasterNode: It allows for parallel processing of data and MapReduce.
- SlaveNode: It refers to the various additional machines in the Hadoop Clusters. The user stores data through these nodes for performing calculations and other operations. All the salve nodes have Task Tracker and DataNode, allowing users to synchronize the process with NameNode and JobTracker.
-
Process
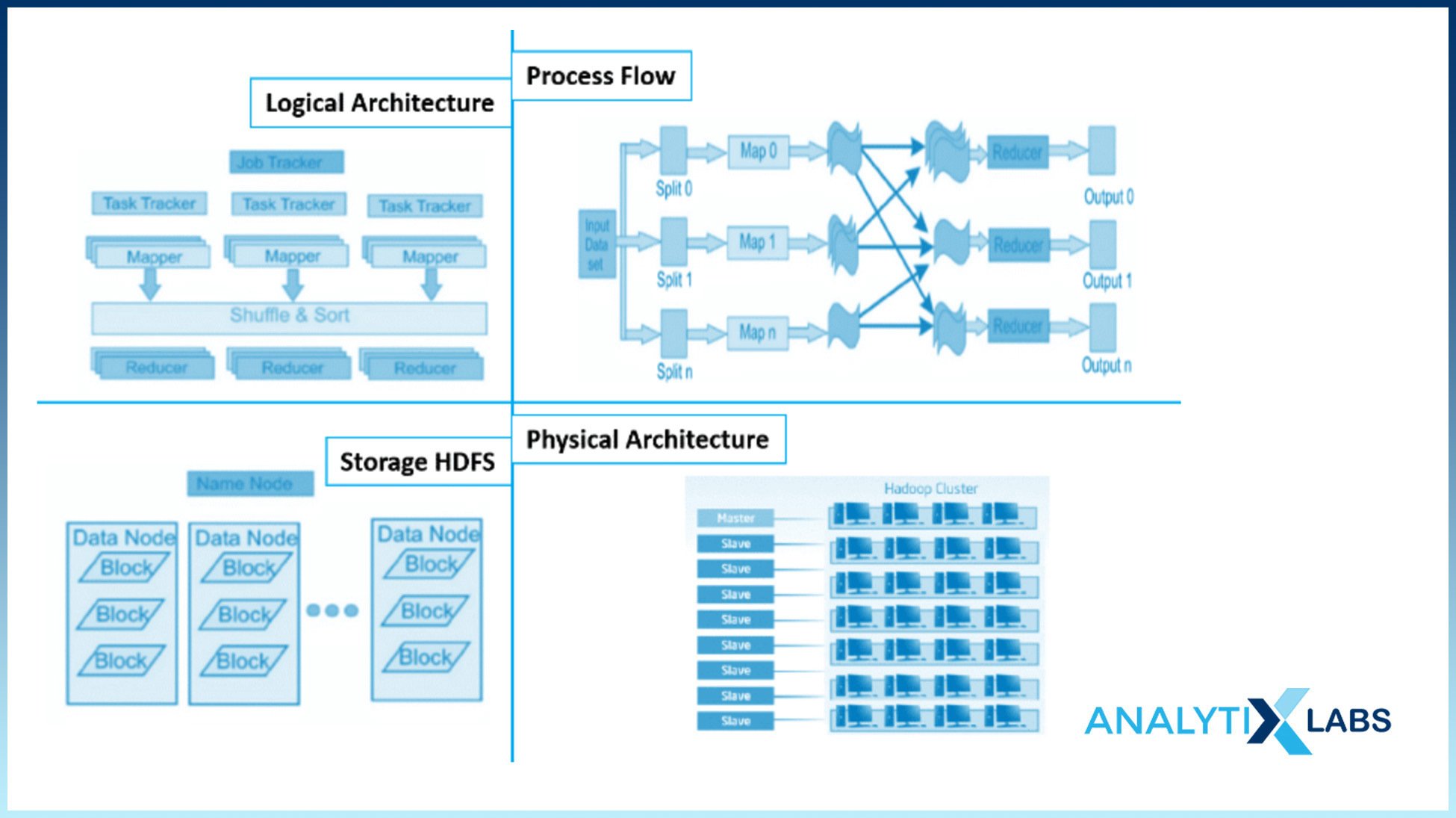
To put all the information mentioned so far in context, let’s discuss Hadoop’s process for dealing with Big Data. While the architecture can vary based on the parameters selected by the user, on an overall level, Hadoop performs a task in the following manner-
- Input data is divided into files and directories. These files are divided into blocks of uniform sizes, such as 64M or 128M.
