
SQL or Structured Query Language is undoubtedly one of the most versatile tools the technology industry has witnessed and the Data Science field is no different. In fact, SQL for Data Science is one of the top 3 skills that is most sought after alongside R and Python. It has ruled the tech industry for over four decades and continues to hold a strong base even today. If data is what you breathe and live, then SQL is your oxygen! Data is ubiquitous and so is SQL. The kingpins of the 21st century, Data Science and Machine Learning are very much leaned on SQL at various stages of its cycle so much so that SQL has become synonymous with data.
Like any other tool, mastering SQL for Data Science or in it is not an overnight miracle. It will certainly pay you healthy dividends to take a structured learning approach with consistency and guidance from experts with understanding this tool to its length and breadth; After all, it is a “Structured” Query Language! In this article, let’s explore what SQL is all about, how can one leverage SQL for data science, what is its role in Data processing and the learning approach to master SQL. Alright, let’s get started.
Why SQL: Relational Database Model
Let me start by giving you an analogy here. Let’s say I have two baskets, B1 and B2. B1 has some parts of toys like hands and legs while B2 has a trunk and head parts of these toys. These parts are not of just one toy, but multiple toys. The task is to integrate correct parts from B1 to that of B2 and make a meaningful toy; you can’t fit a Spiderman’s trunk to that of Batman’s head or Tom’s hand with that of Jerry’s!
So it is very essential to understand the correct relationship between various parts of toys. To do that, you may think of tying a unique tag to all the parts present in B1 and B2 that can correctly integrate parts from both baskets and form a meaningful toy. So what we are trying to do here is establish a meaningful relationship between the entities (parts of toys here) and derive meaningful insights out of it (the appropriate toy after integration).
The same analogy holds good in the case of data. A Relational model depicts an approach to handle and manage data that are stored as values in tables that are related to each other. A database houses these tables and in an organized and structured format in terms of the relational model is termed as a relational database. We need a software platform to host and define this database and such a system is called a database management system and a database management system that is based on the relational model that we just mentioned is called as a Relational Database Management System or RDBMS.
If you can think of data that fits neatly in a tabular form with proper rows and columns then such data is referred to as Structured Data and it is what relational databases have. The elegance of a relational model lies in its declarative nature; end users directly state what information they want from it and the database spills it out. The programming language that you use to state (query) what information you want from a structured data is referred to as a Structured Query Language or SQL; a language which data savvy people has long-lasting relationship with! Sounds confusing with so many terminologies?
No worries. The picture below should help you visualize how structured data relate to each other in a relational database model.
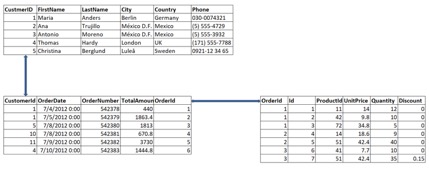
From the top, CustomerID ‘1’ refers to Maria Anders who has placed two orders bearing OrderNumber ‘542378’ and ‘542379’ with OrderID ‘1’ and ‘2’ respectively.
Finally, OrderID ‘1’ has three Products under its head with ProductIDs ‘11’, ‘42’ and ‘72’.
You see, how we are relating different data elements present in different tables of a database. Running them through queries will help us derive meaningful insights out of the data.
Essentially, SQL is used to retrieve insights from data present in a relational database. So, if you have information in a structured way, as a table with proper rows and columns, you have found every reason to use SQL! Using SQL you can:
- Create databases and tables and insert values into them. Simplicity with which you perform this is the key thing to note.
- Combine multiple data sets and derive powerful insights.
- Create reports. Standalone SQL queries can be written to fetch the data for preparing reports
- Perform a wide range of analysis on your data.
- Write automated scripts to perform data analysis and validation
- Fetch data, update contents of a table, or perform transaction level operations on databases, and many more.
The use list is very exhaustive and I have mentioned a few important ones above. There are many big players in the market who develop and vendors RDBMSs like the MS SQL Server, MS Access from Microsoft, Oracle DB from Oracle, DB2 from IBM, MYSQL and so on. Although, all of these are equally popular, MS SQL developed by Microsoft is a key player in the market of RDBMS. Let’s now explore a bit more on MS SQL server.
