
Machine learning in data science is a rapidly expanding discipline and now is the key element. This groundbreaking field equips computers and systems with the capacity to learn from data and improve their performance over time without explicit programming.
Statistical techniques are employed to train algorithms to produce classifications or predictions and to find significant findings in data mining projects. Ideally, the conclusions made from these insights influence key growth indicators in applications and companies.
In this article, we delve into the importance of machine learning, exploring its key applications, what is the need of machine learning, its benefits, and the transformative impact it has on our lives.
What is Machine Learning?
Machine learning term was coined by Arthur Samuel in 1959. It is the discipline solely focused on studying and building tools and techniques which can let machines learn. These methods use data to enhance the computer performance of a particular set of tasks.
Machine learning algorithms generate predictions or possibilities and create a model based on data samples, also called training data. There is a need for machine learning as these algorithms are applied in a broad range of applications, for example, computer vision, email filtering, speech recognition, agriculture, and medicine, where it is a challenge to create traditional algorithms that can accomplish the required tasks.
Categories in Machine Learning
Being such a vast and complicated field, machine learning is divided into three different categories:
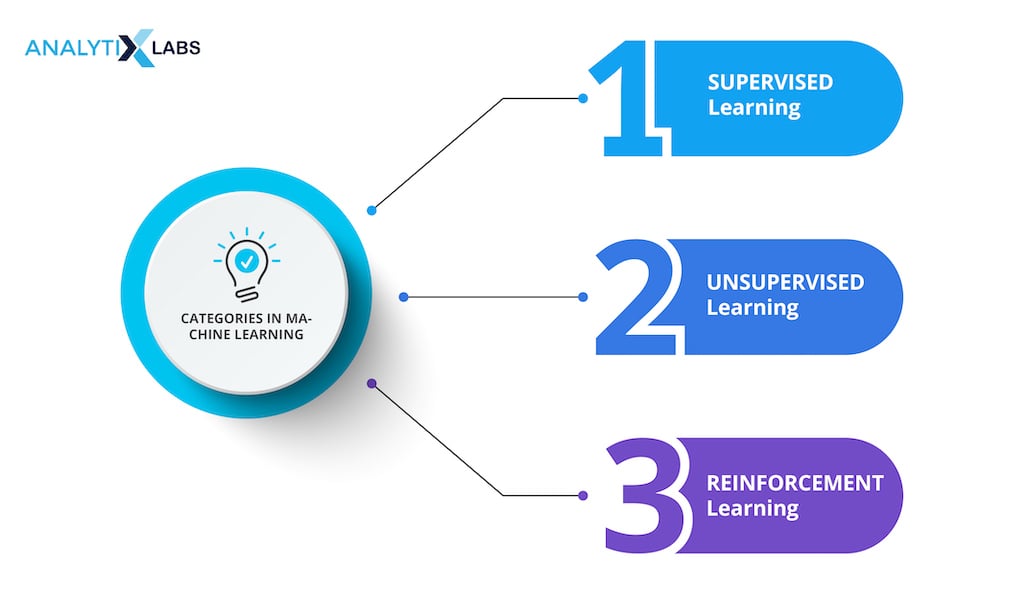
- Supervised Learning – In this method, the algorithm is trained using data that has been labeled and in which the target variable or desired result is known. Once trained, the algorithm may make predictions based on unidentified information by learning how to associate input variables with the intended output.
- Unsupervised Learning – In this case, the algorithm is trained on unlabeled data, and its goal is to discover structures or patterns within the data without having a specific target variable in mind. Common unsupervised learning tasks include dimensionality reduction and clustering.
- Reinforcement Learning – An algorithm is trained via interactions with the environment in this type of learning. The algorithm learns how to operate in order to maximize a reward signal or accomplish a particular objective. Through rewards or penalties, it receives feedback that helps it refine its decision-making process.
Artificial Intelligence and Machine Learning
Artificial intelligence (AI) is divided into several subfields, and machine learning (ML) is one of them. In order to create intelligent machines that can simulate human intelligence, a variety of methodologies, approaches, and technologies are used. This notion is known as artificial intelligence (AI).
Some academics were interested in the idea of having machines learn from data in the early stages of AI as an academic field. They tried to approach the issue using various symbolic techniques and neural networks. They were primarily perceptrons, along with other models that were eventually discovered to be reimaginings of the generalized linear models of statistics.
For instance, you aim to build a system differentiating cows and dogs. With the AI approach, you will use techniques to make a system that can understand the images with the help of specific features and rules you define.