- The divided files are distributed for processing across numerous cluster nodes.
- On top of local file systems, HDFS supervises the data processing.
- To mitigate the risk of hardware failure, the blocks are replicated.
- Code execution status is checked to determine if it is successful or not.
- Sorting is performed between map and reduced stages.
- Sorted data is sent to a particular computer.
- Debugging logs are written for each job.
-
Features
Several features make Hadoop an exciting choice for dealing with big data. Some of the essential features include the following-
- Efficient: Hadoop clusters allow for easy analysis of big data. As Hadoop uses the data locality concept where in place of the actual data, only the processing logic is passed to the computing node, it allows for less bandwidth consumption, helping increase the overall efficiency of Hadoop-based applications.
- Scalable: It is straightforward to scale up Hadoop clusters as new cluster nodes can be added without modifying the existing application logic.
- Tolerance: The input data is replicated in the Hadoop ecosystem onto other cluster nodes, which helps resolve data loss issues in case of a cluster node failure, as data can still be processed using the replica of the available data on another cluster node.
If you know about Hadoop or if, based on the above information, it interests you, and you want to enter the process of Hadoop learning, then let’s look at what you need to know before getting started.
Prerequisite for Hadoop
You need to know several Hadoop prerequisites before you start learning it, as knowing about the concepts will help you immensely in your learning journey. You may not have to master all the below-mentioned tools and techniques, but having substantial knowledge of them will be necessary to function effectively when using Hadoop.
-
Java
Among the major Hadoop requirements is Java because, for the most part, Hadoop is written in Java; therefore, you need to have at least a basic understanding of this language. It is mainly because the main programming block of Hadoop is MapReduce, which performs the data processing using Java.
-
Programming Knowledge
If you are unaware of Java and still want to start with Hadoop, the good news is that you can. Hadoop allows you to write the map and reduce functions in multiple languages, including C, Python, Ruby, Perl, etc. In addition, Hadoop has Pig and Hive, which are high-level abstraction tools that reduce your need for Java.
However, knowing it can enable you to understand Hadoop’s nuts and bolts, helping you troubleshoot issues quickly. Thus, mastering any high-level interaction language is necessary before starting the Hadoop learning process.
-
Linux
For better performance, Hadoop is run on Linux as it is primarily built for it (but it can run on Windows, too). Therefore, having basic knowledge of Linux is good as it is the preferred method for installing and managing Hadoop clusters. Also, to work with Hadoop HDFS, knowing about the common Linux commands is, without a doubt, a must.
-
Big Data
Having theoretical knowledge of big data is crucial. Many big data prerequisites overlap with Hadoop, so it can be tricky regarding where to start, but you can begin by exploring the following topics-
- data storage mechanism
- data types and structures
- big data life cycle
- cluster computing
- batch processing
- data lake
- data mining
- data warehousing
- ETL processes
- machine learning
- big data algorithms
- In-memory computing
- stream processing
Also read: Big Data Technologies That Drive Our World
-
SQL
Among the essential operations of Hadoop are ETL and data query. To perform these, you must use SQL or some other language with a syntax similar to SQL. Apache Hive, for example, is a very common language used in the Hadoop ecosystem with a syntax similar to SQL.
Similarly, Pig also has several commands that look like SQL. In addition, tools like Hbase and Cassandra also provide an interface to interact with data similar to SQL. Thus making the knowledge of SQL a significant Hadoop prerequisite.
-
Statistics
The main objective of Hadoop is to make data available for analysis, and statistics are heavily involved in data analysis. Hadoop learners need to know a fair bit of statistics as it allows them to understand and describe data, helping them to perform their daily operations effectively.
-
Analytical Mind and Problem-Solving Skills
A big data engineer needs to resolve many issues. They have to deal with machine learning algorithms and sometimes perform complex data analysis to understand better what operation needs to be performed. All this requires an analytical bend of mind and good problem-solving skills.
