
This article can be considered a simple guide for understanding what a Support vector machine algorithm is and how it works in a Supervised learning setup in the Machine learning framework. Readers can expect to gain important information regarding the SVM algorithm from this article, such as what the algorithm is and hlassow it works, along with the crucial concepts that a Data Scientist needs to know before using such a sophisticated algorithm. This article will provide some understanding regarding the advantages and disadvantages of SVM in machine learning, along with knowledge of its parameters that need to be tuned for optimal performance.
Introduction: A Brief about Recent Trends
The recent changes in the world of computer and Business such as
- Advances in computer hardware and the growing availability and cheap cost of computer components such as RAM and GPU
- A large amount of labeled data being readily available and being generated on a daily basis
- Focus on predictive modeling and data analysis to make the business less vulnerable to unforeseen circumstances
- Growth of businesses that create tools as part of their core business functioning that solely rely on data science
- The growing importance of business decisions to be backed by properly analyzed data
- Internet of Things (IoT) generating huge amounts of data that needs to be constantly analyzed for various appliances to function smoothly and get regular updates
- The growing acceptance of predictive modeling in solving routine tasks
All such factors have resulted in the widespread acceptance of applying Machine Learning algorithms to solve day-to-day business-related problems.
While many algorithms can be used in the machine learning framework, they have their unique characteristics, advantages, disadvantages, and best use practices that data scientists need to understand before applying them to solve important business problems. Among these algorithms is an old, widely respected, sophisticated algorithm known as Support Vector Machines. SVM classifier is often regarded as one of the greatest linear and non-linear binary classifiers. SVM regressors are also increasingly considered a good alternative to traditional regression algorithms such as Linear Regression. To
AnalytixLabs is the premier Data Analytics Institute specializing in training individuals and corporates to gain industry-relevant knowledge of AI and Data Science. It is led by a faculty of McKinsey, IIT, IIM, and FMS alumni who have a great level of practical expertise. Being in the education sector for a long enough time and having a wide client base, AnalytixLabs helps young aspirants greatly to have a career in the field of Data Science.
What Is a Support Vector Machine?
In theory, the SVM algorithm, aka the support vector machine algorithm, is linear. What makes the SVM algorithm stand out compared to other algorithms is that it can deal with classification problems using an SVM classifier and regression problems using an SVM regressor. However, one must remember that the SVM classifier is the backbone of the support vector machine concept and, in general, is the aptest algorithm to solve classification problems.
Being a linear algorithm at its core can be imagined almost like a Linear or Logistic Regression. For example, an SVM classifier creates a line (plane or hyper-plane, depending upon the dimensionality of the data) in an N-dimensional space to classify data points that belong to two separate classes. It is also noteworthy that the original SVM classifier had this objective and was originally designed to solve binary classification problems, however unlike, say, linear regression that uses the concept of line of best fit, which is the predictive line that gives the minimum Sum of Squared Error (if using OLS Regression), or Logistic Regression that uses Maximum Likelihood Estimation to find the best fitting sigmoid curve, Support Vector Machines uses the concept of Margins to come up with predictions.
Before understanding how the SVM algorithm works to solve classification and regression-based problems, it’s important to appreciate the rich history. SVM was developed by Vladimir Vapnik in the 1970s. As the legend goes, it was developed as part of a bet where Vapnik envisaged that coming up with a decision boundary that tries to maximize the margin between the two classes will give great results and overcome the problem of overfitting. Everything changed, particularly in the ’90s when the kernel method was introduced that made it possible to solve non-linear problems using SVM. This greatly affected the importance and development of neural networks for a while, as they were extremely complicated. At the same time, SVM was much simpler than them and still could solve non-linear classification problems with ease and better accuracy. In the present time, even with the advancement of Deep Learning and Neural Networks in general, the importance and reliance on SVM have not diminished, and it continues to enjoy praises and frequent use in numerous industries that involve machine learning in their functioning.
You may also like to read:
1. What Is Classification in Machine Learning? Classification Algorithms
2. Different Types of Machine Learning Algorithms with Examples
How Does Support Vector Machine Algorithm Work?
