
Each domain has a level of difficulty, which a person needs to assess before devoting their time and energy to it. At the same time, some fields, such as Astrophysics, have a reputation of being tough, while some other domains are perceived to be easy. This article aims to give the reader an understanding of the difficulty level of the field of Data Science.
A Brief About Data Science and Why it is Considered Hard
The sudden revolution in computers’ hardware capabilities and the spread of the internet have led to data being generated at a very high pace. This has caused different business sectors to store this data as now. The data hold the key to solving many business problems that seasoned business professionals could only solve earlier. Data Science can be understood as the scientific way of analyzing the data and creating predictive models that analyze the data’s underlying patterns and establish a relationship between the various variables and the target (something that is to be predicted).
Being a relatively new field, there is a lot of speculation regarding the difficulty level of this field. It has a reputation of being considered a tough field to break into. There are numerous reasons for data science to be considered hard, and while some reasons seem exaggerated, there are aspects of data science that may be considered challenging.

AnalytixLabs is the premier Data Science Institute specializing in training individuals and corporates to gain industry-relevant knowledge of Data Science and its related aspects. It is led by a faculty of McKinsey, IIM, ISB, and IIT alumni who have a great practical expertise. Being in the education sector for a long enough time and having a wide client base, AnalytixLabs helps young aspirants greatly to have a career in Data Science.
Is Data Science Hard? (What Makes It Difficult)
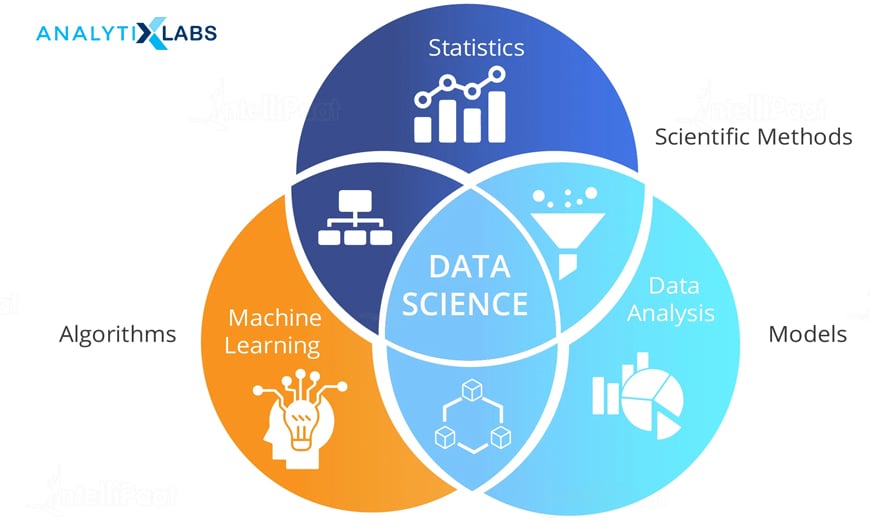
There is a particular reason because Data Science sometimes is considered hard, which is the demanding nature of this field. To gain expertise in Data Science, one needs to develop a good understanding of Mathematics, Statistics, Computer Programming, Visualization, Reporting, Business Understanding, Problem Solving, and Story Telling. As it is an amalgamation of multiple disciplines, this needs diligent efforts from any individual to master this field as one needs to gain knowledge of all these fields.
Aspiring Data Scientists are required to know mathematics and statistics as the numerous predictive algorithms use mathematical and statistical concepts, and to troubleshoot a model, these concepts should be known in depth. The tools of implementation are generally R and Python, and they require some coding skills.
Once the data is analyzed, it is important to understand its business implication and report it in simple, comprehensive terminology, using visual aids. Lastly, one must also explain the entire process of developing a model for others to scrutinize it and detect potential loopholes or understand where the business conclusion is coming from. All of this complexity causes Data Science to appear as a hard discipline of study. However, a good aspect of this is that no person can ever have all this knowledge prior. Thus, this field gives equal opportunities to all to try their hand in it, making it a unique form of study.

Is Data Scientist a Good Career?