Getting started with MS SQL Server
SQL server or more commonly known as MS SQL server is a relational database management system developed and marketed by Microsoft. After ANSI (American National Standards Institute) deemed SQL as a universal language for querying relational databases, Microsoft released its first own version of SQL in 1988 by adding procedural programming layers as an extension to the standard SQL language. Microsoft’s philosophy of combining a high-performance database with an easy-to-use interface proved to be very successful making it the most popular vendor of high-end relational database management system software.
MS SQL server has two core components to it:
- Database Engine: This is the core MS SQL Server technology that creates and drives relational databases; the core service for storing, processing, and securing data. It doesn’t have any graphical interface; just a service running in the background of your computer (mostly and preferably on the server).
- Management Studio: This is a graphical tool for configuring and viewing the information in the database. It can be installed on the server or on the client (or both). It is a means for an end-user to interact with the database engine.
This is how an MS SQL Server Management Studio (SSMS) hosting a database engine looks like:
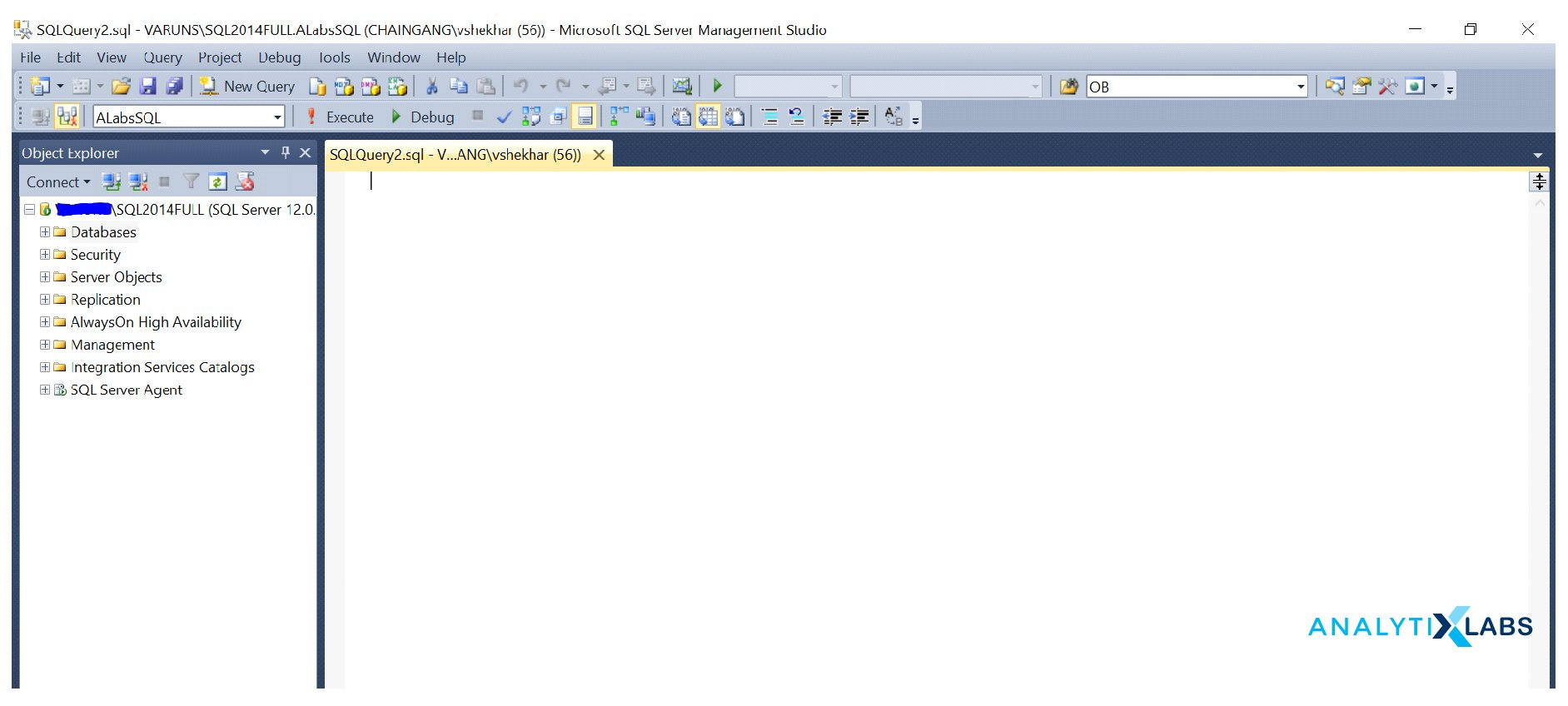
The outer Interface you see is the SSMS that houses database engine which you can see on the Object Explorer pane on the left (here, SQL2014FULL is the name of the database engine). The open space that you see to the right of object explorer pane is where you write SQL queries to extract results from data in a database.