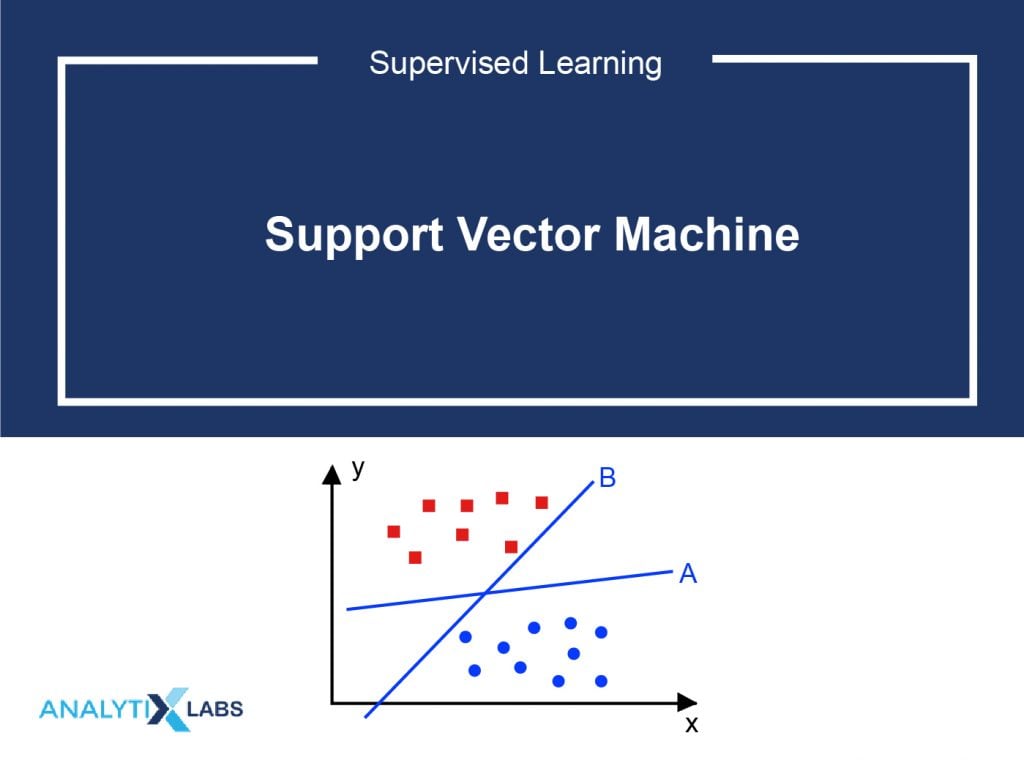
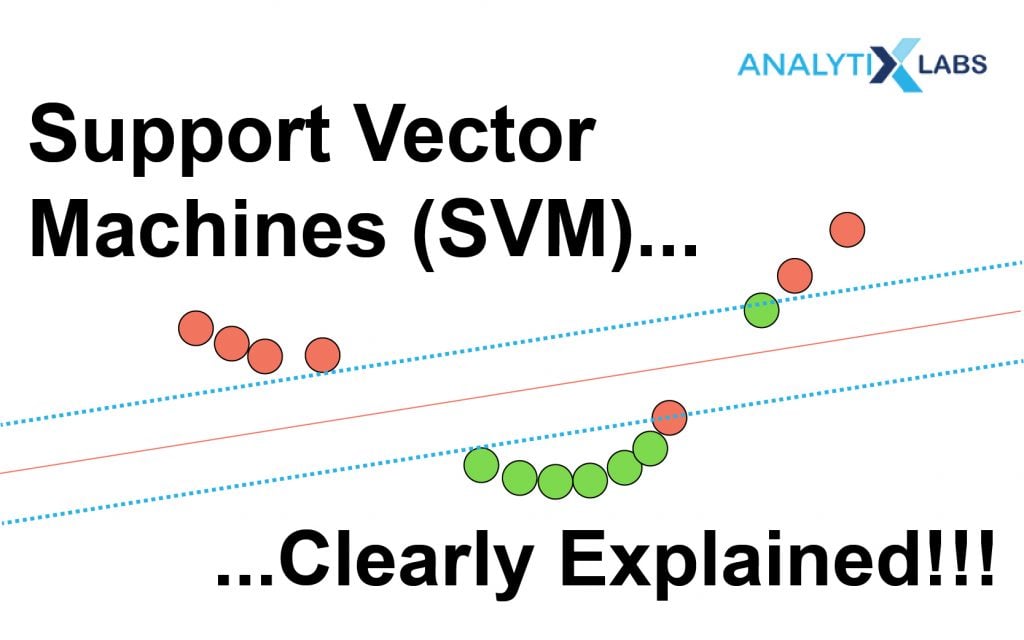
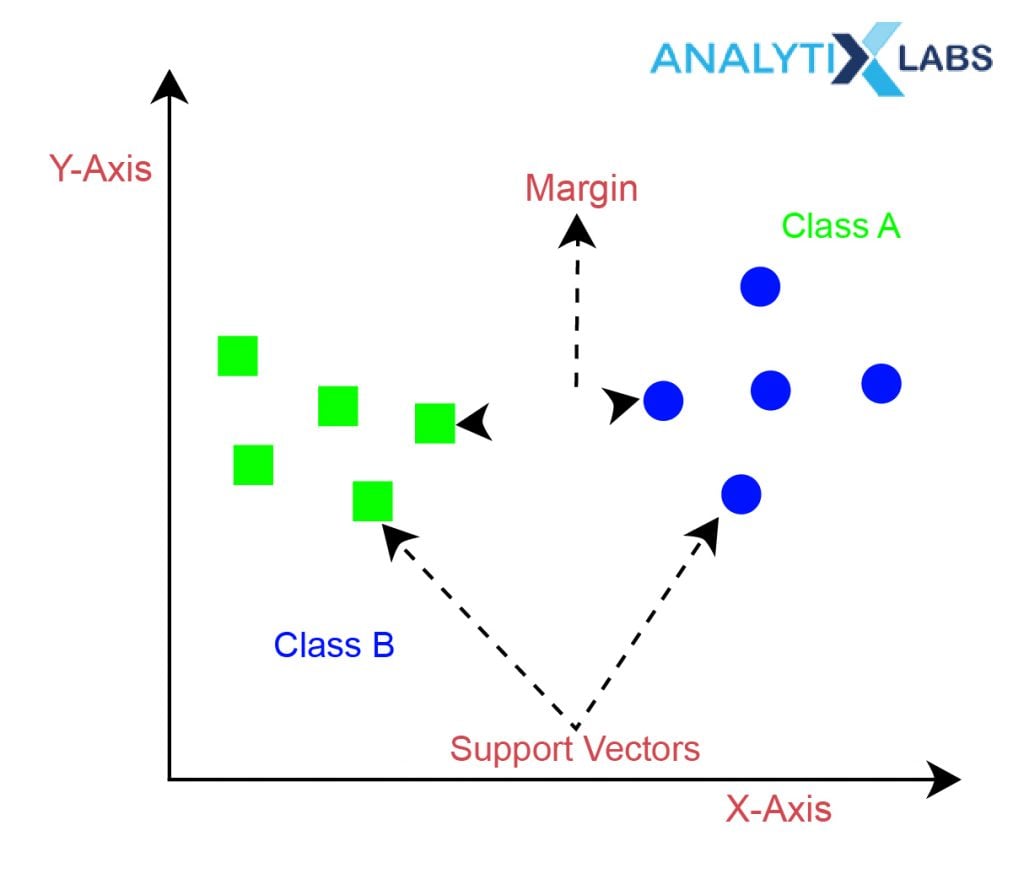
The best way to understand the SVM algorithm is by focusing on its primary type, the SVM classifier. The idea behind the SVM classifier is to come up with a hyper-lane in an N-dimensional space that divides the data points belonging to different classes. However, this hyper-pane is chosen based on margin as the hyperplane providing the maximum margin between the two classes is considered. These margins are calculated using data points known as Support Vectors. Support Vectors are those data points that are near to the hyper-plane and help in orienting it.

If the functioning of SVM classifier is to be understood mathematically then it can be understood in the following ways-
Step 1: SVM algorithm predicts the classes. One of the classes is identified as 1 while the other is identified as -1.
Step 2: As all machine learning algorithms convert the business problem into a mathematical equation involving unknowns. These unknowns are then found by converting the problem into an optimization problem. As optimization problems always aim at maximizing or minimizing something while looking and tweaking for the unknowns, in the case of the SVM classifier, a loss function known as the hinge loss function is used and tweaked to find the maximum margin.

