
If you are studying statistics, you will frequently come across two terms – parametric and non-parametric test. These terms are essential for anyone looking to pursue Statistics and Data Science. However, seldom one understands the gravity of these terms, especially when dealing with a holistic understanding of statistics and its implementation in data science.
Parametric and non-parametric tests are the two main ways of classifying statistical tests. The exciting and complicated aspect of this classification, particularly regarding non-parametric tests in statistics, is that there is no definitive definition of what defines a non-parametric test.
This makes understanding the differences between these two terms more complicated, and you require a more nuanced approach.
One common way is to take examples of parametric tests and then discuss their non-parametric counterparts. This is one of the best methods to understand the differences. In this article, we will take this approach to understand the topic at hand.
What are Parametric Tests?
Parametric tests are the backbone of statistics and are an inseparable aspect of data science. This is simply because to interpret many models, especially the predictive models that employ statistical algorithms such as linear regression and logistic regression, you must know about specific parametric tests.
However, to fully grasp the idea of what a parametric test is, there are several aspects of Statistics that need to be on the tip of your fingers. Before proceeding, let’s brush up on these concepts.
Also Read: Basic Statistics Concepts for Data Science
1) Population
Population refers to all individuals or subjects of interest that you want to study. Typically, in statistics, you can never fully collect information on population because-
- Either – the population is too large, causing accessibility issues . For example, suppose you want to know the income of all working Indians. In that case, asking about the income of millions of individuals in the organized and disorganized sector is almost impossible.
- Or – the volume and velocity of the population data are too high, which causes hardware issues (limited memory), making it difficult to process such data . For example, if you want to understand the spending pattern of the major bank’s customers, the sheer number of transactions happening at any given moment can be in millions. Analyzing a month’s data can be computationally so expensive that it’s impossible to use the whole data.
2) Parameter
To answer any question, you will need arithmetic to quantify the population. Such critical quantification methods can be – mean, standard deviation, median, minimum, maximum, inter-quartile range, etc. These significant values that describe the population are known as ‘parameters’.
3) Sample
As mentioned earlier, it becomes difficult to have complete data of the population in question due to various issues. However, to answer many questions, you need to understand the population. This is where the use of samples comes in handy.
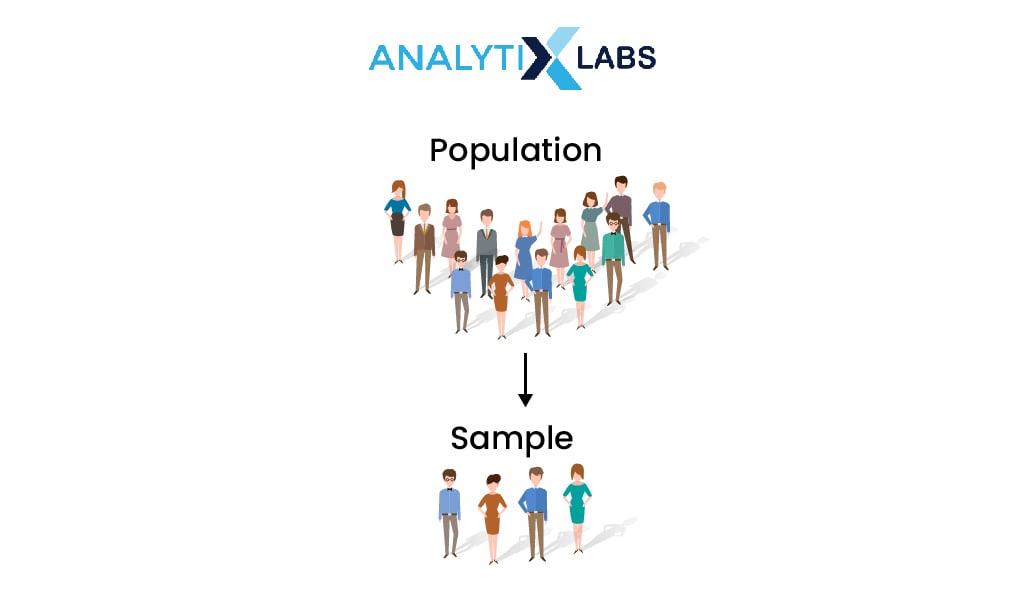
Samples are nothing but the subset of a population that represents the population due to a concept known as the central limit theorem.