There is a reason that Data Scientist is called the ”sexiest job of the 21st century”. The level of challenges that a Data Scientist faces, the level of exposure they get, and the extent to which it influences the decision-making in business make it a highly influential position. There is a scarcity of data scientists in the market, making it a great career path as it guarantees employment, and if one becomes a master of this field, then the sky is the limit of such data science enthusiasts.
Most importantly, apart from the high demand of Data Scientists, the level of compensation provided to Data Science professionals is higher than other high profile jobs as the average salary for a Data Scientist in India, for example, can be anywhere between 10 Lacs per annum to 25 Lacs per annum making it one of the most desirable jobs.

How To Start A Career in Data Science?
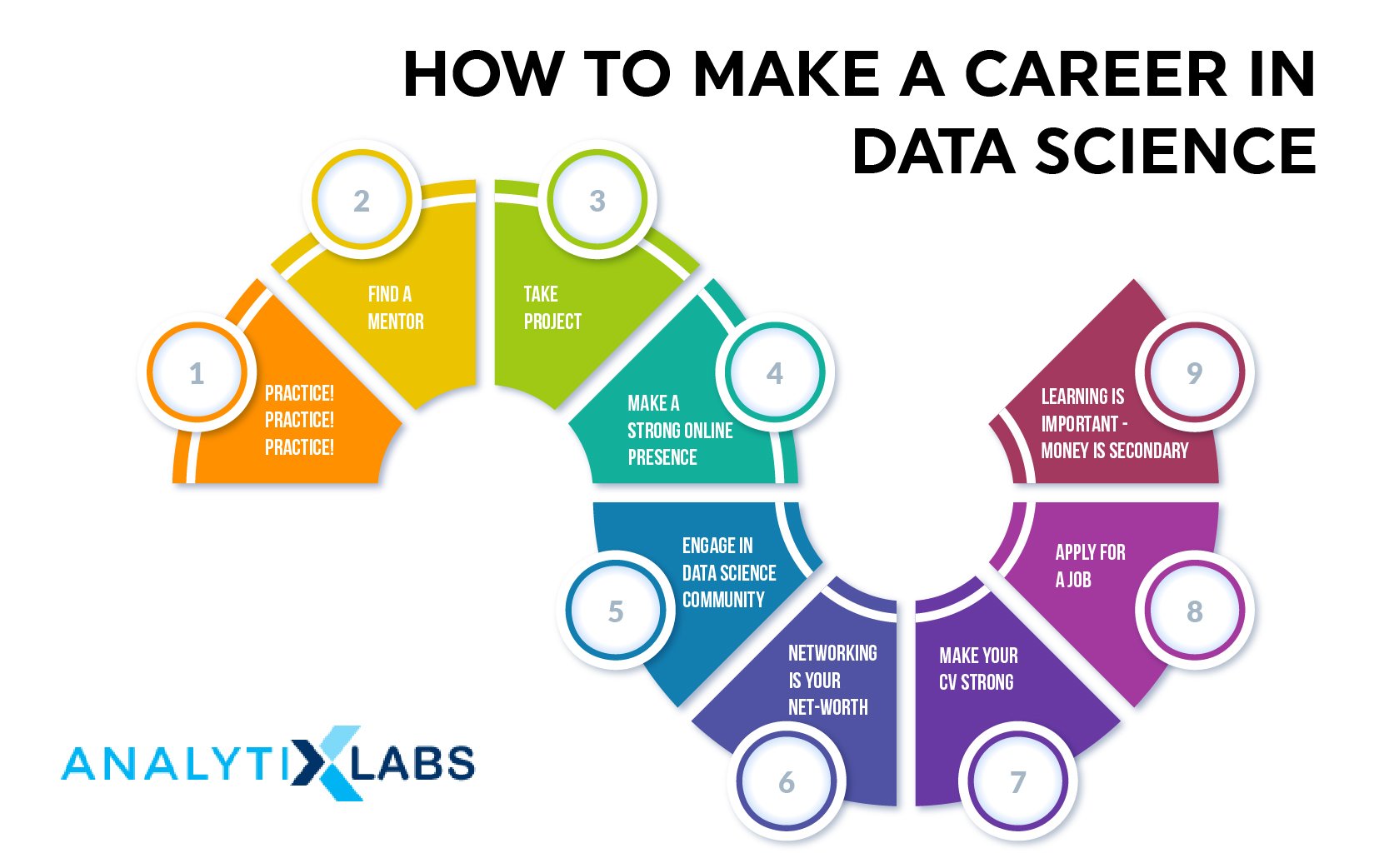
There are numerous ways through which one can start their career in Data Science. Some of the common methods include self-learning numerous aspects of Data Science such as Basic Statistics, Supervised and Unsupervised Learning, Feature Engineering, Data Mining, and Exploration, using common tools such as R and Python, the mathematics behind algorithms, model evaluation metrics, and validation methods. However, to gain some recognition, one can get certified as numerous platforms provide certification courses that help an individual gain some recognition.