Step 3: For ease of understanding, this loss function can also be called a cost function whose cost is 0 when no class is incorrectly predicted. However, if this is not the case, then error/loss is calculated. The problem with the current scenario is that there is a trade-off between maximizing margin and the loss generated if the margin is maximized to a very large extent. To bring these concepts in theory, a regularization parameter is added.
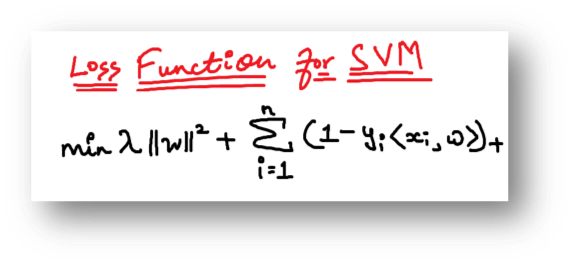
Step 4: As is the case with most optimization problems, weights are optimized by calculating the gradients using advanced mathematical concepts of calculus viz. partial derivatives.

Step 5: The gradients are updated only by using the regularization parameter when there is no error in the classification while the loss function is also used when misclassification happens.

Step 6: The gradients are updated only by using the regularization parameter when there is no error in the classification, while the loss function is also used when misclassification happens.
Important Concepts in SVM
The above explanation regarding the functioning of the support vector machines gives rise to a few phenomena and concepts that must be understood before we start applying SVM in the machine learning setup.
- Support Vectors
As mentioned earlier, support vectors are those data points whose basis the margins are calculated and maximized. The number of support vectors or the strength of their influence is one of the hyper-parameters to tune discussed below.
- Hard Margin
This is an important concept in the understanding of SVM classification and support vector machines in general. Hard Margin refers to that kind of decision boundary that makes sure that all the data points are classified correctly. While this leads to the SVM classifier not causing any error, it can also cause the margins to shrink thus making the whole purpose of running an SVM algorithm futile.
- Soft Margin
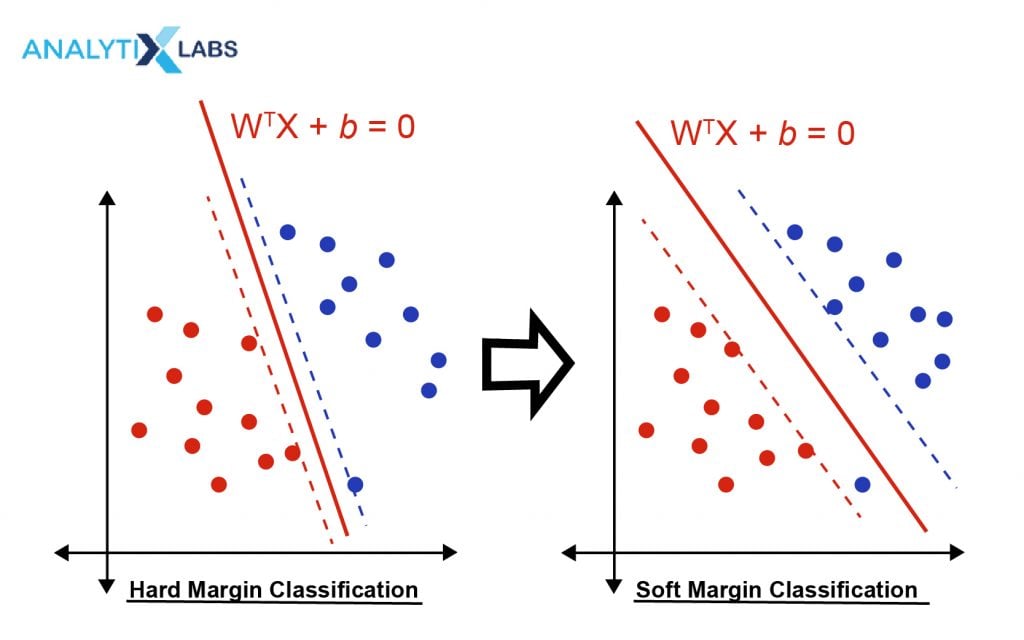
As mentioned above, a regularization parameter is also added to the loss function in the SVM classification algorithm. This combination of the loss function with the regularization parameter allows the user to maximize the margins at the cost of misclassification. However, this classification needs to be kept in check, which gives birth to another hyper-parameter that needs to be tuned.