4) Central Limit Theorem
To put it roughly, the Central Limit Theorem (CLT) states :
If you have a large enough number of samples, i.e., the sample size (large theoretically means more than 30), then the mean of all these samples will be the same as the mean of the population.
Another aspect is that the distribution of the sample (also known as the sampling distribution) will be normal (gaussian) even if the population’s distribution is not normal.
5) Distribution
Distribution (commonly called data distribution) is a function that states all the possible values of a dataset along the frequency (count) of all values (or intervals as the values can be binned in groups).
The distribution is often represented using graphs like a histogram and a line chart. Different distributions have peculiar shapes and specific properties that help calculate probabilities.
These probabilities are typically regarding the likelihood of a value occurring in the data that can then be extrapolated to form a larger opinion regarding the sample space and the population from where it has been drawn.
6) Types of Distribution
Distribution can be symmetric and asymmetric.
- Symmetrical distributional are those where the area under the curve to the left of the central point is the same as to the right.
- asymmetric distributions are skewed that can be positive or negative. Common examples include Log-normal.
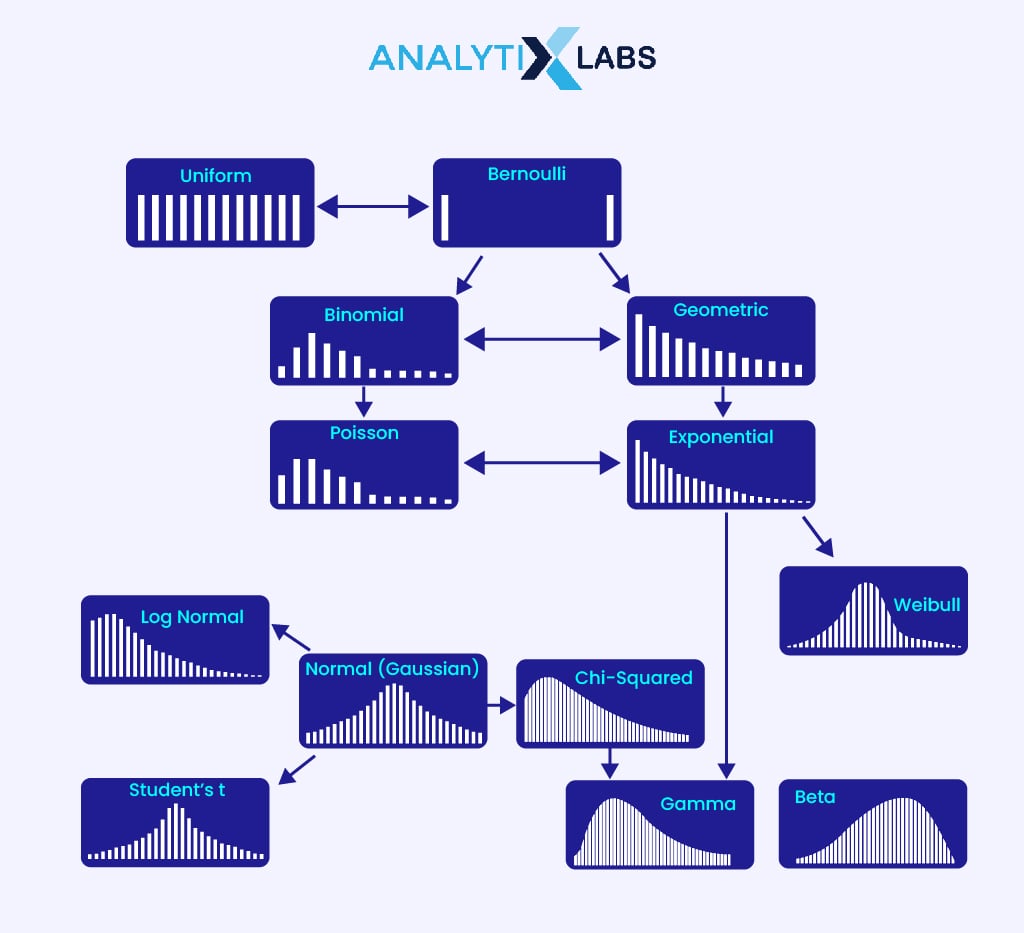
Another way of understanding symmetrical distribution in terms of shape is that there is no skewness as the right side of the distribution mirrors the left side. Common examples include Gaussian, Cauchy, Logistic, Uniform, etc.
