
The global big data technology market is estimated to touch USD 116.07 billion by 2027. This is a huge jump from USD 41.33 billion in 2019, indicating a CAGR of 14% in the forecast period. Big data technology is growing at a rapid pace, and so is its adoption by businesses. As a result, the big data job market is brimming with opportunities, especially for talents having a niche. One such niche that a majority of job seekers are picking is to learn Hadoop and master it.
The framework is a bit complex to learn and challenging to work upon. However, with the right kind of guidance, you can master it.
This article answers trending questions like what are the prerequisites for Hadoop, who should learn Hadoop, what are the essential Hadoop tools, career prospects after learning Hadoop, and enlightens the use cases.
Why Learn Hadoop?
Hadoop is a revolutionary technology that has brought transformations in the procedures of compiling and analyzing vast data stores collected by businesses over time. It stands for ‘High Availability Distributed Object Oriented Platform’.
An open-source software framework, Hadoop, stores data and processes extremely large datasets in a distributed computing environment. It offers its developers higher availability of data by providing distribution of object-oriented tasks, this is done by allowing parallel processing over multiple clustered computers.
The Hadoop ecosystem is designed to scale linearly from a single computer to numerous machines in the cluster, with each system granting local storage and computation.
- Implicitly Hadoop is used for data mining, log analysis, image processing, ETL (extract-transform-load), and network monitoring for data in gigabytes, terabytes, or petabytes from any location.
- Hadoop lets businesses seek answers to intricate questions providing comprehension for business operations, and bringing new product intuitions and recommendations.
The all-inclusive Hadoop library is capable of detecting and handling failures at the local level minimizing the risks of failure. It is an integrated ecosystem of Big Data tools and technologies which is increasingly being deployed for storing and parsing Big Data.
- Hadoop permits scalability in parallel jobs to execute from single to numerous servers without delay.
- It provides a distributed file system increasing data accessibility and file transfer over different nodes in reduced time.
- Node failure does not impact the computation.
Hadoop: History
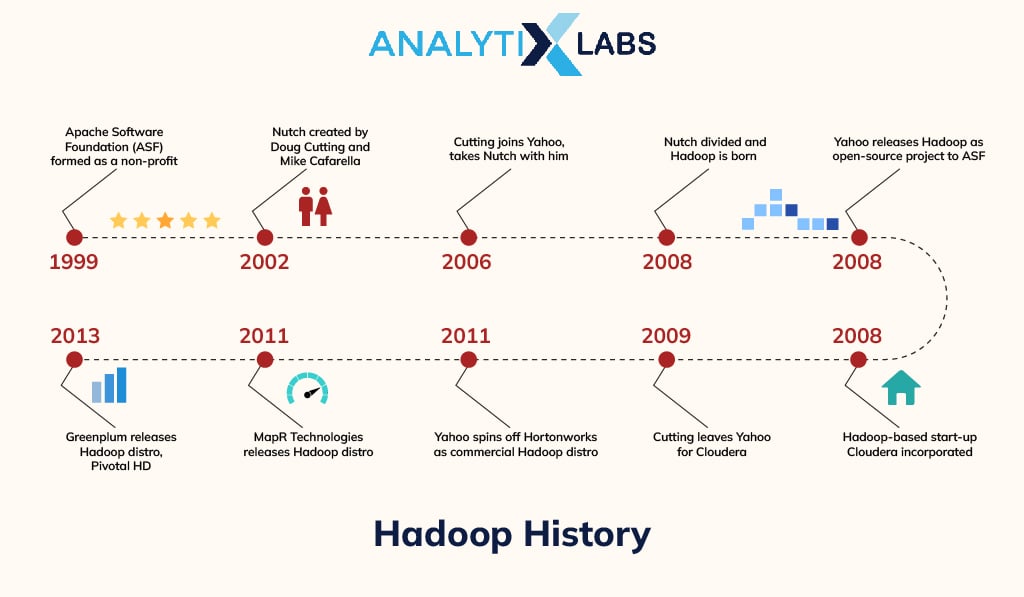
Hadoop was named after a yellow elephant toy by Doug Cutting, who was working with Yahoo at that time. Doug’s then-toddler son called his stuffed elephant toy as ‘Hadoop’ when Doug was building Hadoop.