Machine Learning models will require training using a particular dataset of pre-defined images. You need to provide many pictures of cows and dogs with corresponding labels.
Also read: Guide on how to learn AI and Machine Learning by yourself
Why is Machine Learning Important?
Machine Learning is a fundamental subfield of artificial intelligence that focuses on analyzing and interpreting patterns and structures in data. It enables reasoning, learning, and decision-making outside of human interaction.
The importance of machine learning is expanding due to the vastly more extensive and more varied data sets, the accessibility and affordability of computational power, and the accessibility of high-speed internet. It facilitates the creation of new products and provides companies with a picture of trends in consumer behavior and corporate operational patterns.
Machine learning is a prime component of the business operations of many top firms, like Facebook, Google, and Uber.
Predictive Analytics:
Machine learning makes predictive analytics possible by using past data to forecast future results. It is beneficial in the fields of finance, healthcare, marketing, and logistics.
Organizations may predict client behavior, spot possible dangers, streamline operations, and take proactive action to improve results using predictive models.
Personalization and recommendation systems:
Machine learning makes recommendation systems and personalized experiences possible, influencing every aspect of our daily lives.
Platforms like Netflix, Amazon, and Spotify use machine learning algorithms to comprehend user preferences and offer personalized recommendations. Personalization boosts user pleasure and engagement while promoting business expansion.
Image and speech recognition
Algorithms for machine learning are particularly good at jobs like speech and picture recognition. Deep learning, a branch of ML, has transformed computer vision and natural language processing.
It makes it possible for machines to comprehend, analyze, and produce visual and audio input. This technology is helpful for driverless vehicles, surveillance, medical imaging, and accessibility tools, among other things.
Scientific research and exploration:
Machine learning supports scientific investigation and research by analyzing massive volumes of data, modeling complex events, and producing fresh insights.
It has been helpful in research related to astronomy, genetics, modeling of the climate, and drug discovery. In their respective fields, machine learning algorithms assist scientists in identifying patterns, finding novel correlations, and making discoveries.
Continuous improvement and adaptation:
Machine learning algorithms can change their behavior over time by learning from new data. As additional data become accessible, this capability enables systems to enhance efficiency and accuracy continuously.
Applications like recommendation systems and autonomous vehicles improve with time, increasing their dependability and efficiency.
How Does Machine Learning Work?
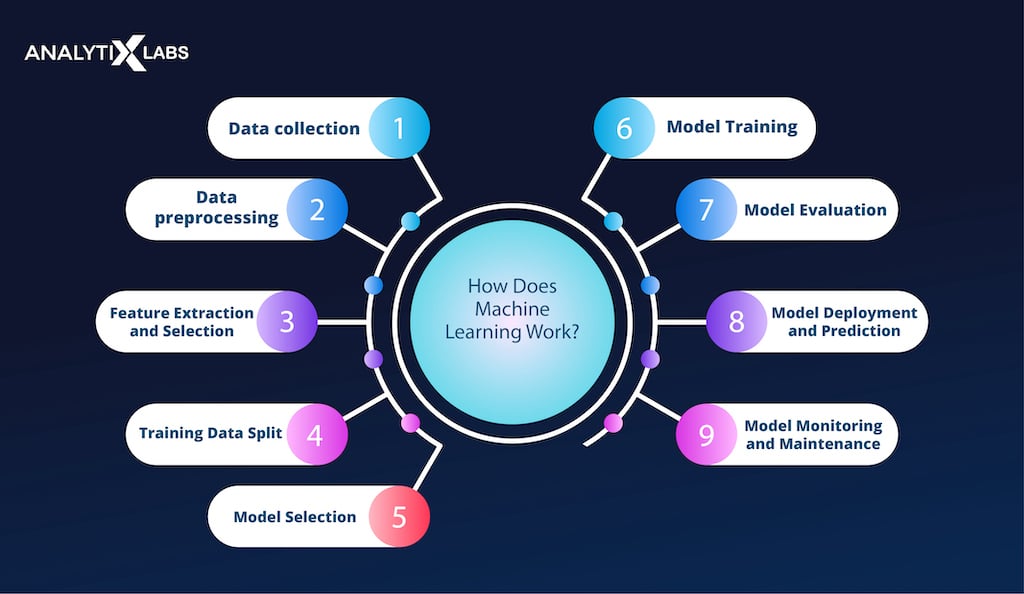
The process of machine learning is iterative. The objective is to create a model to make precise predictions or judgments and generalize to new data. Here is a comprehensive breakdown of how machine learning importance and its functions:
Data collection
In machine learning, gathering meaningful and excellent data comes first. The basis for developing and testing machine learning models is this data. Various sources, including databases, sensors, and web scraping, can be used to acquire the data.