7) Gaussian Distribution and the 3-Sigma Rule
CLT causes a large sample to have a normal, also known as Gaussian distribution. This refers to symmetric distribution that has a bell-shaped curve where the mean, median, and mode coincide.
Specific distributions have specific properties. One property of normal distribution is the three-sigma rule regarding the area under the curve (AUC) states that-

This concept is then expanded to calculate the probability of a value occurring in this distribution, which leads to hypothesis tests like the z-test.
8) Hypothesis Testing
Hypothesis Testing is an essential aspect of inferential statistics. As the name suggests, it is used to check if the hypothesis being made regarding the population is true or not.
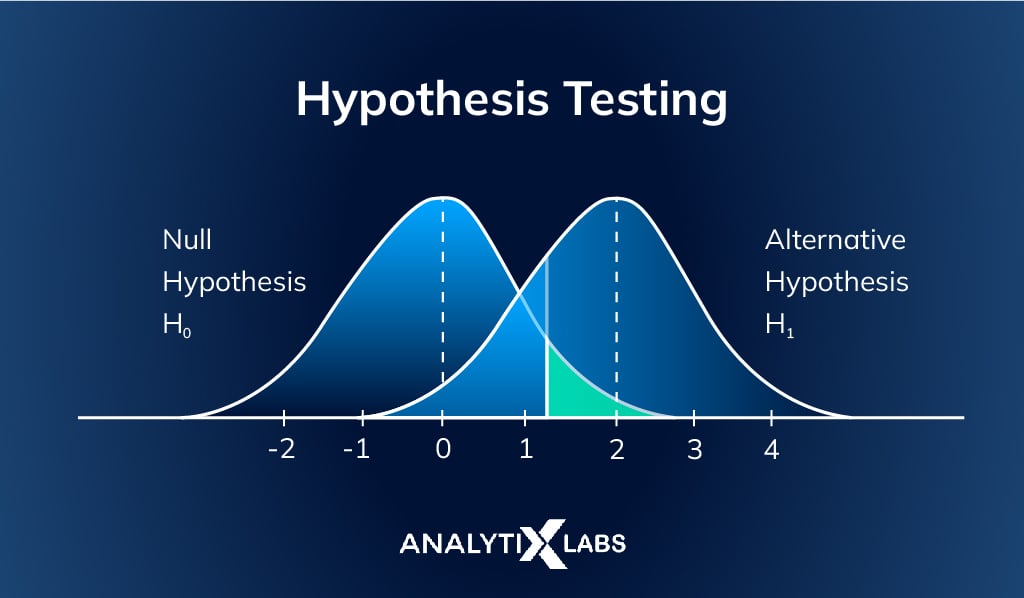
This is often done by calculating the probability of a value occurring in a population’s sample given the standard deviation in the data. Such tests help validate whether the statistics found through the sample can be extrapolated to form a particular opinion about the population.
9) Statistic
Certain arithmetic values that help define the population are known as parameters. However, as you often use samples, these values are known as statistics when calculated using a sample.
For example, if you know the income of all the Indians and you calculate the mean income from this population data, then this value will be a parameter.
However, when calculated using a sample of this population, the mean is known as a statistic.
To make sure the sample’s mean is truly indicative of the population mean and is not due to random chance, you use the concept of hypothesis testing.
-
Parametric Test: Definition
Parametric test in statistics refers to a sub-type of the hypothesis test . Parametric hypothesis testing is the most common type of testing done to understand the characteristics of the population from a sample.
While there are many parametric test types, and they have certain differences, few properties are shared across all the tests that make them a part of ‘parametric tests’. These properties include-
- When using such tests, there needs to be a deep or proper understanding of the population.
- An extension of the above point is that to use such tests, several assumptions regarding the population must be fulfilled (hence a proper understanding of the population is required). A common assumption is that the population should be normally distributed (at least approximately).
- The outputs from such tests cannot be relied upon if the assumptions regarding the population deviate significantly.
- A large sample size is required to run such tests. Theoretically, the sample size should be more than 30 so that the central limit theorem can come into effect, making the sample normally distributed.
- Such tests are more powerful, especially compared to their non-parametric counterparts for the same sample size.
- These tests are only helpful with continuous/quantitative variables.
- Measurement of the central tendency (i.e., the central value of data) is typically done using the mean.
- The output from such tests is easy to interpret; however, it can be challenging to understand their workings.