Cutting and Mike Cafarella aimed at developing faster search results by using distributed data and calculations over different computers to allow multiple tasking.
Hadoop was initially a part of the Nutch search engine project which later separated as a distributed computing and processing unit from the large web crawler project.
Hadoop was released by Yahoo as an open-source project in 2008. It is maintained by a non-profit, global community for software developers and contributors Apache Software Foundation.
Is Hadoop Easy to Learn?
It is easier to learn Hadoop if you have prior programming skills. It is essential you pick a Hadoop Starter pack that will cover programming skills, analytical skills, and cloud service. You can opt for self-learning or enroll yourself in an online program with premium institutes that has a comprehensive curriculum covering all the basics.
N.B. Take a free demo with our experts for our comprehensive course on Big Data Engineering covering all basics and advanced concepts.
How to Start Learning Hadoop?
Hadoop with its flexibility, scalability, and adaptability is one of the most dominant data analytics platforms. Data-driven businesses and the big data revolution have generated numerous job opportunities leading many aspirants to start training themselves for the Hadoop platform.
Components of Hadoop to learn
Also read: Apache Flink: Hadoop’s new CousinThere is no specific Hadoop prerequisite to start learning, but a background in computer science, mathematics, or electronic engineering can help you learn the components of Hadoop faster. Below are the modules of Hadoop and what they do:
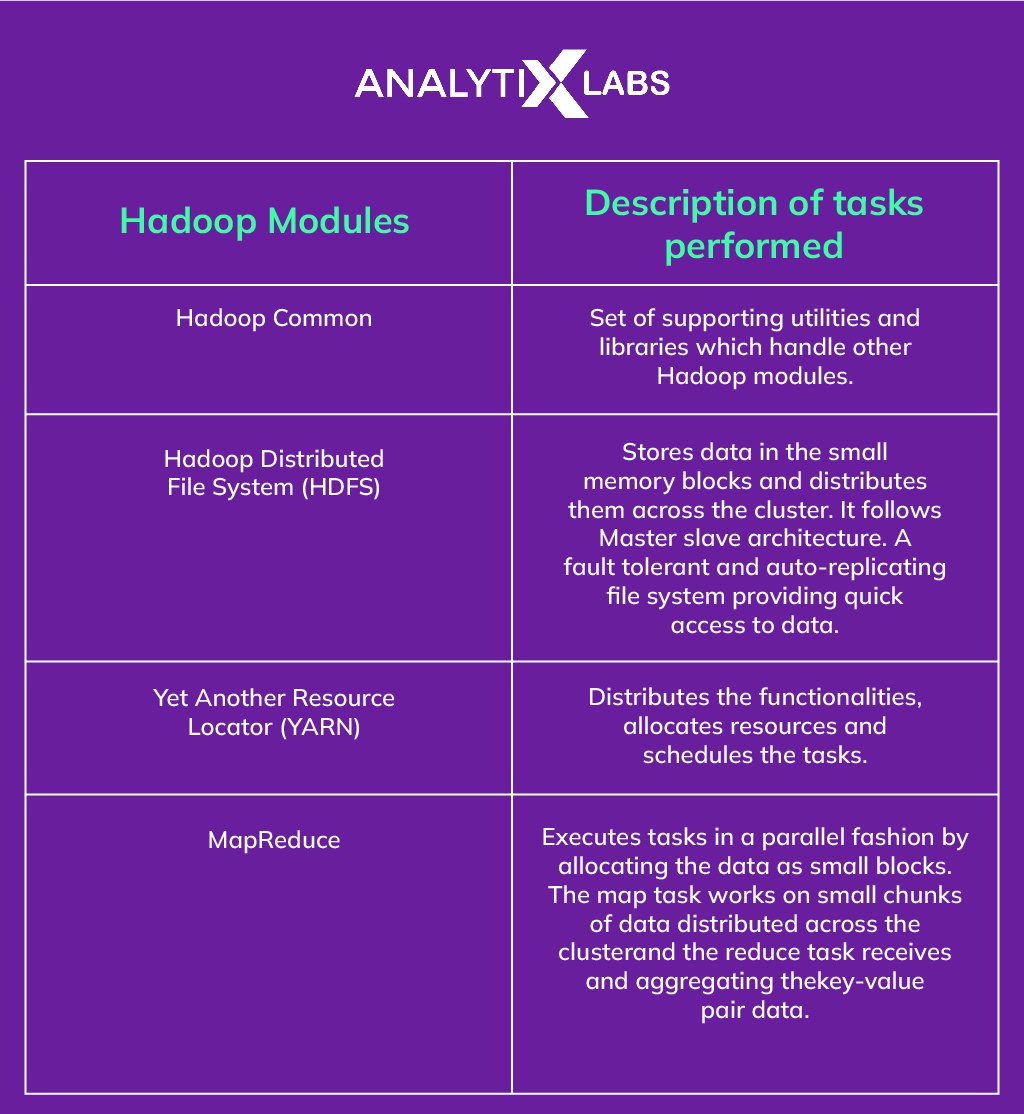
Hadoop Learning Pre-requisites
Although there are no strict requisite skills to be an Apache Hadoop developer , having a knowledge of some basic fundamentals listed below can help you in learning Hadoop more easily.