- Different Kernels
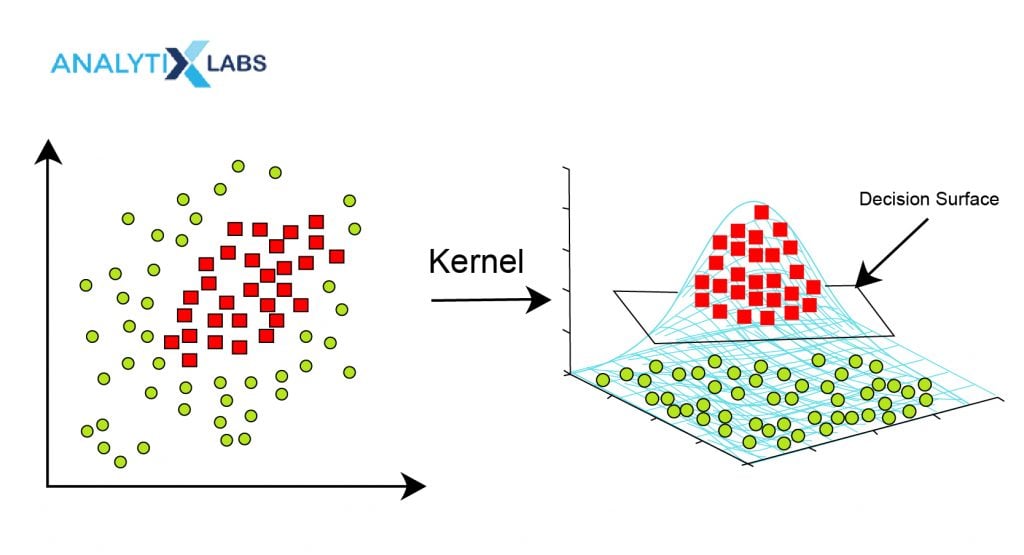
The use of kernels is why the Support Vector Machine algorithm is such a powerful machine learning algorithm. As evident from all the discussion so far, the SVM algorithm comes up with a linear hyper-plane. However, there are circumstances when the problem is non-linear, and a linear classifier will fail. This is where the concept of kernel transformation comes in handy. By performing kernel transformation, a low dimensional space is converted into a high dimensional space where a linear hyper-plane can easily classify the data points, thus making SVM a de facto non-linear classifier. Different types of kernels help in solving different linear and non-linear problems. Selecting these kernels becomes another hyper-parameter to deal with and tune appropriately.
How to Implement SVM?
SVM can easily be implemented in the majority of the commonly used tools used for predictive modeling. A good support vector example can develop an SVM classifier in languages such as Python and R.
Support Vector Machines – Implementation in Python
In Python, an SVM classifier can be developed using the sklearn library. The SVM algorithm steps include the following:
Step 1: Load the important libraries
>> import pandas as pd
>> import numpy as np
>> import sklearn
>> from sklearn import svm
>> from sklearn.model_selection import train_test_split
>> from sklearn import metrics
Step 2: Import dataset and extract the X variables and Y separately.
>> df = pd.read_csv(“mydataset.csv”)
>> X = df.loc[:,[‘Var_X1’,’Var_X2’,’Var_X3’,’Var_X4’]]
>> Y = df[[‘Var_Y’]]
Step 3: Divide the dataset into train and test
>> X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state=123)
Step 4: Initializing the SVM classifier model
>> svm_clf = svm.SVC(kernel = ‘linear’)
Step 5: Fitting the SVM classifier model
>> svm_clf.fit(X_train, y_train)
Step 6: Coming up with predictions
>> y_pred_test = svm_clf.predict(X_test)
Step 7: Evaluating model’s performance
>> metrics.accuracy(y_test, y_pred_test)
>> metrics.precision(y_test, y_pred_test)
>> metrics.recall(y_test, y_pred_test)
Similarly, an SVM classifier can be created in R also.
