
Machine learning algorithms perform much more than just forecasting. The accuracy of machine learning results cannot be improved simply by fitting data into models. As the data gets large and complex, better data handling techniques are eminent to handle it.
Also read: What is Clustering in Machine Learning: Types and Methods
Gradient Boosting is an ensemble technique. It is primarily used in classification and regression tasks. It provides a forecast model consisting of a collection of weaker prediction models, mostly decision trees.
In this article, we will deep dive into the details of gradient-boosting algorithms in machine learning. Besides looking at what is gradient boosting we will also learn about gradient boosting models, and types of gradient boosting, and look at its examples as well.
What is Gradient Boosting?
Gradient Boosting is a type of machine learning boosting technique. It builds a better model by merging earlier models until the best model reduces the total prediction error. Also referred to as a statistical forecasting model, the main idea of gradient boosting is to attain a model that eliminates the errors of the previous models.
Related to this: What is Cost Function in Machine Learning
In each case, the target outcomes in the data decide the effect a case’s forecast has on the overall prediction inaccuracy. There are two possible cases for this:

Gradient Boosting is named so that the set target outcomes depend on the gradient of the inaccuracy vs the forecast. Every new model created using this method moves closer to the path that lowers prediction error in the range of potential outcomes for every ML training case.
Gradient Boosting is mainly of two types depending on the target columns:
- Gradient Boosting Regressor: It is used when the columns are continuous
- Gradient Boosting Classifier: It is used when the target columns are classification problems
- Loss Function: The primary goal in this situation is to maximize the loss function, which is not constant and changes according to the problems. It is simple to create one’s own standard loss function, however, it must be differentiable.
- Weak Learners: These are used mainly for predictions. A decision tree is an example of weak learners. For the real output values needed for splits, specific regression trees are applied.
- Additive Model: There are more trees added at once, but no changes are made to the model’s already-existing trees. A gradient descent approach reduces the losses when the trees are added.
Gradient Boosting Algorithm Examples
Let us understand how Gradient Boosting algorithms work through an example. In this case, we will have a continuous target column, thus using Gradient Boosting Regressor .
We will use a random dataset with different features. We have to predict target values, while all other characteristics are standalone features. We need to observe if the learning algorithm is able to figure out the irrelevant characteristics.
Step 1
The first step includes building a base model to predict the dataset. For easy calculations, we will take an average of the target column and Assume that is the anticipated value, as displayed below:
Mathematical interpretation of the 1st step:
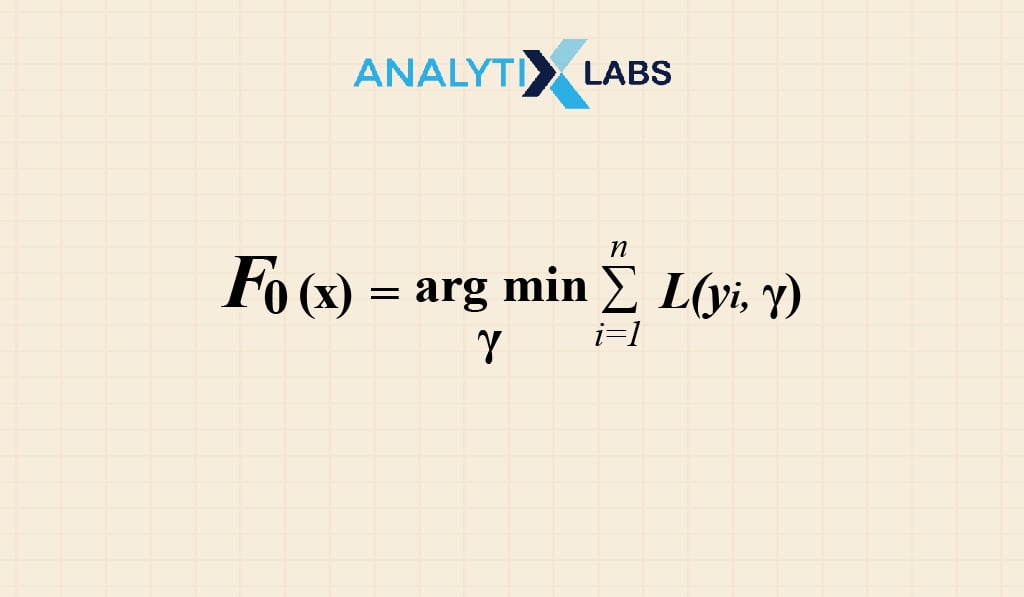
Gamma= Predicted Value
Argmin= predicted value or gamma to be found of which the loss function is minimum
Furthermore, as our target column is continuous , the Loss function is to be calculated by:

Step 2
Find the pseudo residuals (observed value – predicted value)
The predicted value in this is the value forecasted in the prior model. Because our target column is now incorrect, it should be noted that the forecasts in this situation will reflect the error values rather than the expected car price values.
Step 3
This step includes finding the output values of each leaf of the decision tree . We have to find the output for all the leaves since a single leaf might get more than one residue. No matter if there is just one number or more, we can easily calculate the result by taking the average of all the values in a leaf.
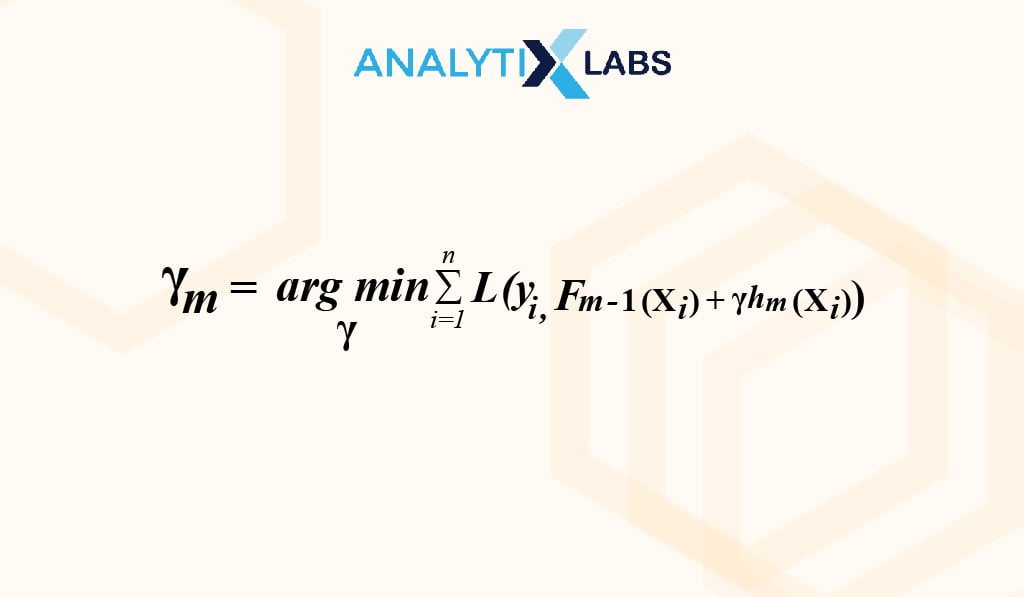
Where, hm(xi)= DT produced during residual
m= no. of DT
Step 4
The final step involves the update of the forecasts of the previous model.
Mathematical Expression for updating the model:

Where,
M= no. of decision trees made
Fm-1(x)= forecasts of the base model
The model has been explained through a gradient-boosting example in the below video:
Python Code for Gradient Boosting Algorithm
Now, the gradient boosting explained above mathematical calculation can be presented through a Python Code. DecisionTreeRegressor from scikit-learn can be used to build trees with a focus on the gradient boosting algorithm. In the implementation fit
Method will be used to train the model and predict method to make predictions.

The trained trees from self.trees are retrieved with predictmethod.
Upon running a CustomGradientBoostingRegressor you will notice it also performs like the GradientBoostingRegressor from scikit-learn.

To understand this in more detail, watch this example of Gradient Boosting Algorithm with Python –
Finding best estimators using GridSearchCV
GridSearchCV helps in identifying the best set of hyperparameters. It reduces manual effort by passing all hyperparameter combinations into the model.
Here is the process to find optimal parameters using GridSearchCV:
Step 1- Import GridSearchCV library

Step 2- Data setup

Step 3 – Create the model and parameter
Create an object to use the using GradientBoostingClassifier for the Machine Learning model.

Next, make a dictionary with the parameters of the model to pass through GridSearchCV. The important parameters are-
- estimator: models or functions on which GridSearchCV is to be used pass through it.
- param_grid: It is the list of parameters of models or functions, also known as Dictionary. GridSearchCV selects the best out of these.
- Scoring: The evaluating metric for the model performance. It decides the best hyperparameters, using the estimator score.
- cv: It passes an integer value which signifies the number of splits for cross-validation. The default value is set as five.
- n_jobs: Signifies the number of jobs running in parallel.

Step 4- Run through GridSearchCV and print results
Fit the data set in the object grid_GBC

Use print statements to get the result i.e. values of hyperparameters .