Now, with an understanding of the properties of parametric tests, let’s now understand what non-parametric tests are all about.
What are Non-Parametric Tests?
Let’s consider a situation.
A problem can be solved by using a parametric hypothesis test. However, you cannot fulfill the necessary assumption required to use the test. This assumption can be, for example, regarding the sample size, and there is nothing much you can do about it now.
So, would that mean you can’t do any inferential analysis using the data? The answer is NO.
In hypothesis testing, the other type apart from parametric is non-parametric. Typically, for every parametric test, its non-parametric cousin can be used when the assumptions cannot be fulfilled for the parametric test .
Non-parametric tests do not need a lot of assumptions regarding the population and are less stringent when it comes to the sample requirements.
However, they are less powerful than their parametric counterparts.
It means that the chances of a non-parametric test concluding that two attributes have an association with each other are less even when they, infact, are associated. To compensate for this ‘less power,’ you need to increase the sample size to gain the result that the parametric counterpart would have provided.
While it’s helpful in solving certain kinds of problems, it is difficult to interpret the results in many cases.
To put this in context, a parametric test can tell that the blood sugar of patients using the new variant of a drug (to control diabetes) is 40 mg/dL lower than that of those patients who used the previous version.
This interpretation is useful and can be used to form an intuitive understanding of what is happening in the population.
On the other hand, its non-parametric counterpart, as they use rankings, will provide output in terms of 40 being the difference in the mean ranks of the two groups of patients. This is less intuitive and helpful in forming a definite opinion regarding the population.
To conclude:
While nonparametric tests have the advantage of providing an alternative when you cannot fulfill the assumptions required to run a parametric test or solve an unconventional problem, they have limitations in terms of capability and interpretability.
Now, to gain a practical understanding, let’s explore different types of parametric and non-parametric tests.
Parametric Tests for Hypothesis Testing
To understand the role of parametric tests in statistics, let’s explore various parametric tests types. The parametric tests examples discussed ahead all solve one of the following problems-
- Using standard deviation, find the confidence interval regarding the population
- Compare the mean of the sample with a hypothesized value (that refers to the population mean in some cases)
- Compare two quantitative measurement values typically mean from a common subject
- Compare two quantitative measurement values typically mean from two or more two distinct subjects
- Understand the association level between two numerical attributes, i.e., quantitative attributes.
Parametric Hypothesis Testing: Types
|
When you need to compare the sample’s mean with a hypothesized value (which often refers to the population mean), then one sample z-test is used.
The test has major requirements, such as the sample size should be more than 30, and the population’s standard deviation should be known |
|
If either of the requirements mentioned above cannot be met, then you can use another type of parametric test known as the one-sample t-test.
Here if the sample size is at least more than 15 and the standard deviation of the sample is known, then you can use this test. Here the sample distribution should be approximately normal |
|
Paired t-test is used when from the same subject data is collected; typically before and after an event—for example, the weight of a group of 10 sportsmen before and after a diet program.
Here to compare the mean of the before and after group, you can use the paired t-test. The assumptions here include groups being independent, the values of before and after belonging to the same subjects, and the differences between the groups should be normally distributed |
|
In situations where there are two separate samples, for example, the house prices in Mumbai v/s house prices in Delhi, and you have to check if the mean of both these samples is statistically significantly different not, then a two-sampled t-test can be used.
It assumes that each sample’s data distribution should be roughly normal, values should be continuous, the variance should be equal in both the samples, and they should be independent of each other |
|
An extension of two sampled t-tests is one-way ANOVA, where we compare more than two groups. Suppose someone asks you if that is ANOVA a parametric test, the answer to that is a definitive yes.
ANOVA analyses the variance of the groups and requires the population distribution to be normal, variance to be homogeneous, and groups to be independent |
|
To understand the association between two continuous numeric variables, you can use a person’s coefficient of correlation.
It produces an ‘r’ value where a value closer to -1 and 1 indicates a strong negative and positive correlation respectively. A value close to 0 indicates no major correlation between the variables. A part of its assumption is that both the variables in question should be continuous. |
Non-Parametric Tests for Hypothesis Testing
In the above section, we talked about several parametric tests that can solve different types of statistical inferential problems. All those tests, however, are of the parametric types and have stringent assumptions to be taken care of, which you may or may not be able to fulfill. This is where non-parametric tests are helpful. Common types of non-parametric tests include-
|
It is used as an alternative to the one-sample t-test |
|
They can be used as an alternative to the two-sample t-test |
|
It is an alternative to the parametric test – one-way ANOVA |
|
You can use this test as an alternative to pearson’s correlation coefficient. It’s important when the data is not continuous but in the form of ranks (ordinal data) |
|
It is an alternative to the parametric test – paired t-test |
There are alternatives to all the parametric tests. So, if you cannot fulfill any assumptions, you can use their respective non-parametric tests.