Support Vector Machines – Implementation in R
Step 1: Load the important libraries
>> require(e1071)
>> require(Metrics)
Step 2: Import dataset
>> df <- read.csv(“mydataset.csv”)
Step 3: Divide the dataset into train and test
>> samp <- sample(1:nrow(df), floor(df)*0.7))
>> train <- df[samp,]
>> test <- df[-samp,]
Step 4: Fitting the svm classifier model
>> svm_clf <- svm(Var_Y~., data = train, kernel = ‘linear’, cost = 10, type = ‘C-classification’)
Step 5: Coming up with predictions
>> y_pred_test <- as.numeric(as.character(predict(svm_clf, test))))
Step 6: Evaluating model’s performance
>> accuracy(test$Var_Y, y_pred_test )
>> recall(test$Var_Y, y_pred_test)
>> precision(test$Var_Y, y_pred_test)
How to Tune Parameters?
As understood under the important concepts of SVM, there are mainly three crucial parameters that need to be tuned.
- Kernel
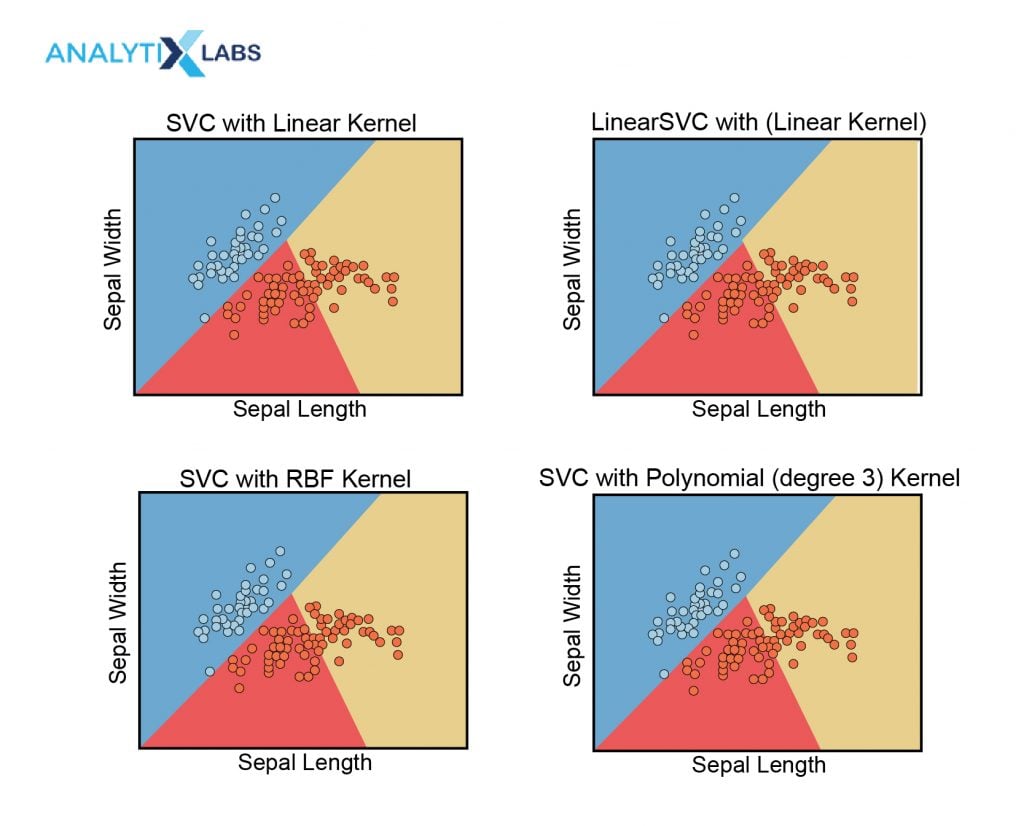
The use of kernel helps in transforming the input data into high-dimensional space which enables the SVM algorithm to solve non-linear classification problems. Apart from the usual ‘linear’ kernel, a number of kernels exist such as Polynomial, radial basis function (RBF) that enable non-linear classification.