You might or might not fulfill the Hadoop prerequisites discussed above. However, to learn Hadoop, you must start learning the concepts you lack. Now, let’s talk about the various job roles associated with Hadoop, as many job profiles are associated with it or require you to know about it.
Hadoop Professional Roles
Poor data quality costs US businesses $600 billion annually, and the solution can be found using big data, mainly through Hadoop. Today, big data jobs that require you to know Hadoop are everywhere, with average salaries starting from 8lakhs per annum. Dealing with Hadoop is a complex task as one needs to install, configure, maintain, and secure it, and the overall volume and complexity of big data are also increasing.
All this has led to numerous job profiles propping up in the field of big data, where Hadoop is the sole or one of the major requirements. The following are the most common and in-demand job profiles-
-
Big Data Analyst
Big data analysts must perform big data analytics and give recommendations to enhance the system’s capabilities. They mainly focus on streaming, migrating data, and working closely with data scientists and architects.
Big Data Analysts also ensure that the implementation of big data and Hadoop-related tasks are streamlined. They are also responsible for various big data processes like filtering enrichment, text annotation, parsing, etc.
-
Big Data Architect
Big Data Architects are responsible for delivering various big data solutions. They are responsible for understanding requirements, platform selection, and designing the big data and Hadoop ecosystem’s technical architecture and landscape.
Most importantly, for a proposed solution, they perform its designing, development, testing, etc. It is expected of them to know about various technologies and platforms.
Also read: What is Big Data Architecture?
-
Data Engineer
Data engineers are involved in the design solution on a high-level architecture. They are responsible for managing the communication between internal systems and vendors and managing production systems using tools like Cassandra, Kafka, etc. Data Engineers also build cloud-based platforms, allowing new applications to be easily developed.
-
Data Scientist
Data scientists are often expected to know Hadoop, particularly when dealing with big data. Although their primary focus is on data analytics and modeling, familiarity with Hadoop is beneficial. In such scenarios, data scientists utilize the Hadoop ecosystem to analyze company data and enhance business strategies, products, and other aspects.
Also read: How to Become A Data Scientist in 2023
-
Hadoop Developer
Hadoop developers install, configure, and make Hadoop available for organizations. They write Map-Reduce code for Hadoop clusters, convert technical requirements into detailed designs, and ensure data maintenance by managing security and privacy.
Hadoop developers manage and monitor Hadoop log files, design web services for data tracking, propose standards, etc. It is expected that Hadoop developers have descended knowledge of SQL and data warehousing.
-
Hadoop Tester
In a situation where there is a requirement to fix bugs and troubleshoot Hadoop applications, a Hadoop tester is required. They ensure the various scripts written in the Hadoop ecosystem, such as Pig Latin and HiveQL, function correctly. Hadoop Testers also build test cases to debug Hadoop and its related frameworks.
The managers are provided with defect reports by Hadoop testers, making their job crucial to any organization with big data. They are expected to be aware of Apache Pig, Hive, Selenium automation tool, MRUnit, and JUnit testing frameworks, Java (to perform MapReduce testing), and methods of creating contingency plans in case of a breakdown.
-
Hadoop Administrator
Hadoop administrator is among the most crucial job roles as they are responsible for the smooth functioning of the Hadoop framework and are expected to deal with backup, recovery, and maintenance operations. The job profile of a Hadoop administrator is similar to that of a System administrator.
Unlike other Hadoop-related job profiles, they are expected to have complete knowledge of the Hadoop ecosystem, including the hardware and architecture ecosystem. Their role includes managing HDFS, regulating admin rights based on job profiles of users, and adding or removing users.