Parametric vs. Non-Parametric Test
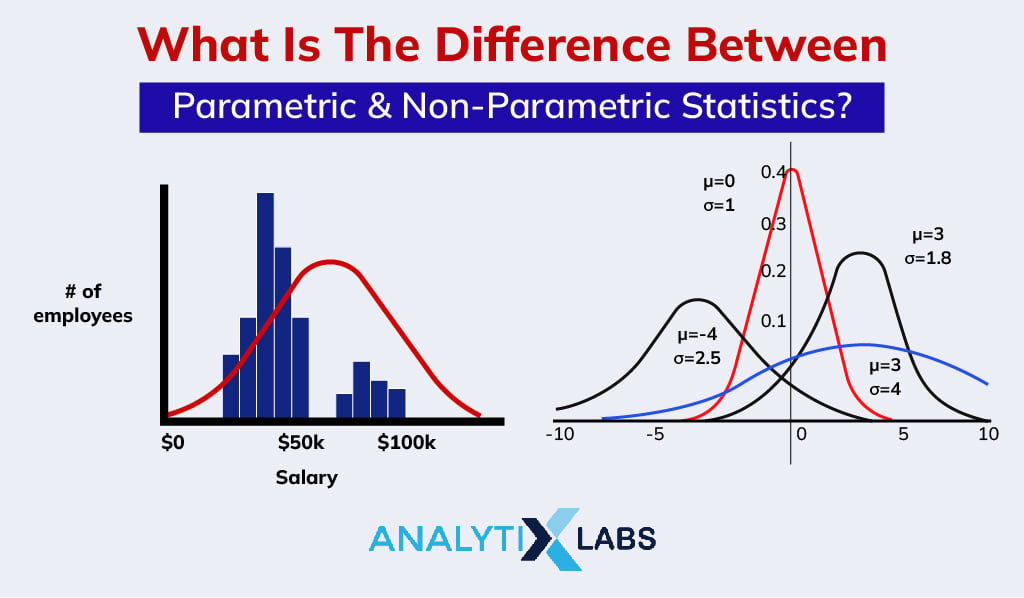
With the exploration of parametric and non parametric tests, it’s time to summarize their differences. The following table can help you understand when and where you should use the parametric tests or their non-parametric counterparts and their advantages and disadvantages.
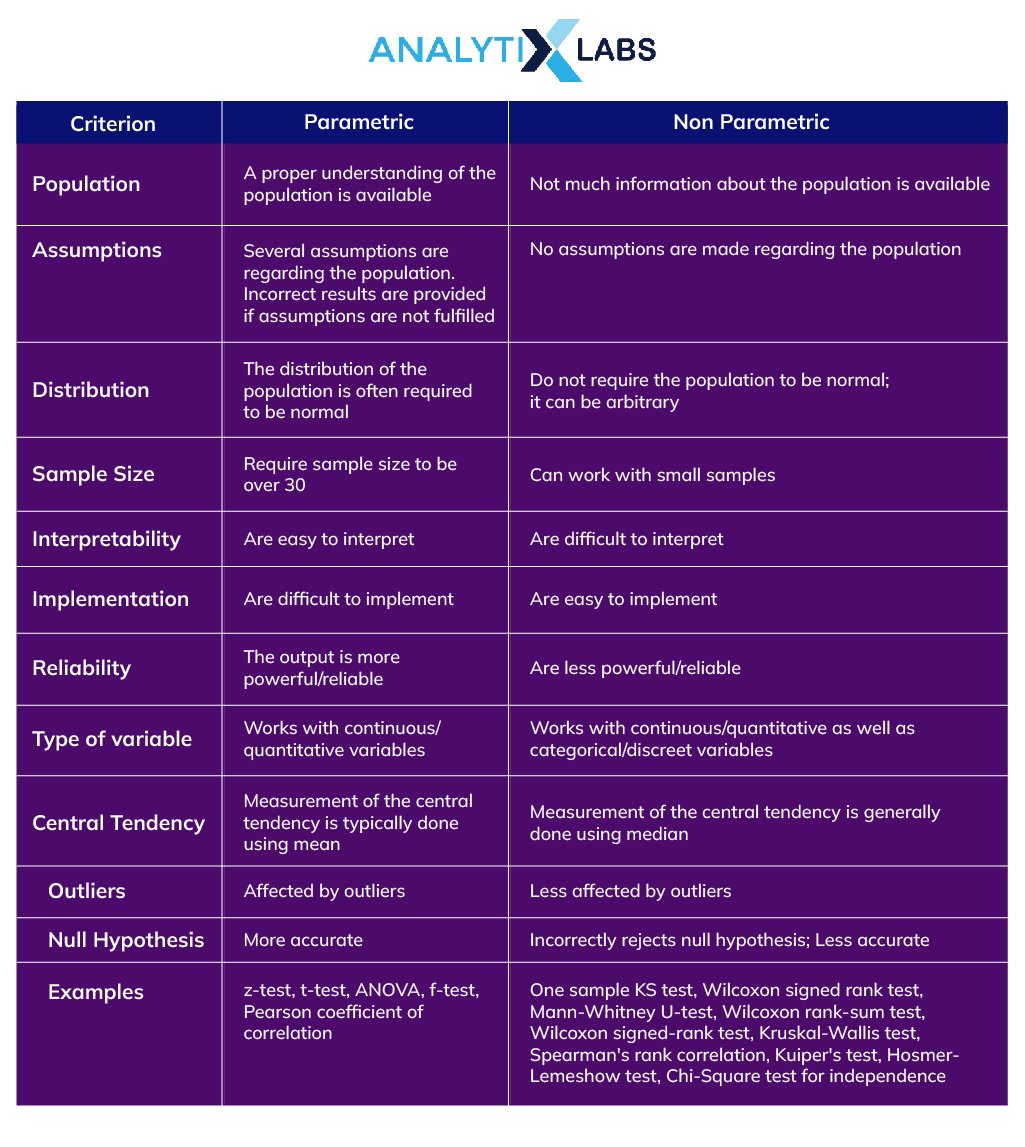
Now you have a better understanding of the differences between parametric and non-parametric tests and can use the type of test that suits your needs and can provide you with the best results.
FAQs
- What is parametric and non parametric test example?
There are parametric and non parametric tests that can be used when trying to solve a problem. When comparing a sample mean with a hypothesized value, one can use parametric tests such as a z-test, one sample t-test (if the sample size is less than 30), or non-parametric tests such as Wilcoxon signed-rank test.

If there is a need to compare the mean of two independent samples, then the parametric two-sample t-test can be used, or the non-parametric Wilcoxon rank-sum test or Mann-Whitney U-test can be used. Similarly, for almost every other parametric test, a non-parametric test can be used if the assumptions for the parametric test are not fulfilled.
- What are the four non parametric tests?
While there are several non-parametric tests, the four most common ones include-Two samples Kolmogorov-Smirnov test, Wilcoxon signed rank test, Mann-Whitney U-test, and Spearman’s rank correlation.
- Is ANOVA a parametric test?
Is ANOVA a parametric test – this is a pretty commonly asked question. ANOVA stands for Analysis of Variance. It’s a type of hypothesis test that, as the name suggests, analyses the variance to compare samples/groups.
There are many types of ANOVA tests, such as one-way ANOVA, two-way ANOVA, repeated measures ANOVA, MANOVA, etc. All these tests are parametric as they require (as part of the assumptions) for the population to be normally distributed, variables to be independent and random, and sample variance to be homogeneous.
- Is the chi-square test a parametric test?
Chi-square, also known as the goodness of fit test is typically used to test independence of two categorical variables. You must remember that chi-Square is a non-parametric test. There are numerous reasons for it, such as the variables being categorical (discreet), the groups being tested can be unequal (whereas parametric tests require the groups to be roughly equal), and the data having no homoscedasticity.
I hope this article has helped you understand what parametric and non-parametric tests are all about, when to use and when not to use them, and their advantages and disadvantages.
Try out the tests mentioned in the article to gain a better understanding. Languages like R and Python and statistical software like SAS and SPSS can be leveraged for this purpose. If you have any suggestions or feedback, please get back to us.






1 Comment
This article is highly informative and was able to answer all my questions about data analysis and interpretation