Data preprocessing
After collection, the data must be preprocessed to guarantee its quality and usefulness for training the machine learning (ML) model. In this step, the data is processed by removing any unnecessary or noisy data points, handling missing values, and the data is prepared appropriately for analysis.
Feature Extraction and Selection
The raw data may frequently include a significant amount of features or variables. Feature extraction is finding the most appropriate characteristics from the dataset relevant to the current issue.
In feature selection, the aim is to select the subset of characteristics that are most relevant for the model, hence reducing the dimensionality of the data.
Training Data Split
The training, validation, and test sets are typically the two or three subsets of the dataset. The validation set is utilized to adjust the model’s hyperparameters and evaluate the model’s performance after it has been trained using the training set. The test set is used to assess the trained model’s ultimate performance.
Model Selection
Different machine learning (ML) techniques, including support vector machines, deep neural networks, decision trees, and linear regression, might be selected depending on the situation at hand. The type of data, the difficulty of the issue, and the resources available all play a role in the model selection process.
Model Training
The chosen ML algorithm picks up patterns and connections from the training data during the training phase. In order to reduce the discrepancy between the anticipated output and the actual output supplied in the training data, the model iteratively adjusts its internal parameters.
This process is referred to as optimization or learning. Optimization methods like gradient descent are frequently used in their execution.
Model Evaluation
After training the model, the validation set is used to assess it. Performance metrics for the model, such as precision, accuracy, recall, or mean squared error, are computed to determine how successfully the model generalizes to new data.
The model can move on to the following stage if its performance is adequate. If not, it might need more fine-tuning or an alternative strategy.
Model Deployment and Prediction
The model is prepared for deployment once it has undergone training and evaluation. In order for the model to receive new, unforeseen data and make predictions or judgments based on the discovered patterns, the model must be integrated into a production environment.
The projections from the model can be applied to various projects, including classification, regression, clustering, and recommendation systems.
Model Monitoring and Maintenance
After the model is used, it is crucial to keep track of how it is doing and ensure that it continues to be accurate and dependable over time. The model can be retrained using fresh data to adjust to evolving trends or boost performance.
Machine Learning Methods
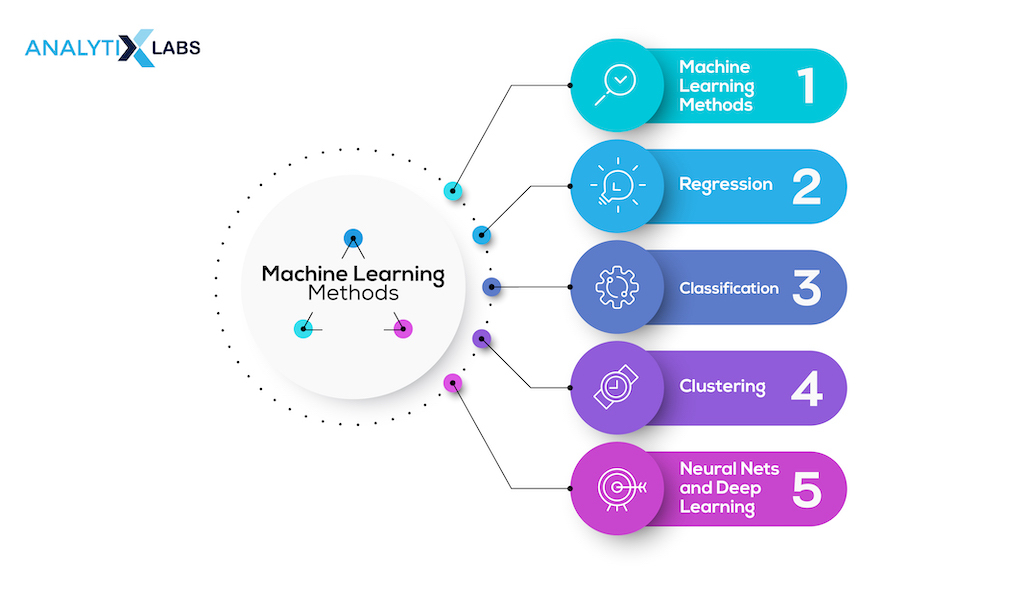
Machine learning is a trendy topic in academia and business; new techniques are always being created. Even for specialists, the speed and intricacy of the field make it difficult to keep up with new techniques.