They also help secure Hadoop clusters, planning for capacity and upgrading or downgrading it based on requirements and backing up the entire system on a routine basis. Hadoop Admistarors are required to be proficient in HBase(for administering Hadoop), Linux scripting, Hive, Oozie, Hcatalog, etc.,
-
Hadoop Architect
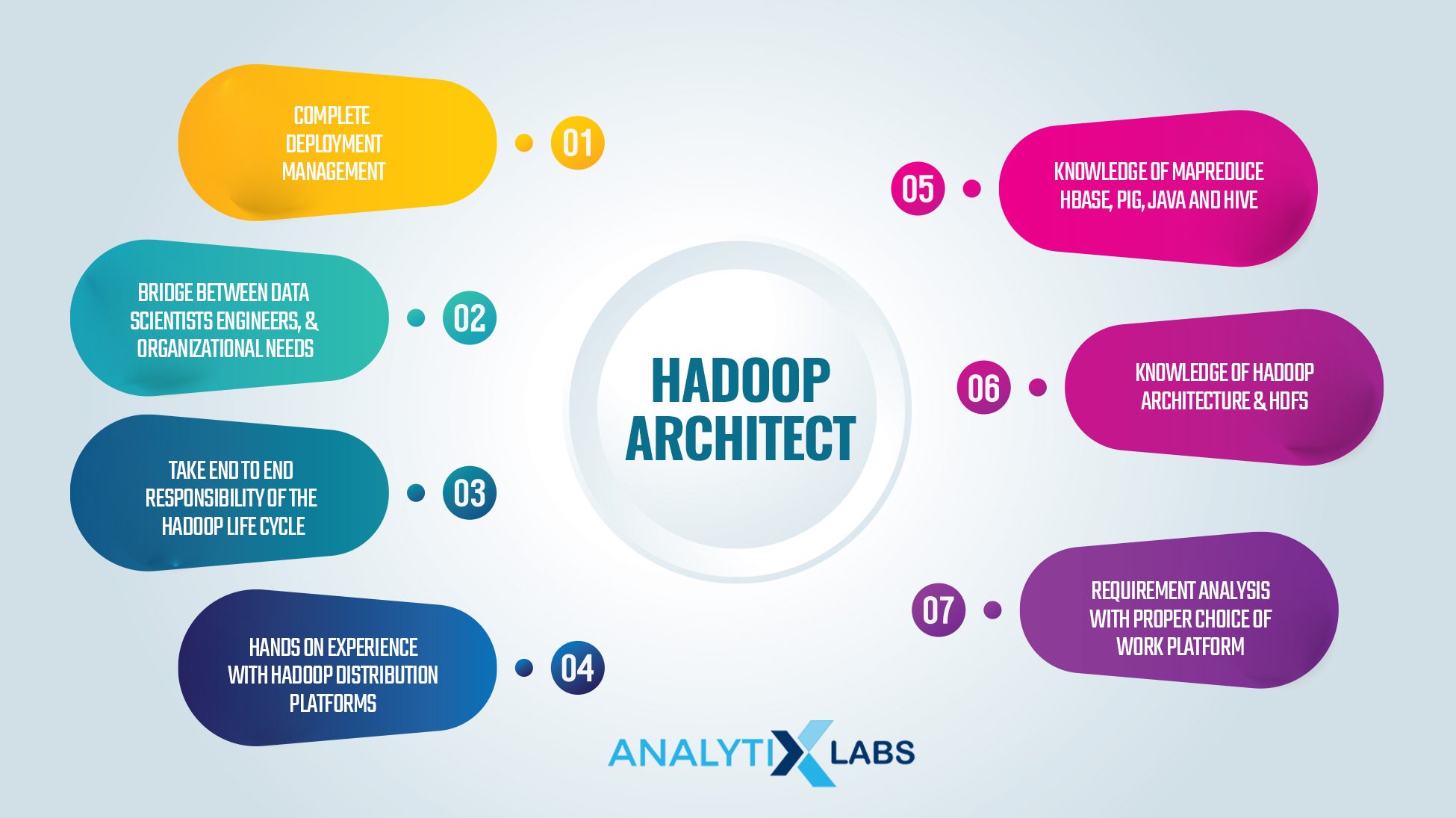
Lastly, just like a Big Data Architect, a Hadoop architect who is more well-versed with the Hadoop-based concepts is required to design Hadoop architecture. The primary job role of a Hadoop architect is to deploy Hadoop-based solutions. If we go into the details about the several responsibilities of a Hadoop architect, then in that case, the most common include-
- taking responsibility for the Hadoop life cycle
- performing in-depth analysis to choose the right work platform
- ensuring all the expected Hadoop solutions are deployed without any issues
Hadoop architects are expected to know Pig, Java, MapReduce, HBase, Hadoop architecture, HDFS, and various Hadoop distribution platforms like MapR, Cloudera, and Hortonworks.