Now, if you are a beginner to SQL and you want to master SQL for data science, your first priority should be learning the SQL language perse and not be choosy of learning an MS SQL or MYSQL or Oracle SQL. All these vendors have built their own version on top of the standard SQL language.
There is not much of a major difference in the way these RDBMSs operates. Although there are slight variations in the syntax of writing a query, more or less they all are same. So my first tip to you is to focus on learning the SQL language and not be vendor specific.
SQL for Data Pre-Processing
If you ask me one critical phase where most data science people should spend their time in, then it is Data pre-processing. Somebody once asked me, what is that one ‘wish-it-could-have-been’ thing for you as a data science person and my honest reply was getting a clean and tidy data from your client! Duh! It is not going to happen. From a data science point of view, it is very essential to pre-process the data before your start training your model with it.
Data pre-processing involves validating the data, subject to various parameters. Most of the data scientists spend 70-80% of their time on validating and ensuring clean data to be able to input to a model. Validating data may include trimming whitespaces in certain fields, converting null values into Blank or 0, segmenting data into regular records and outliers, getting initial and final counts, applying correction values to the fields that are required for modelling purpose and so on and it solely depends on the requirement and the kind of data your client submits. The end goal of Data pre-processing should be to ensure that your data is spick and span and is ready to go to the modeling phase.
If you are using SQL for Data Science, then SQL is a great tool that lets you pre-process your data using SQL queries. Let me take an example here to show you can perform data pre-processing in SQL. Here, I have created a transportation data of a retail store which consists of transaction-level data about shipments being hauled over a truck from an origin to a destination. The data consists of some quantitative characteristics and cost parameters associated with a given shipment and the data snippet (not complete) is as shown below:
(Please note: Data is for representative purpose only and is not affiliated to any organization/store)
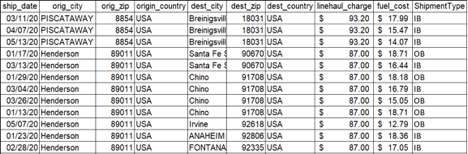
I will show you some SQL queries which can be used to pre-process the data. Let’s start with identifying shipments with invalid origin zip codes. You notice that, shipments originating or destined from/to US should have a 5 digit numeric zip codes, but there are certain shipments which may not conform to this. In such cases, we may need to have a reference database of zip codes using which we can correct this.
Select Shipment_ID, orig_zip from ShipmentData
where LEN(Orig_zip) = 4 and Orig_country = ‘USA’;
Select Shipment_ID, orig_zip from ShipmentData
where LEN(Dest_zip) = 4 and dest_country = ‘USA’;
After this, let’s examine if the line haul cost is within the allowable collar values. If they are not, then update them as Outliers with a comment saying: “Invalid Linehaul Cost”.
Update ShipmentData
Set Outliers = ‘Y’
where linehaul_cost < 50 and linehaul_cost > 2500;
Finally, let’s take a count of Inbound and outbound shipments. To do this, I make use of count() function in SQL and aggregate by ShipmentType column.