Let’s look at these distinct methods to explain machine learning importance and provide a learning path for people unfamiliar with fundamental ideas.
Regression
This method falls under the supervised learning division of ML. Regression helps predict the specific numerical value based on the previous data set. For example, projecting any property’s price based on any similar property’s prior pricing data.
The most basic technique is linear regression. The most used algorithm for continuous data is this one. However, it restricts itself to a linear relationship and only considers the dependent variable’s mean. Time series analysis and trend forecasting are two applications of linear regression. On the basis of historical data, it can forecast future sales.
It models a collection of data by using the equation of line (y = m * x + b). By figuring out the location and slope of a line that minimizes the distance between the data points and the line, we may train a linear regression model using numerous data pairs (x, y). Put another way, we figure out the slope (m) and y-intercept (b) for a line most closely resembles the data’s observations.
Also read: Logistic Regression in R
Classification
It is the process of finding a model that assists in categorizing the data into different categories. It comes under the category of supervised learning.
In this procedure, the data provided in the input is used to categorize the data under several labels, and the labels are then predicted for the data. When a variable’s output is categorical, it falls into one of several categories, such as red or black, spam or not, diabetic or not, etc.
Also read: What is Classification Algorithm in Machine Learning?
Classification models include K-nearest neighbor(KNN), Support vector machine(SVM), and Naive Bayes.
-
Support Vector Machine (SVM)
SVM, which stands for Support Vector Machine, is a supervised learning technique for categorizing data into two distinct categories. The method employs a hyperplane to accomplish this task. A linear discriminative classifier seeks to develop a model for classification by attempting to divide the two sets of data along a straight line.
Essentially, it aims to locate a line or a curve (in two dimensions) or a manifold (in multiple dimensions) that effectively divides the classes from one another.
-
K-nearest neighbor(KNN)
KNN considers the nearer data points with more features in common and is thus more likely to fall into the same category as the neighbor. Any new data point’s distance from all other data points is determined, and the K nearest neighbors are used to determine the class.
A data point is categorized based on the majority of votes cast by its neighbors, and then it is assigned to the class with the fewest k-neighbors.
Also read: KNN Algorithm in Machine Learning
-
Naive Bayes classifier
Naive Bayes is a set of supervised machine-learning classification algorithms. These algorithms operate based on the principles of Bayes’ theorem and function as probabilistic classifiers. Rather than providing the label of a test data point, they offer the probability of predicting that the unknown data point belongs to a particular class.
The foundation of Naive Bayes lies in Bayes’ theorem, assuming the predictors to be independent. Although it is not a standalone algorithm in itself, it encompasses a family of algorithms that adhere to the shared principle that one feature’s presence is unrelated to another.
Clustering
Unsupervised learning methods like clustering are widely applied in data analytics. The clustering technique is useful when we want to learn more about our data in-depth.
The genre clusters on Netflix serve as an actual example of clustering because they are classified according to various target audiences’ interests, lifestyles, demographics, etc. You can now consider how clustering can help organizations better understand their current client base and identify new potential clients.
-
K-means Clustering
The clustering method K means attempts to group the provided unknown data into clusters. It randomly chooses the centroid of ‘k’ clusters, and measures the distance between the data points and the centroid. It then assigns the data point to the cluster centroid with the shortest distance among all cluster centroids.
-
Hierarchical Clustering
Unless you wish to create a hierarchy of clusters, hierarchical clustering is almost identical to standard clustering. When choosing the number of clusters, this can be useful. Assume, for instance, that you are organizing groups of various things in the online grocery store. You want a few broad items on the front home page, and when you click on one of them, more precise categories and clusters appear.
Also read: What is Clustering in Machine Learning
Neural Nets and Deep Learning
In contrast to linear and logistic regressions, which are considered linear models, neural networks aim to capture non-linear patterns in data by incorporating multiple layers of parameters into the model.
This flexibility allows neural networks to replicate linear and logistic regression and handle more complex tasks. The term “deep learning” refers to neural networks with a substantial number of hidden layers encompassing a wide range of architectural variations.
Deep learning techniques have demonstrated significant success in various domains, including vision tasks such as image classification and text, audio, and video analysis. However, deep learning methods typically require significant data and computational power to achieve optimal performance.