Given the many job profiles related to Hadoop, it is no surprise that there are many areas of operations for Hadoop. The next section discusses the most common and prominent Hadoop operational areas.
Hadoop Operational Areas
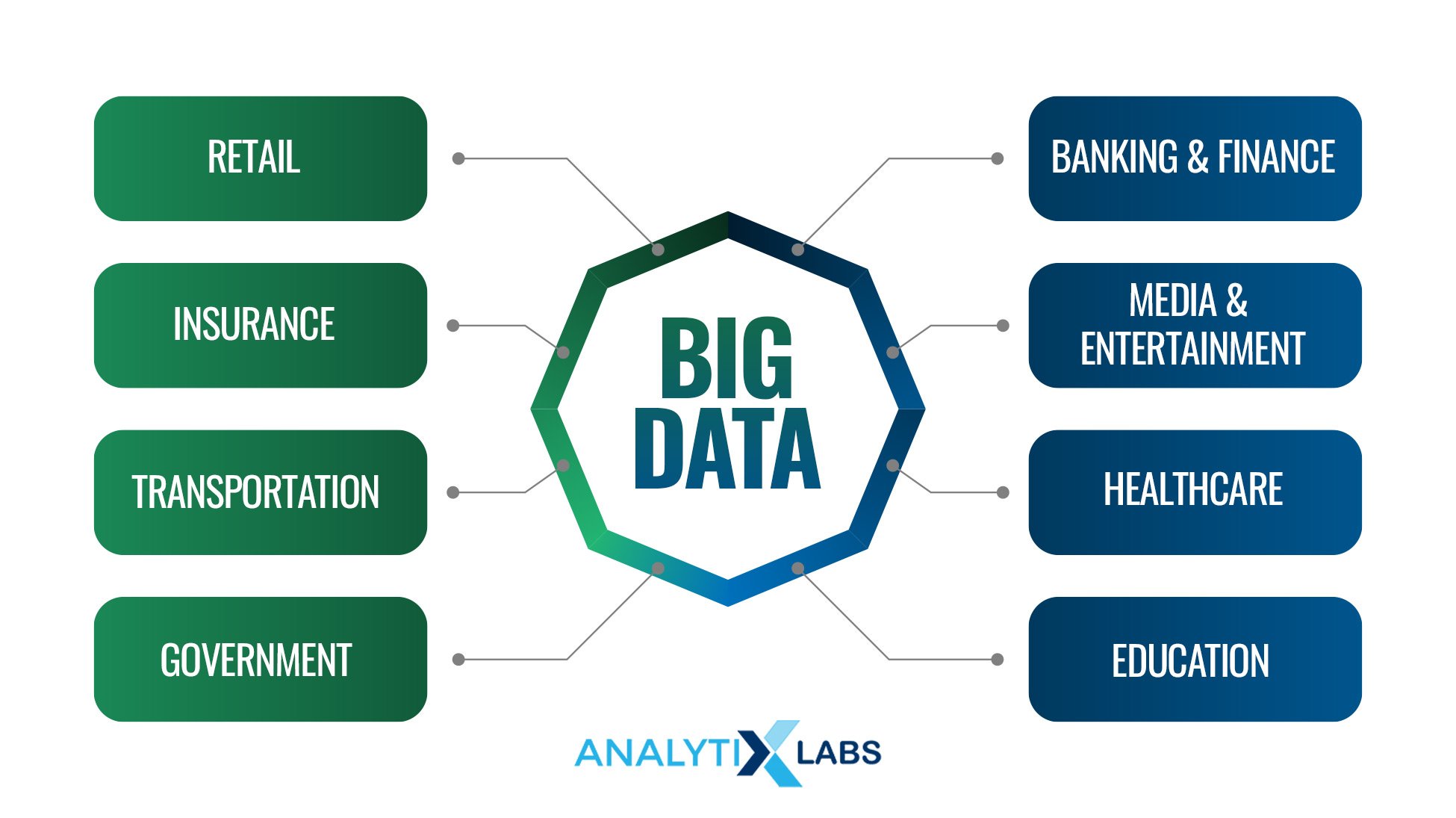
There are numerous domains where Hadoop has found its place. The following are the most prominent domains and companies where Hadoop is heavily used.