- Regularization parameter
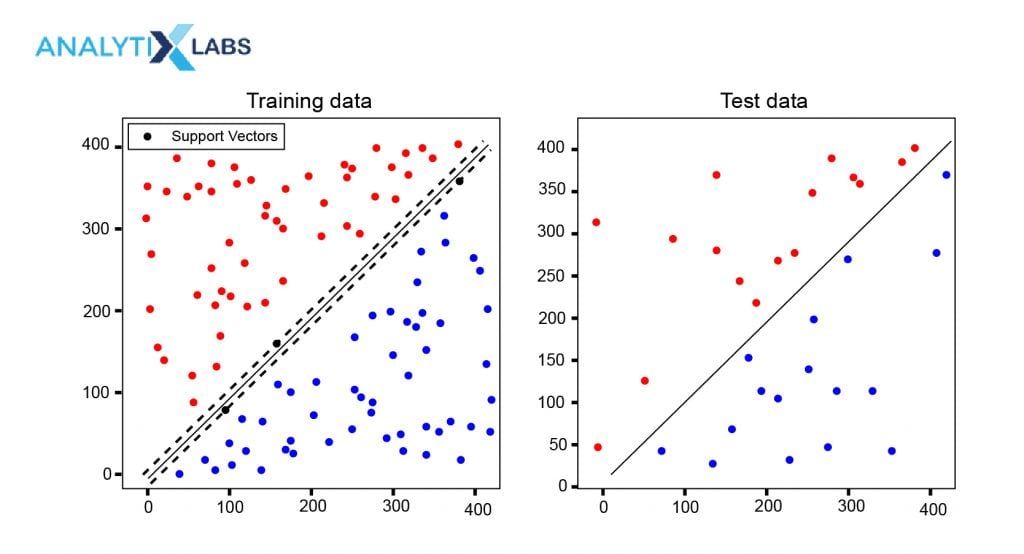
The ‘C’ argument in python’s Scikit-lean or the ‘cost’ argument in R’s e1071 provides the controlling knob to deal with the regularization. As discusses earlier, C is the penalty value that penalizes the algorithm when it tries to maximize the margins and causes misclassification. Thus, this value manages the trade-off between maximization of margin and misclassification. A lower value of ‘C’ means that a small margin is created, thus minimizing the error, while a large value of ‘C’ means a large margin is created that can invite misclassification.
- Gamma
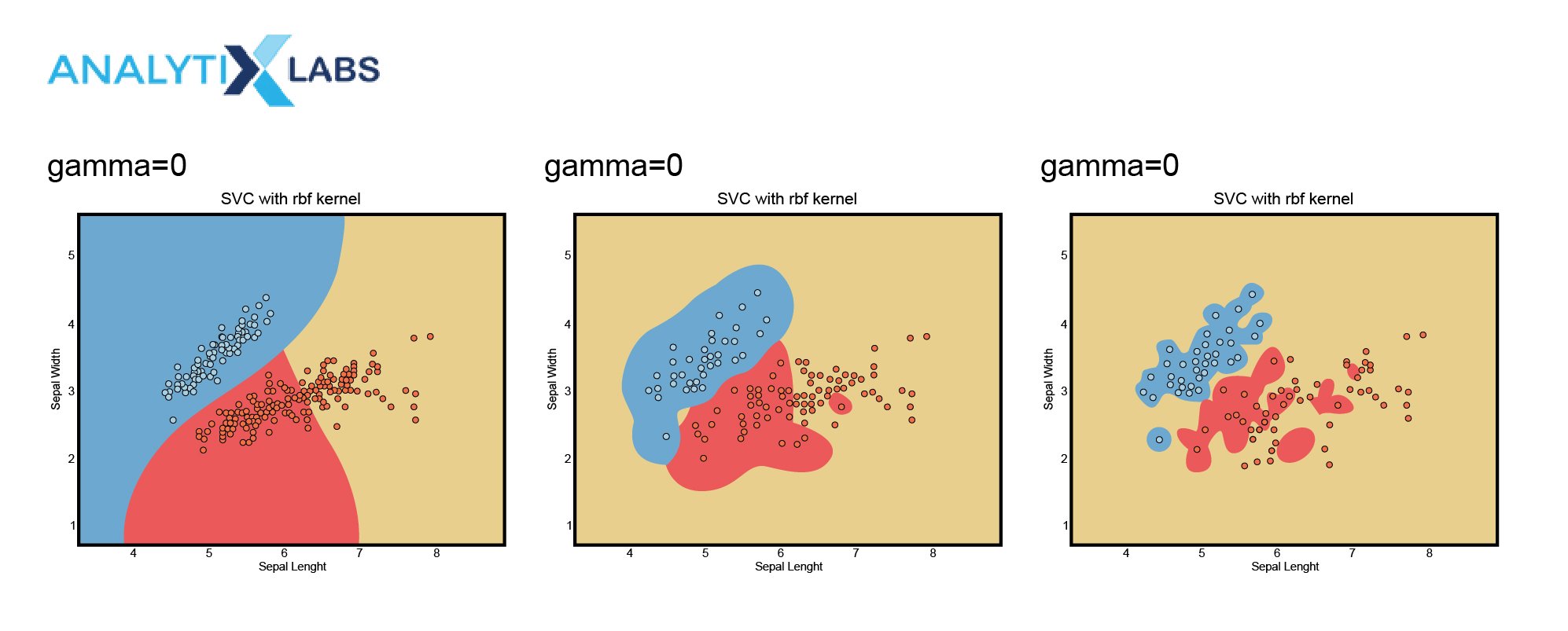
Be involved in the creation of the margins and consequently the hyper-plane. A small gamma value means that only a small number of data points close to the plausible margin line are considered making the model underfit. On the contrary, a large value of gamma causes a large number of even distant data points to be involved in calculating the separation line that can cause the model to overfit.