Education platforms such as AnalytixLabs even provide placement assistance that can greatly help individuals start their careers in this field. There is also an option to complete a degree course in Data Science, either provided by foreign universities (mostly European or American) or some premium Indian Institutes. While this option can help increases aspirants’ job prospects, it is a costly and competitive option.
Related: How to Become A Data Scientist – Step By Step Guide
Does Data Science Require Coding?

Numerous tools provide Data Science-based solutions. Tools such as Rapid Miner and Power BI provide a GUI-based interface with drag and drop functionalities making it particularly easy for beginners to get exposure to this field. Some other tools, such as SQL and even SAS, use the quey-based approach to implement Data Science, which may be a little challenging to some, but as the queries are almost in plain English, it makes it again easy for a lot of individuals to learn. Still, to perform in-depth Data Science, dedicated advanced tools such as R and Python are required, clearly demanding their users to have some coding knowledge.
Python, which is programming or, as commonly known, a scripting language, requires the user to have a high-level understanding of computer coding. In contrast, R, a statistical language, also has its learning curve and needs focussed learning effort from people with no exposure to programming. Still, this should not be a cause of concern for Data Science aspirants. This computer coding is not of the same complexity as in other coding-based domains, such as application development.
You may also like to read: Is Data Scientist an IT Job | Learn About Various Roles & Skills
How Much Time Does It Take To Learn Python?

The level of coding required for implementing the numerous Data Science concepts can be easily learned in a few days and can be mastered in a few months, even for those who have never written a single line of code in their life. The reason for this short duration is that the common Data Science tools such as Python work as modular languages and use numerous Data Science-based packages, aka libraries or modules, to implement data manipulation and develop models that do most of the work internally, making the user write only limited lines of code. The main focus of learning any Data Science oriented tool such as python should be on the fundamentals as once they become clear, writing complicated codes becomes a much easy task.
You may also like to read: 10 Steps to Mastering Python for Data Science | For Beginners
Can I Learn Data Science On My Own?

The 21st century is the age of information; with the widespread availability of the internet and google, any individual can learn about almost anything (unless classified by government entities). There are video lectures of MIT and other prestigious institutions available online that anyone can view free of cost. On top of this, numerous YouTube channels are dedicated to making people learn of the different aspects of Data Science. Also, a good amount of e-books are freely available online that Data Science aspirants can exploit.
However, even with all of this, there is a major drawback with learning about such an advanced field on your own, which is the high chance of getting lost in the sea of information and losing sight of what is to be learned first and in what depth. Each aspect of Data Science requires its study, and one can go into as much of its depth as required. This can cause self-learners to get bogged down on certain topics and go into such depth that may not be beneficial, which results in a loss of time and unnecessary exhaustion.
The structure of learning Data Science or as commonly understood as curriculum, or the syllabus of Data Science, is the most important thing that can only be provided properly by professionals’ courses. Also, this field is demanding and often can raise various questions in learners’ minds. So the platforms, where learners can interact with the trainers are of immense value.
What Are The Different Domains In Data Science?