-
Domains
Security- USA’s NSA is known to use Hadoop to prevent terrorist and cyber attacks.
Customer Understanding- Many companies use Hadoop to analyze the data generated by customers’ activity to understand customer behavior and create targeted products and marketing campaigns.
Government Use for City Infrastructure- Governments have increasingly used Hadoop to manage traffic jams, develop smart cities, etc.
Finance- Financial companies use Hadoop to analyze large quantities of data and identify trading opportunities through forecasting.
Business Process Optimization- Hadoop allows for optimizing business processes. Companies can leverage Hadoop to make better HR decisions, optimize product delivery routes, and achieve various other benefits.
Healthcare- Healthcare products have created enormous data to help improve medicines by monitoring day-to-day activities. Hadoop comes in handy to perform such large-scale analytics.
Sports– Video analytics and body sensors are increasingly used in tennis, football, baseball, cricket, etc. Hadoop here helps in analyzing such semi-structured and unstructured data.
Telecommunication– Hadoop helps in better analytics, enabling models to predict infrastructure maintenance, creating efficient network paths, recommending locations for cell towers, etc.
-
Companies
The companies mentioned below are known to use Hadoop for the following reasons-
- Facebook (Meta): Generate reports for advertisers, run the messaging app, and query numerous graph tools
- eBay: Search engine optimization
- Skybox: Store and process images for identifying patterns in geographic change
- Tinder: Behavioural analytics helping to create personalized matches
- Apixio: Semantic analysis, so doctors respond better to patient health-related questions
Skills required to learn Hadoop
Given that so many companies and domains are using Hadoop, it is tempting to get into the field of big data. There are, however, a few specific skills in terms of tools and theoretical techniques that you should be aware of if you wish to learn Hadoop. Some of them are the following-
- Hadoop Basics
- HDFS
- HBase
- Kafka
- Sqoop
- Flume
- SparkSQL
- Apache Spark
- Map Reduce
- Apache Oozie
- GraphX
- Apache Hive
- Mahout
- Ambari
- Code Ethics