Select ShipmentType, Count(ShipmentType) from ShipmentData
where ShipmentType in (‘IB’, ‘OB’)
group by ShipmentType;
So looking at this simple example, I believe you are getting a fair idea of what data pre-processing means. In a real-time data set, this becomes very complicated and sophisticated in that we would be having a set of scripts, also called stored procedures in SQL (part of advanced SQL), to validate the data instead of standalone queries as shown above. So, for those of you, who are intending to use SQL for data science projects to pre-process your data here are my two cents:
- Spend a lot of time validating/pre-processing your data. Because the modelling stage does not do miracles and output correct estimates on a bad data. It heavily relies on the clean and validated data.
- Standalone queries work for ad-hoc works. In real time, it is always effective to club these standalone queries into automated scripts called stored procedures.
Also note that in languages like R/Python there are dedicated packages like tidyverse in R or pandas in Python to perform data cleaning operations.
Role of SQL in Machine learning
Just as a baby learns many things through experiencing, computer systems and machines have an ability to automatically learn and improve from experiences without being explicitly programmed. This is called Machine learning.
Machine learning is not something very new, it is just that this application of Artificial Intelligence (AI) has gathered huge prominence with easy access to store and handle data like never before.
Few decades back, Machine learning was just a stuff to be read in the books of science fiction. Today, from organizing your grocery items on the shelves to driving your cars, it is becoming an integral part of our lives!
With R and Python for data science being the most sought after tools, our veteran yet energetic SQL tool is reshaping itself to provide machine learning features in itself so that users get the convenience of training models close to the database, where data stays.
Machine Learning Services is a feature in Microsoft SQL Server that allows users to run Python and R scripts with relational data. You can use open-source packages and frameworks, and the Microsoft Python and R packages, for predictive analytics and machine learning. Although you have to still run Python/R scripts, the scripts are executed in the database without moving data outside SQL Server or over the network.
This is a very significant improvement to the existing SQL server because moving data outside the tool is a very expensive process, given the increasing size of data everywhere. Google Cloud provides an additional service called BigQuery ML which is specifically designed to perform machine learning tasks using standard SQL queries.
This has led to eliminating the need to move data outside the database, thereby increasing development speed. Oracle’s autonomous DB running in their cloud has built-in support for Machine learning without having the need to move your data outside the database.
It is very evident that existing RDBMS vendors provides a suite of options to include machine learning capabilities inside the database thereby increasing the development speed by eliminating the need to move the data outside the database. This makes SQL databases a reliable and competent tool to be used for data science.
Steps to Learn SQL for Data Science – SQL Course guide
Many entry level professionals jump dive into the million-dollar question: How to master SQL for data science? My two cents – Please do not start with this question. Instead you must start to understand SQL language as a whole irrespective of the streams you go. When you were a small kid, nobody taught you a speaking language specific to a person, first you learned the language as a whole, through further understanding and experience, you started adjusting your language according to the needs of a situation. Similarly, if you are a beginner for data science and learning SQL is one of the critical skills, I would strongly recommend you to learn the SQL language as a whole.
Honestly, there are lots and lots of SQL courses online so much so that one feels overwhelmed looking at it. Unfortunately, most of them start teaching SQL queries without giving a strong base knowledge of RDBMS system. This way, you may learn the language but not with a structured approach. Keeping this in mind, let me list out a recommended approach to learn SQL. This approach is based on my experience with SQL and a time tested one by the experts in the field. Let’s get started.
- Understand Relational Database Management System: SQL is all about relational models. SQL is used to manage and query data in relational databases. So, start with understanding RDBMS system. This will set the base for further learning. Do not make the mistake of starting your learning by writing SQL queries; you will end up like a half-baked food!
- Introduction to SQL: Once you are comfortable with knowing what an RDBMS system is, get introduced to the world SQL. Select a tool of your choice (any RDBMS vendor), install the application, get comfortable with the environment, understand how you connect the database engine to a client and finally, get your hands on to the hello world of SQL – The Select statement. Do not go into the depth of Select statement here.