Also read: Hadoop Training: Things You Should Know Before Your Training- Core Java programming: It is not a strict requirement as Hadoop instructions can be written in various programming languages like C, Ruby, Java, and Pearl. Knowing the fundamentals of Java can help you understand the procedures behind various Hadoop applications like MapReduce, Pig, Hive, etc.
- Linux: Hadoop cluster is implemented and managed using Linux operating system, so knowing basic Linux commands can help you operate easily over the HDFS (Hadoop Distributed File System).
- SQL: Having prior knowledge of Structured Query Language can benefit the data processing operations pursued in organizations. Even high-end data extraction tools like Hive, HBase, Cassandra, and Pig have command syntaxes the same as SQL. Thus, it becomes easier to develop an understanding of learning Hadoop skills.
- Big data Basics: Knowing the big data fundamentals is the same as diving into the sea to find a pearl. One should know the objective being learning Hadoop, dealing with the big data clusters is the main task after learning Hadoop. Thus knowing the basics will help you excel in your learning process.
Hadoop and Big Data
Massive data explosions over two decades have surpassed human capabilities of handling the data over the servers, giving the way to big data technologies.
Hadoop is an open-source distributed processing framework around which the growing big data ecosystem revolves. It is designed to support advanced analytics procedures like predictive analytics, data mining, and machine learning applications. Hadoop is proficient in handling different forms of structured and unstructured data.

The integration of Hadoop and big data technologies fulfills various data processing and computational requirements. Hadoop is an all-inclusive big data processing platform. It has proved its excellence in industries working on diverse data such as natural resources, manufacturing, IT services, banking, and financial sectors. The big data Hadoop prerequisites are already discussed above. Let’s look at how Hadoop is enabling the big data industry.
Also read: Choose the Right Type of Big Data and Hadoop Training SmartlyHadoop for Big Data Analytics
Considering the business needs and available data sources we can use Hadoop for analytics in the following ways.
-
Installing Hadoop framework in corporate data centers
Hadoop can be deployed in corporate data centers. It is a time-efficient and cost-efficient technique to use analytical procedures for business It also ensures data privacy and security for the business.
-
On-premise Hadoop provider
Another way of implementing analytics is by employing on-premise Hadoop service providers. They streamline the analytics process by granting necessary software, services, and equipment. It leverages business with better uptime, security, and privacy.
-
Utilizing Cloud-based services
In cloud-based Hadoop service, data and analytics execute on commodity hardware that is present on the cloud. The processing of big data is done at affordable charges but is accompanied by certain issues like outages, and security breaches.
Essential Hadoop Tools to Learn
Hadoop is a collection of various tools that perform different operations. Below is an overview of the Hadoop ecosystem.