As mentioned earlier, Data Science is an amalgamation of multiple disciplines. While one needs to know all these disciplines to function as a Data Scientist, these disciplines also act as different domains in Data Science. Among the common domains include-
- Data Engineering and Data Management
The amount of data available for use has skyrocketed in recent times, and this has caused the requirement of professionals that specialize in storing a large amount of data, making it available when it is required, managing it, and making sure that the architecture of storing a large amount of data is efficient. The domain of Big Data and Data Engineering can be understood as a sub-domain of Data Science that deals with making the data available.
- Data Mining and Data Preparation
Once the data is made available before it can be analyzed, it must be prepared and mined, i.e., explored. All of this makes it a separate domain as there are certain techniques for exploring the data that require specialization on the data scientist’s part. Data Preparation includes extensive feature engineering that includes Missing Value and Outlier treatment concepts, among other things.
- Reporting and Visualization
After the data is mined, prepared, and analyzed, it becomes imperative to report the finding concisely. Here graphs and other visualization methods come in handy to explain a large amount of information with relative ease. Special tools especially deal with reporting, such as MS Excel, Power BI, and Tableau, that data scientists are expected to know for efficient reporting and visualization.
- Statistical Analysis
Statistics can be considered as the backbone of Data Science. It acts as a method to explore data and understand the relationship between the features that explain a great deal. Statistics in Data Science help in the majority of bivariate analyses. It also helps in understanding the performance of models and performing feature engineering such as feature reduction etc.
- Model Development
Algorithms are used to develop models, and specialization must understand these algorithms’ inner workings in-depth. While certain Data Scientists may take care of making the data available, preparing it, and performing basic analysis on it, there is a set of data scientists that is responsible for selecting the right statistical, machine learning, or deep learning model, tuning its hyper-parameters, and making sure that it fits the data properly. This domain of Data science is also responsible for the evaluation and validation of the predictive models.
- Industry-Specific Analytics
The domains of Data Science can also be understood in terms of the various business domains implemented. Among the most common industry-specific domains include-
1. Retail and Ecommerce
This is a customer-centric domain where customer 360 analysis is done. Customer behavior and buying patterns are analyzed, and recommendation systems are created for cross-selling
2. Logistics
With most of the buying happening online, markets getting connected across globes and increases global market dependencies had caused the movement of goods across countries and cities to become a common phenomenon. This creates a huge logistical challenge that can be solved by data science and its use of optimization and other algorithms.
3. Aviation and Hospitality
This sector requires management of inventory, where this inventory can be hotel rooms or flight seats. Additionally, reviewing and analyzing customer feedback is an important part of this business where data science concepts such as text mining and natural language processing play an important role.
4. BFSI (Banking Financial Services & Insurance)
Among the oldest users of Data Science, this domain still employs many Data Sceintsitst responsible for a range of activities, from predicting fraudulent and anomalous activities and customers to predicting potential loans, insurance, or investment amount, rate of interest, churn customers, etc.
Is Data Science Good For Freshers?

Data Science can be considered one of the best fields for freshers as it is relatively open to people from all backgrounds. As this field is relatively young, freshers are commonly considered given they showcase their capabilities properly.
Aspirants who are from STEM backgrounds can bank on their coding, mathematical or statistical skills. In contrast, Non-STEM aspirants can sharpen their business acumen, reporting, and visualization skills and can work their way up from there. Data Science being a vast field, requires multiple steps before a project can be fully executed.
These steps require expertise ranging from basic to intermediate to expert level. As most laborious tasks require basic and intermediate knowledge, there are always many opportunities in the field of Data Science. However, Freshers must create a plethora of projects and upload them on platforms such as GitHub and should engage in hackathons to brush up their skills and have something to explain in an interview.
You may also like to read: Data Science vs. Computer Science; Skills & Career Opportunities
Is Data Science An IT Job?
Technically, Data Science is not an IT job as it doesn’t only deal with programming languages and computers. There is a lot of knowledge needed on statistics, mathematics, model development, evaluation, and validation. On top of all this, to have any tangible conclusion, business knowledge is required. As Data Scientists are often required to communicate their analysis with people who may or may not belong to this field of Data Science, reporting and visualization skills are also required.