- Understand how to define the data: SQL is broadly classified into three categories namely:
- Data Definition Language (DDL) statements
- Data Manipulation Language (DML) statements
- Data Control Language (DCL) statements
In this step, start with DDL statements. A primary requirement of any database is to have data upon which you can perform some analysis. DDL statements consist of query commands and syntaxes that will create and define the data. Data definition includes creating/dropping databases, tables, inserting data values into the table. Here, you will also learn how to alter the properties of a table including that of a column.
- Data Manipulation Language Statements: Once you get a good hold on data definition language statements, you move on to the crux of SQL; DML statements. This includes Select statement and its clauses. The Select statement and its clauses form the lion share of SQL. So having a detailed understanding of it is very important and essential to leverage full benefits of SQL for data science. Following are the clauses of a Select Statement:
- From Clause – defines the table from which you want to return the data from
- Where Clause – performs filtering operation
- Group By Clause – performs data aggregation
- Having Clause – performs filtering operations but on aggregated data
- Order By Clause – performs sorting operation
- Join Clause – Joins two or more tables related to each other using a linking field present in the participating tables
- Top/Limit Clause – Returns a defined number of rows either from top or bottom.
Each of these clauses has their own roles and responsibilities when it comes to performing manipulations on the data. An SQL select query can combine one or more combinations of these clauses. Utilization of all the clauses in a single Select query will help you to derive meaningful and more insightful results out of your dataset. To modify records that are already present in the table, Update statements are used. Update statements can be performed on a single table or multiple tables (in case of multiple tables, you use Update statements with Join clause). At times, there may arise a need for eliminating data from your table and to do this, Delete command is used perform this along with Where clause.
- Understanding Relational operators and Scalar functions: Learning DML statements as mentioned in the previous steps involves extensive usage of Relational operators like =, >, >=, <, <=, <> along with Boolean operators like AND, OR, NOT.
Scalar functions in SQL forms a very pivotal part of SQL. These are the functions which return single-valued output. These may include Numeric functions, String functions, and Date functions. These functions, although a bit tricky forms a very essential part of learning SQL for data science. Scalar function like String functions is extremely useful for text mining operation which is another handy feature for a Data Scientist. Although you may be attracted towards using a scripting language like R/Python for text mining operations, SQL is no less here as it hosts an exhaustive set of string functions to perform such operations.
Advanced SQL for Data Scientists

Following the above steps will cover the necessary grounds and gives you the required
knowledge to get comfortable with SQL. But that is not all yet. As mentioned in the beginning, SQL is one of the most sought after tools for data science alongside R and Python. So, for a data scientist, it is necessary to have a thorough knowledge of some of the advanced concepts in SQL so as to completely leverage SQL for data science. Below I will continue on the steps for acquiring knowledge on advanced concepts for SQL so that you are mostly equipped to take full leverage of SQL for data science. Let’s keep the ball rolling.
- Subqueries and Window functions in SQL: This forms the advanced part of SQL. As the name indicates, subqueries are queries within queries; a select query is nested inside another select query. They can be used to derive powerful insights when data is spread across multiple tables and where joins cannot be used or render slower execution rate.
Another secret armor in the SQL tool belt that you as a data scientist need to have is Window functions. If you have ever wondered how datacated (please don’t think of searching this in your dictionary!) professionals use SQL to solve real world problems like generating rankings, calculating moving averages, percentiles, running totals or performing time series analysis? Window functions are a powerful and an efficient way of handling these operations. Learning window function will give you an edge and will make you write an SQL query like a pro!
- Stored Procedures /Automation Scripts: More often than not, you will be tasked to run a set of SQL queries to perform data pre-processing or data wrangling operations. In that case, if you think you can run queries line by line or set by set, you are simply dragging yourself to the edge of obsolescence. If you don’t want this to happen, then learning to write stored procedures/automated scripts in SQL is your lifesaver. Stored procedure is a set of SQL queries which can be reused over and over again. So if you have SQL queries that need to be run over and over again, save it as a stored procedure, and then call it to execute it. Isn’t that cool? You bet it is. Stored procedures are an effective way to handle day-to-day data pre-processing operations in that you combine all your SQL queries into once script and execute it. This will be helpful for organizations that have multiple clients with a common baseline for handling data related operations.