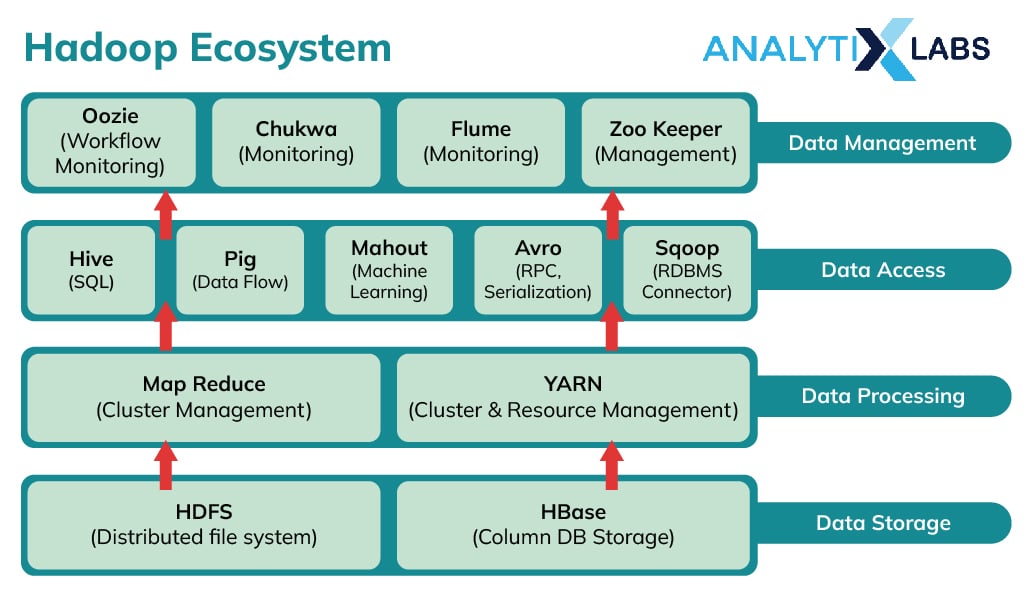
Ambari
It is a web-based tool that makes Hadoop management simpler. It consists of software for provisioning, managing, and monitoring Apache Hadoop clustersAmbari has a dashboard for observing the health and status of the Hadoop cluster. It has a Ganglia for the collection of metrics.
Hive
It is a data warehouse infrastructure that facilitates querying and managing large datasets stored in distributed storage using the SQL interface. It enables analytics at a massive scale while allowing distributed computing and fault-tolerant data warehousing solutions.
HBase
A distributed and scalable table-oriented database built on the peak of HDFS. It provides structured data storage for large tables. HBase handles rare data inputs effectively to ensure seamless big data practices. It is a modular and massively scalable store built to provide real-time access to tables with millions of rows and columns.
Spark
Apache Spark is an open-source framework for data analytics cluster computing. It works well with big data workloads. It uses in-memory cluster computing which permits users to store and trigger queries on the data repeatedly. It provides optimized execution, general batch processing, graph databases, and streaming analytics making it suitable for machine learning applications.
Presto
It is an open-source distributed SQL query engine that is optimized for low-latency, ad-hoc data analysis. It can process and handle data from multiple data sources including Amazon S3 and Hadoop distributed file Systems.
Pig
It is a high-level data-flow language and execution framework for the analysis of large data sets. Having the property of explicit encoding, large-scale parallel computing, and extensibility helps in achieving higher performance.
Sqoop
It is a tool that allows data transfer between Hadoop and different data stores. Data from relational databases like Oracle, and MySQL can be transferred into HDFS, further converted into Hadoop MapReduce, and later exported back to the RDBMS. It controls the import mechanisms and parallelism.
ZooKeeper
It is a centralized tool used for configuring, naming, grouping, and synchronizing Hadoop clusters.ZooKeeper provides services used in distributed applications making them fast, reliable, fault-tolerant, and providing synchronization primitives.
Mahout
Implemented using the MapReduce paradigm over the top of Apache Hadoop, Mahout is a library of scalable machine-learning algorithms. It is named after the person who guides the Elephant: ‘Mahawat’. As an analogy, it coordinates the operations of the Hadoop ecosystem. It executes machine learning algorithms like collaborative filtering, classification, and clustering.