Thus, all these hyper-parameters need to be taken care of properly before an SVM algorithm is used to come up with predictions.
Advantages & Disadvantages of SVM
Each machine learning algorithm has its own set of advantages and disadvantages that makes it unique. The SVM algorithm is no different, and its pros and cons also need to be taken into account before this algorithm is considered for developing a predictive model.
Advantages
- Being a highly sophisticated and mathematically sound algorithm, it is one of the most accurate machine learning algorithms.
- It is a dynamic algorithm and can solve a range of problems, including linear and non-linear problems, binary, binomial, and multi-class classification problems, along with regression problems.
- SVM uses the concept of margins and tries to maximize the differentiation between two classes; it reduces the chances of model overfitting, making the model highly stable.
- Because of the availability of kernels and the very fundamentals on which SVM is built, it can easily work when the data is in high dimensions and is accurate in high dimensions to the degree that it can compete with algorithms such as Naïve Bayes that specializes in dealing with classification problems of very high dimensions.
- SVM is known for its computation speed and memory management. It uses less memory, especially when compared to machine vs deep learning algorithms with whom SVM often competes and sometimes even outperforms to this day.
Disadvantages
- While SVM is fast and can work in high dimensions, it still fails in front of Naïve Bayes, providing faster predictions in high dimensions. Also, it takes a relatively long time during the training phase. Many a time before SVM modeling you may also have use dimension reduction techniques like Factor Analysis or PCA (Principal Component Analysis)
- Like some other machine learning algorithms, which are often highly sensitive towards some of their hyper-parameters, SVM’s performance is also highly dependent upon the kernel chosen by the user.
- Compared to other linear algorithms such as Linear Regression, SVM is not highly interpretable, especially when using kernels that make SVM non-linear. Thus, it isn’t easy to assess how the independent variables affect the target variable.
- Lastly, a good amount of computational capability might be required (especially when dealing with a huge dataset) in tuning the hyper-parameters such as the value of cost and gamma.
With all its advantages and disadvantages, SVM is a widely implemented algorithm. Support vector machine examples include its implementation in image recognition, such as handwriting recognition and image classification. Other implementation areas include anomaly detection, intrusion detection, text classification, time series analysis, and application areas where deep learning algorithms such as artificial neural networks are used.
You may also like to read: How to Choose the Best Algorithm for Your Applied AI ML Solutions
Conclusion: Authors Opinion
Any Data Scientist involved in developing predictive models must have a decent knowledge of the working of Support Vector Machine. SVM is easy to understand and even implement as the majority of the tools provide a simple mechanism to implement it and create predictive models using it. SVM is a sophisticated algorithm that can act as a linear and non-linear algorithm through kernels. As far as the application areas are concerned, there is no dearth of domains and situations where SVM can be used. Being able to deal with high dimensional spaces, it can even be used in text classification. However, when dealing with SVM, one needs to be patient as tuning the hyper-parameters and selecting the kernel is crucial, and the time taken during the training phase is high.
To learn about more advanced Machine Learning Algorithms and their nuances, check out our Certification Course in Machine Learning in collaboration with IBM!
Other related topics you may be interested in:
1. Top 60 Artificial Intelligence Interview Questions & Answers
2. Top 45 Machine Learning Interview Questions and Answers






1 Comment
How can we do the same in MATLAB, please Sir?