They involve self-tuning numerous parameters within extensive architectures. Tensorflow and PyTorch are two of the most popular software packages for deep learning.
Also read: Machine Learning vs. Deep Learning
Natural Language Processing
Natural Language Processing (NLP) is a technique computers employ to comprehend and perform actions based on human languages, like English. It is a crucial component of Artificial Intelligence and cognitive computing.
The NLP process involves converting speech into text and training machines for intelligent decision-making or actions. NLP primarily deals with unstructured data and considers various factors such as regional languages, accents, grammar, tone, and sentiments.
NLP encompasses several steps, including lexical analysis (analyzing individual words), syntactical analysis (parsing sentence structure), semantic analysis (extracting meaning), discourse integration (understanding context within a conversation), and pragmatic analysis (interpreting language based on situational context).
Amazon Alexa, Apple Siri, Grammarly (Check grammatical errors), Google Assistant (Voice Recognition), Search Autocomplete, Chatbot (Question/ answer), and Spell check (Spelling check) are some examples of NLP.
You can also enroll in our Data Science 360 certification course and our exclusive PG in Data Analytics course at your convenience, or you can book a demo with us.
Role of Machine Learning in Major Fields
Machine learning is a technology that can find opportunities in data and transform them into real business prospects. Opportunities are the factors that support business operations and help it stand out from rivals.
It is essential to comprehend how machine learning algorithms are employed in diverse sectors to obtain the outcomes resulting in real commercial gains.
-
Healthcare
Healthcare is a sector where the role and importance of machine learning are very dynamic. To help with disease diagnosis, machine learning algorithms can examine patient data, signs and symptoms, and medical imaging. Additionally, it makes it possible to evaluate and analyze medical images, which helps radiologists identify irregularities and discover diseases.
The need for machine learning arises to predict the efficacy of new medication candidates and help identify them. Techniques can analyze patient data to personalize treatment programs and optimize medicine doses. Machine learning algorithms can analyze patient data streams in real-time to spot anomalies and foretell deteriorating situations.
-
Finance
To find fraudulent activity, machine learning models help spot patterns and irregularities in financial transactions. These algorithms examine credit-related information to evaluate the creditworthiness of people and companies.
Trading algorithms that analyze market data and generate automated trading decisions are created using machine learning. The models can evaluate and forecast the risks of loans, investments, and insurance. Clients can be divided using machine-learning techniques based on their behavior, tastes, and financial profiles.
-
Retail and E-commerce
Machine learning algorithms power systems that offer products to customers based on their tastes and behavior. These algorithms can forecast consumer demand, allowing for the most effective use of inventories and guaranteeing product availability.
ML techniques are used in conjunction with market dynamics and consumer behavior to establish the best pricing strategies. Machine learning algorithms examine customer reviews, comments, and social media data to assess customer sentiment and feedback.
For example, many e-commerce platforms and online stores have turned to machine learning techniques such as dynamic pricing to maximize revenue and minimize customer churn. This approach involves utilizing personalized user data, the pricing history of similar products, sales trends, competitors’ offers, and supply-demand dynamics to make periodic and customized price adjustments.
By leveraging this technology, businesses can optimize their pricing strategies and offer tailored discounts or promotions to attract potential customers. Amazon adjusts prices every few minutes based on various factors. The goal is to balance attracting customers with competitive prices and maximizing profits.
-
Transportation and Logistics
Machine learning algorithms can optimize delivery and transit routes by considering variables like traffic, weather, and vehicle capacity. The models can optimize maintenance plans by predicting plant and vehicle equipment breakdowns.
ML methods can estimate demand for transport services, helping with capacity planning and resource allocation. Its algorithms analyze traffic data to deliver real-time insights and improve traffic flow. Machine learning is essential for self-driving cars to see and react to their environment.
-
Natural Language Processing and Sentiment Analysis
With machine learning algorithms, it is possible to extract sentiment, insights, and meaning from text data, enabling tasks such as text categorization, sentiment analysis, and named entity recognition. The power of machine learning models makes voice assistants and transcription services possible to transform spoken words into written text.
Machine learning techniques make Automatic language translation possible, eliminating communication hurdles. Machine learning powers chatbots and virtual assistants to comprehend and reply to human questions and requests. ML techniques make it possible to quickly find and retrieve pertinent information from vast textual data.