GIS tools
It is a set of tools that help in managing the geographical components of the data. The Geographic Information Systems for Hadoop has adapted java based tools for handling geographic queries by using coordinates.
Java essentials for Hadoop
Java is not a strict Hadoop pre-requisite to start learning it. However, learning the basic concepts of core java can help you develop a better understanding of the Hadoop interface.
- Object-Oriented Programming concepts like Objects and Classes
- Reading and Writing files
- Error/Exception Handling
- Arrays
- Collections
- Serialization
- Control Flow Statements
- Multithreading
- Inheritance and Interfaces
Hadoop: Career Scope
Large enterprises are using Hadoop to apply big data analytics on petabytes of data. The large consumer base offers lucrative job positions for Hadoop and big data developers.
The career path of a professional starts with an undergraduate degree and learning the basic skills required. Taking up courses and certifications adds up to the knowledge of Hadoop. Working on the projects helps in gaining hands-on experience with the platform.
Top three reasons to choose Hadoop as a career option are listed below.
- Demand for skilled professionals:
According to a report by NASSCOM, the Big Data analytics sector in India is expected to achieve USD 16 billion by 2025. This will generate the need for skilled Hadoop developers and big data developers. Learning Hadoop tools like Pig, Hive, HBase Cassandra and others can be of advantage for professionals.
- Higher market opportunities:
Hadoop is a fully functional big data processing platform offering numerous career opportunities in various sectors like finance, healthcare, energy, retail, etc. With proper knowledge and proven certifications of the Hadoop platform, an individual can job as following roles.
-
- Hadoop architect
- Hadoop developer
- Big Data analyst
- Hadoop administrators
- Hadoop tester
- Higher pay scales:
Hadoop and Big data offer hefty amounts of money for data analytics. Big data giants like Facebook and Microsoft are known for higher pay scales for Hadoop job roles. The average salary in India ranges from 7lacs to 25lacs based on experience and skills.
Hadoop Illuminated Use Cases
With a product as deep and wide as Hadoop, industries have uncovered numerous possibilities with its adoption. Social media, the banking sector, healthcare, online platforms, and eCommerce have used Hadoop for data storage, search engine optimization, target-based advertisements, and generating recommendations.
- Data Archives: The low-cost commodity hardware makes Hadoop useful in storing processing and combining transactional, social media, and streaming data. It allows enterprises to store low-key data that could be useful or analyzed in the future.
- Data Lake: To offer raw and crude data to data analysts, data lakes are used. It is easier for analysts to shoot difficult questions on the original data format, without any constraints.
- Sandbox for data discovery and analysis: Big data analytics on Hadoop can benefit organizations to work more resourcefully by uncovering novel opportunities and deriving unmatched competitive advantage. The sandbox approach delivers prospects to innovate with marginal investment.
- Energy discovery: Chevron Company uses Hadoop to categorize and process data from ships that sail in the ocean, the seismic data collected might indicate the presence of oil reserves.
- Internet of Things: IoT-based products are interactive and generate a data stream continually. Hadoop is used as a data store for these abundant transactions. Hadoop as a sandbox is used for the discovery and classification of patterns to be examined for prescriptive instruction by utilizing its massive storage and processing capabilities.
Conclusion
As a major development in the big data scenario, Hadoop has democratized computing power. Enterprises using the Hadoop platform can analyze and query extremely large datasets in a scalable, cost-efficient, and distributed manner. The growth prospects of the field raise a demand to learn and develop the Hadoop platform.
How to Learn Hadoop: FAQs
- Is Hadoop Java-based?
The Hadoop platform is java-based, and codes are written in both java and C language. Having a basic knowledge of object-oriented programming concepts, file structure, and error handling are enough to understand the ecosystem. Knowing advanced java concepts is not necessary but can be an added advantage in your role as a Hadoop developer.
- How long does it take to learn Hadoop?
Through self-learning, it can take 3-4 months to learn Hadoop, but by opting for expert training and certifications one can master Hadoop in 2-3 months.
- Is Hadoop good as a career option?
With the great demand for big data analytics and its wide acceptance in almost all industries, Hadoop job roles are of great attraction to learners. It offers various job roles with alluring salaries.
Happy Learning!