- Cursors in SQL: At times there occurs a necessity of performing operations on one row at a time in a table. Cursors a great way to handle this. Usually SQL queries operate on all rows of a table. Using cursors one can perform data manipulations on one row at a time.
- Views in SQL: At times, you do not want to run your queries on the entire table. Instead, you would like to run your queries on a limited set of data. For example, a front end application need not always access all the set of data in the backend database but needs to have access on subset of this larger set. In such cases, we create virtual tables called views which consist of fields from one or more real tables in the database. Views are a very powerful way to do this.
- Linked server in SQL: A lesser known, yet powerful concept that a data scientist must be aware of is linked server in SQL. Many times, you need to read a data from an SQL table and write it into an excel file or vice versa, the linked server serves as a powerful tool to perform such operations via automated scripts. Here you are linking an SQL server to an excel or a CSV file and hence the name, Linked server. You use this a lot when you want to load data into database after scrapping it from a website or from an Excel or a CSV file. Personally, I use this a lot in my day to day operations with data when I have to perform read/write operations between SQL database and Excel files. A very handy tool indeed!
Phew! That was an exhaustive list of steps for mastering SQL first and then SQL for data science. Like any other tools, SQL is a progressive tool and you need to keep adding new functions, learn newer commands so that you will never fall short of becoming an SQL ninja for data science!
Frequently Asked Questions
Is SQL used for Data Science?
Yes, SQL is the most sought after tool alongside R/Python for data science. Databases are an essential part of data science. As long as there is data, so long will there be SQL. Many organizations have their data stored in relational databases and so you will need SQL to interact with such databases. I would even suggest starting with SQL, rather than with R/Python.
Which database is best for Data Science?
There are quite good number of database vendors in the market and they all are equally good. Microsoft SQL server, MYSQL, Amazon Redshift, Google BigQuery, PostgreSQL, Oracle all are good choices. So you must think in the lines of leveraging the chosen database than being very choosy on the vendor itself. Each of these has its pros and cons and it also mostly depends on the comfortability of the end user.
For instance, I have worked extensively on using MySQL, Microsoft SQL Server and Amazon Redshift. I should say all have been good in their own ways. Among these, I personally like using the Microsoft SQL Server. At the end of the day, every of these RDBMS vendors uses the standard SQL with some additional features of their own but as I said in this post, initially when you start, your focus should be on learning SQL by choosing any of these vendors and not be very specific of the vendor per-se.
How can I learn SQL for Data Science?
First, there are vast resources available on learning SQL so much so that you will end scratching your head which one to choose among the lot! Unfortunately, many of these do not cover in a structured and organized manner and it will be very difficult for a novice person to get started with learning SQL. There is good number of training institutes these days which caters to the learning needs of a candidate. When I started off my career with data science, I was fortunate enough to have chosen and got tutored under AnalytixLabs training institute which will help you learn excellent training skills with their Course in Data Science and PG course in Data Science.
There are a very few of such good training institutes, so do the homework properly before choosing one. Second, as I keep telling to the candidates, learn the language first; do not start learning SQL for data science or for a development project. Your first focus should be learning the language and then you can extend this learning to cater to the needs of Data Science. This post explains the steps to learn SQL for Data Science under the section Steps to Learn SQL for Data Science
How Databases are used in data science?
As long as there is data in ‘data science’, there will certainly be a need for databases. Database is essentially a repository of data. I can still live on this planet, but without a proper roof and basic amenities it becomes really difficult to lead my life on daily terms. Similarly, databases are a one-stop place to store and retrieve data from and are an integral part of a field like data science that lives and breathes data! To handle structured data, a data scientist needs to know about relational databases and how to handle and leverage them. So learning SQL is a quintessential part for every aspiring data scientist.
Finally, SQL is ubiquitous and pervasive in nature. The tool has ruled the technology industry for quite a long time and rendered commendable services to the world of data and it continues to stay strong and versatile amidst the likes of R/python. So get off the comfort of your couch and get started with SQL for data science!
Related:






2 Comments
Thanks for sharing the info it helped me a lot to gain a little more knowledge on the subject.
thank you for your information it really helped me a lot