Importance of human interpretable machine learning
-
Trust and Responsibility
Machine learning models significantly influence real-world outcomes in fields like healthcare, finance, and autonomous vehicles. Interpretable models foster confidence among users, regulators, and stakeholders by furnishing transparent rationales for their predictions. This responsibility is pivotal in ensuring the model’s choices conform to ethical and legal norms.
-
Comprehension and Insights
Interpretable models empower individuals to grasp and extract insights from intrinsic data patterns and connections. This comprehension can lead to enhanced decision-making, refined domain expertise, and the revelation of biases or inaccuracies within the data.
-
Error Detection and Debugging
When a model generates unexpected or erroneous predictions, interpretable attributes aid data scientists and researchers in rapidly pinpointing the issue. This expedites the process of rectification and contributes to the enhancement of model performance.
-
Refining and Enhancing Models
Interpretable models enable data scientists to fine-tune and progressively elevate the model’s performance. Clear insights into the model’s behavior offer guidance for adjusting hyperparameters, refining training data, or modifying the model’s architecture.
-
Effective Stakeholder Communication
Interpretable models simplify effective communication between data scientists and non-technical stakeholders, such as corporate leaders or policymakers. Transparent explanations aid in conveying the model’s reasoning, fostering improved decision-making rooted in data-driven insights.
-
Learning and Skill Advancement
Interpretable machine learning is a more accessible entryway for novices entering the field. It empowers aspiring data scientists to grasp machine learning concepts and techniques by engaging with easily comprehensible and interpretable models.
What is the future of machine learning?
As a rapidly evolving discipline, the field of Machine Learning is poised to experience ongoing technological advancements that will significantly shape its future landscape.
-
Adoption of Quantum Computing
The growing use of Quantum Computing in business is a significant Machine Learning trend. Quantum Machine Learning algorithms hold immense potential to revolutionize ML’s future. When Quantum computers are integrated with ML, data processing speeds soar, enhancing analysis and insightful conclusions from datasets.
This heightened performance enables businesses to achieve unprecedented outcomes beyond classical ML. Companies are actively embracing quantum computing’s power to develop more potent techniques.
Tech giants like Microsoft and Google have announced future quantum technology integration plans. Given this widespread adoption, Quantum Computing is a pivotal ML application shaping its future.
-
Explainable AI (XAI)
With the escalating complexity of machine learning models, there is a growing imperative to enhance their comprehensibility and transparency. Researchers and practitioners are actively developing methods to render AI systems more lucid, interpretable, and accountable. This emphasis is particularly pronounced in critical healthcare, finance, and law domains.
-
Transfer Learning and Few-Shot Learning
The concept of transfer learning, entailing the pre-training of models on extensive datasets followed by targeted refinement for specific tasks, holds substantial potential. The future may witness even more streamlined methods for transposing knowledge across diverse domains, including techniques for few-shot learning that enable models to generalize from exceedingly limited examples.
-
AutoML and Automated Model Design
Automation is poised to assume a greater role across various stages of the machine learning process, encompassing data preprocessing, feature engineering, and model selection. The ongoing evolution of AutoML tools will simplify the creation of effective models, democratizing access for individuals without specialized expertise.
Conclusion
Traditional analytical approaches are no longer adequate due to the exponential expansion of data in the digital age; hence the need of machine learning arises. The importance of machine learning and its algorithms can be seen to find patterns, trends, and connections that humans would not even be aware of.
It is impossible to undervalue the role that machine learning will play in determining our future.
We are entering a new world. The technologies of machine learning, speech recognition, and natural language understanding are reaching a nexus of capability. The end result is that we’ll soon have artificially intelligent assistants to help us in every aspect of our lives.
~Amy Stapleton
Eventually, machine learning applications will be present at every point of our daily routine. The ease ML provides is the fuel to future endeavors in technology.
FAQs
- What is most important for machine learning?
Data of high quality is the most essential for machine learning. It ought to be thorough, accurate, representational, and relevant. The machine learning model’s performance and dependability are directly impacted by data quality.
- Why is machine learning important for the future?
The ability of computers and other systems to learn from data and enhance their performance without explicit programming makes machine learning crucial for the future. By offering insightful data, automating difficult activities, and providing predictions based on patterns and trends in data, this technology has the potential to revolutionize a number of sectors and domains.
Machine learning may improve decision-making processes, optimize resource allocation, and spur innovation in healthcare, banking, transportation, and many more industries. It contains the key to opening up new opportunities, resolving challenging issues, and altering our lives and work.






1 Comment
Very well researched article. In depth and useful info