Since Hadoop has generated a lot of discussions and gained significant prominence, it is worth exploring the reasons behind its fame. In the next section, we will discuss some of the significant benefits of Hadoop.
Benefits of Using Hadoop
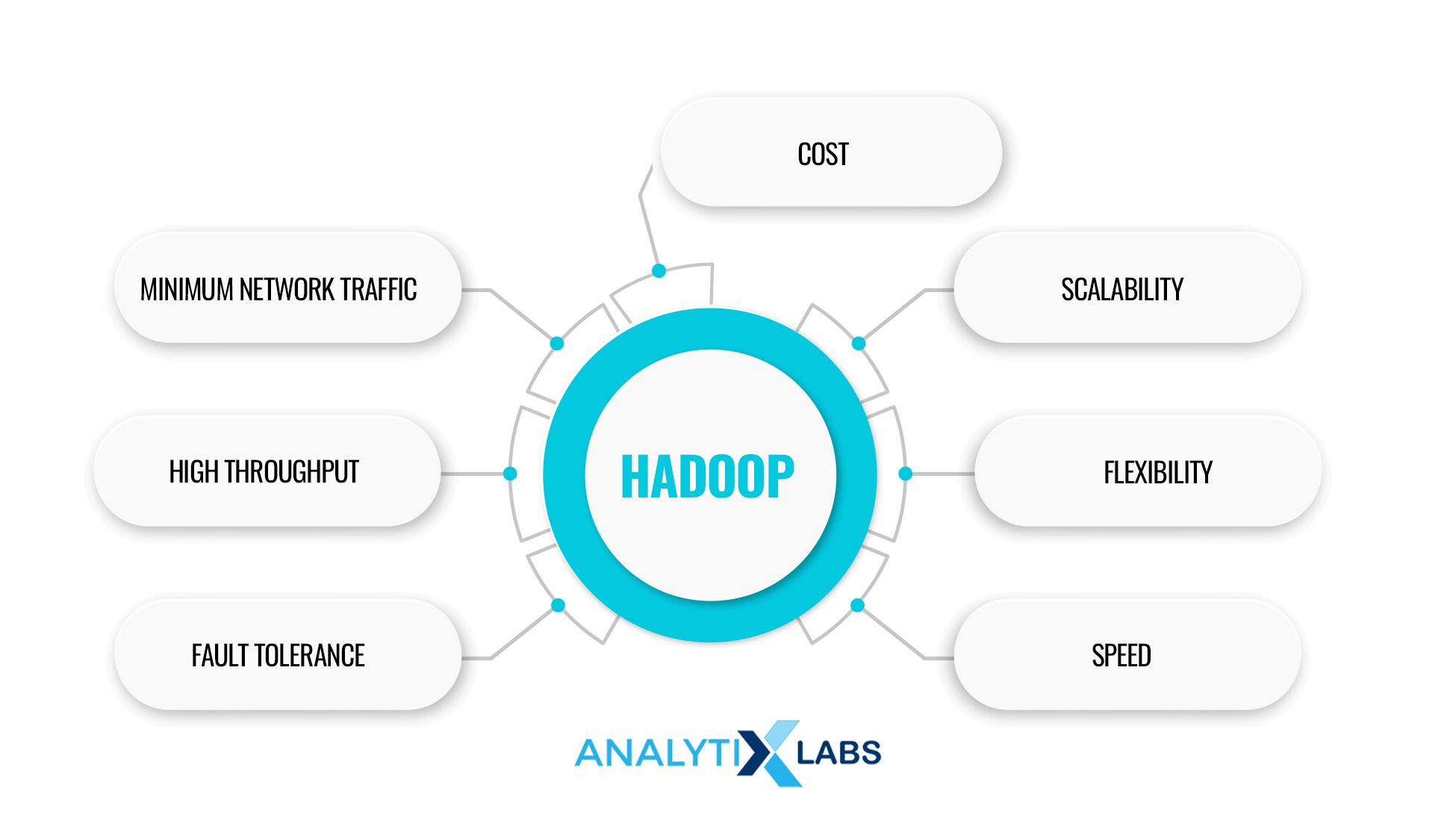
There are several reasons why companies worldwide have adopted the Hadoop framework to resolve the issues arising from big data. Some of the most crucial benefits of using Hadoop are as follows-
-
Cost
Hadoop is open source, and because it uses commodity hardware, it helps to reduce costs. It is much cheaper than the other existing alternatives of database management systems.
-
Scalability
Hadoop can be easily scaled as additional nodes can be added without substantially altering the pre-existing architecture and logic.
-
Flexibility
Hadoop can deal with different types of data, such as MySQL data (structured), XML, JSON (semi-structured), and audio, video, and text (unstructured).
-
Speed
As Hadoop uses HDFS to manage data storage, it allows for parallel data processing, making its performance fast.
-
Fault Tolerance
Hadoop uses inexpensive commodity hardware and replicates data on various DataNodes, reducing the chances of data loss if the systems crash.
-
High Throughput
Throughput is the task done per unit of time, and as Hadoop uses a distributed file system, it has a high throughput.
-
Minimum Network Traffic
Each task in Hadoop is divided into smaller subtasks, which are subsequently assigned to individual data nodes within a Hadoop cluster.
This distribution ensures that each data node processes a small amount of data. This framework leads to low traffic in a Hadoop cluster.
-
Availability Rate
For a single active NameNode, a Standby NameNode makes the availability rate of Hadoop 2.0 high, with Hadoop 3.0 having multiple Standby NameNodes, making the availability rate higher.
-
Open Source
Hadoop is an open-source framework that allows developers to modify the code based on their organization’s requirements.
-
Compatibility
Lastly, Hadoop’s other advantage is that it is compatible with emerging big data technologies like Spark and Flink. Also, developers can code in multiple languages in Hadoop, such as Python, Perl, Ruby, Groovy, or the more traditional C and C++.