All of this makes it a non-IT field; however, still in popular culture, the job of a Data Scientist is regarded as an IT job. One of the reasons for this is its heavy dependence on computer languages such as Python and its proximity to Data Base Management Systems and Data warehousing. Also, with the advent of Big Data, the job of Data Scientist seems to look closer to IT; still, one must keep in mind the other aspects of Data Science, which are not so IT-oriented.
You may also like to read in more detail: Is Data Scientist an IT Job? Learn About Different Roles & Skills
Mistakes to Avoid While Beginning Your Career In Data Science
There are certain typical mistakes that beginners make while establishing their career in Data Science. These include:
- Paying more attention to the practical implementation of algorithms.
A common mistake that beginners make is that they get fascinated with the tools and focus on coding. Sometimes this can spiral out of control, and one can wind up learning to a program rather than learning the language for what is required, implementing Machine Learning and other libraries. The other part of this problem overlooks the practical aspects of Data Science, which can be disastrous. Without knowing the theory behind Data Science, one cannot fully implement or troubleshoot a project.
- Not learning the basics of the language.
As the languages used for implementing Data Science are modular in nature and extensively use libraries, beginners may be tempted to mug up the two three code lines that allow them to execute a model. This means that the basics of a language have not been provided with enough attention. This can create problems where there is a requirement to be innovative with the codes or identify syntax errors.
- Learning too many languages in a short period of time
A common misconception in Data Science is that tools can greatly affect the performance of algorithms or can make or break a Data Science career. However, the truth is that once a level is achieved, it doesn’t matter what tool a data scientist is using, i.e., it can be R/ Python or any other tool with similar flexibility and capabilities. Learning any two prominent tools are sufficient rather than too many languages in the anticipation to have the edge over others can sometimes be counterproductive as beginners can get confused with these languages and can be forced to mug up the syntax. Every Data Scientist needs to spend some time with their tool and get its hang before moving to any other tool.
- Not participating in Hackathons or not undertaking case studies.
Especially for beginners, it is important to get some hands-on experience, which is tough to get until a job opportunity or apprenticeship is available. Only focusing on some basic exercises or self-exploration can seriously limit the understanding of the concepts. Thus, participating in hackathons becomes important, which helps in building problem-solving skills. If the beginners are a part of a certification program, they must solve the provided case studies to gain pragmatism regarding the execution of projects.
- Shying away from online quiz and interviews
Until real job opportunities are presented, beginners must undertake as many online quizzes and interviews as possible. This prepares them for the uphill battle of going through numerous interviews and finding a job.
- Thinking they know or have to know everything
Lastly, it is possible that after going through hundreds of online lectures, some books, and few hackathons, one may get an impression that they know all the things about Data Science. However, this can and will turn out to be a fatal flaw in their learning as Data Science is a field that cannot be comprehended fully in a short or even medium amount of time.
Aspects such as Feature Engineering can take a couple of months of practice before all the aspects of a single topic are fully covered. So one must never quench their thirst for knowledge and should continuously learn and explore. Also, beginners must set their expectations realistically and must not expect to know everything and exhaust themselves.

With everything explained regarding the various aspects of Data Science, the conclusion that can be drawn is that the field of Data Science is unique. One needs to be very patient while learning about it as no one can become its master overnight or over a week. It takes months of hard work, discipline, and inquisitiveness before a level of understanding can be built.
FAQs
- Is Data Science easy?
Like any other field, with proper guidance Data Science can become an easy field to learn about, and one can build a career in the field. However, as it is vast, it is easy for a beginner to get lost and lose sight, making the learning experience difficult and frustrating.
- Is Data Science a good career?
With Data Scientists being in high demand and having above-average salary packages, Data Science for sure is one amazing career to be a part of.
- Is Data Science the future?
As the amount of data being generated continues to increase and the hardware and tools to handle it, Data Science has a bright future, especially as more and more domains are increasingly relying on Data Science for decision making.
Do let us know if you have any queries regarding the discussion covered in this article. It would be nice to have your take on this topic.
You may also like to read:
Data Science Tutorial for Beginners – Definition, Components and More
What Is Data Science Process, Steps Involved, and Their Significance?