If you find Hadoop interesting and wish to begin your journey with it, I encourage you to continue reading. In the following sections, you will discover the career benefits of obtaining a big data certification and the hardware requirements to embark on your Hadoop journey.
Career Benefits with Big Data and Hadoop Certification
It is important to learn Hadoop step by step as it is a complex framework. Doing a Hadoop or Big Data certification eases the learning process and gives you creditability regarding your knowledge of Hadoop and big data. The demand for Hadoop and big data-related jobs is at an all-time high.
For example, a Hadoop developer makes an average of around $121K in the USA. There is a demand for Hadoop developers in cities like Mumbai, Gurgaon, Bengaluru, Hyderabad, and Chennai in India.
For example, the average salary in Bengaluru is between 6 lakhs and 10 lakhs for a Big Data/Hadoop developer. Therefore, you have considerable scope if you pursue a big data certification.
AnalytixLabs also provides a Certified Big Data Engineering course where you learn Hadoop step by step, helping you get started in this field. There are, however, a few Hadoop system requirements that you need to take care of if you wish to learn Hadoop and get certified in big data and Hadoop, which is discussed next.
Hardware Requirements to Learn Hadoop
You need to take care of three main Hadoop hardware requirements, i.e., the RAM, HDD, and Processor components for learning and running Hadoop on your machine.
- RAM
Among the most crucial Hadoop system requirements is RAM. You require a minimum of 1GB of RAM for running Apache Hadoop, whereas, for running applications like Cloudera, MapR, and Hortonworks, you require 8GB of memory.
Installing Hadoop from the search can be time-consuming, so it is better to use Cloudera Quickstart VM. Therefore, 8GB of RAM is recommended.
- HDD
Ideally, when installing Hadoop, you require more than 100GB of storage, as you should allocate at least 50GB of storage to the virtual memory.
- Processor
Lastly, another major Hadoop hardware requirement is regarding the processor. You should have a minimum of i3 or above; however, i5 or beyond would be preferable, with a minimum operating frequency of 2.5GHz.
Given all the discussion so far, if you are still unsure if you should be learning Hadoop, the next section should give you a complete idea of whether Hadoop is for you.
Who should learn Hadoop?
As such, anyone with basic programming knowledge can help start learning Hadoop and its prerequisites. However, few job roles are most conducive to learning Hadoop as it can be easy for them or make a lot of sense given their nature of work. The typical job profiles that must consider learning Hadoop are the following-
- Business Intelligence Professionals
- Data Warehouse Professionals
- Professionals with Java Background
- Professionals with ETL Background
- Professionals with DBA or SQL Background
- Professionals with SAP Background
- Professionals with Mainframe Background
Conclusion
According to the study by McKinsey Global Institute, there will be a severe shortage of big data and Hadoop professionals in the US alone. The demand for Hadoop developers can exceed the supply by around 60%.
Companies worldwide require professionals with good skills in Hadoop due to the rapid generation of big data. Considering the advantages of Hadoop, it is advisable to begin exploring it if you find it interesting.
FAQs:
- What is the prerequisite to learning Hadoop?
The Hadoop prerequisites include a functional knowledge of Java or other OOPS languages, statistics, databases, and other big data concepts.
- What is the prerequisite for Hadoop installation?
To begin, you will require a computer equipped with at least 1-8 GB of RAM, 20-100GB of storage, and an i3 processor or a more advanced one. Additionally, a working internet connection is necessary.
- Is Java a prerequisite for Hadoop?
It is beneficial to know Java, and it is a must for specific Hadoop-related job profiles. Still, in many cases, you can use Hadoop without relying on Java by using other languages like Python, C, etc.
- What are the prerequisites for big data?
Prerequisites for big data include having programming skills and knowledge of Linux commands, SQL, Shell programming, Hadoop basics, etc. There are many commonalities between the prerequisites for big data and the prerequisites for Hadoop.
We hope this article helped you expand your knowledge about Hadoop and clarified various Hadoop requirements in terms of hardware. I hope you will deal with all the prerequisites for Hadoop and will start the learning process soon.
If you want to know more about Hadoop or big data prerequisites or wish to enroll in a Big Data-related course, contact us.