Applications of Gradient boosting algorithm
-
Reducing bias error in an ML model
The gradient boosting algorithm in machine learning is applied to cut down the bias error in the training dataset of the model.
Usually, a biased dataset is one in which the linear regression line does not fit the training data with a more significant margin. This inability to capture the true relationship of the training dataset is called bias. And, higher bias denotes underfit training dataset in a machine learning model.
For a highly-biased dataset, the gradient boosting algorithm increases the number of stages at a low learning rate to optimize the decision stumps in order to make the training dataset precise.
-
Resolves problems related to regression
Regression in machine learning is the approach to predicting continuous outcomes by observing the relationship between independent variables or features and dependent variables. Gradient boosting regression algorithm can be used to predict the target variables with the help of decision stumps like AdaBoost.
-
Assists in resolving problems related to data classification
Gradient boosting classification is effective to predict the categorical data in an ML model. In this case, log loss is considered as the cost function to indicate how close a prediction probability comes to the corresponding true value. Likewise, it becomes easier to find how much the predicted probabilities deviate from the true ones.
Types of Boosting
-
XGBM OR Extreme gradient boosting machine
You already know what a gradient boosting machine is. Basically, it is an algorithm that takes distinct predictions from different decision trees to optimize the learning in the successor tree.
Now, as the name suggests, XGBM is a modified version of a gradient boosting machine, where different regularization techniques are implemented. It includes L1 and L2 regularization, dropout method, early stopping, etc.
This regularization process can reduce the over-fitting or under-fitting of the training dataset gradually as we move from parent to successor decision trees. Gradually, it increases the performance of the model by decreasing the value of the regularization coefficient.
Also, unlike GBM, XGBM can perform parallel preprocessing of each node to save time and get rapid decisions/predictions . Extreme gradient boosting machines also understand the imputation (i.e. whether a node should be placed on the right or left of the decision tree) automatically.
-
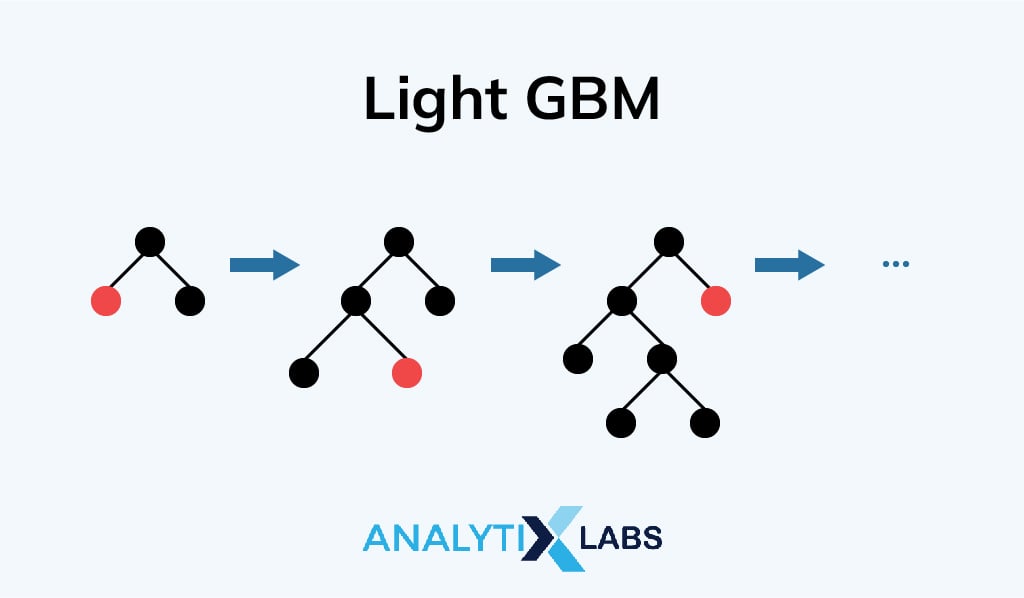
Light GBM
Light GBM is introduced to make the gradient boosting algorithm even simpler, faster, and more efficient. Unlike XGBM, the light gradient boosting machine proceeds with respect to the leaf of the tree instead of the nodes. To handle a large dataset, light GBM is quite an efficient approach. However, it does not perform well for small data points.
The two main techniques used by light GBM in gradient boosting algorithms are gradient-based one-side sampling and exclusive feature bundling. For the GOSS approach, different data points are accepted to find the under-trained instances.
Then, the instances are randomly dropped with smaller gradients (i.e. trained data points) to get accurate results for the respective larger gradient as well. On the other hand, the EFB approach is used to deal with high-dimensional data that has a lower chance of encountering any loss.
These specific data points or features, as they are mutually exclusive (i.e. they never take zero as input simultaneously), are bundled together to get a precise training model with less space complexity.
To sum it up, light GBM works faster with less memory in a gradient boosting model with cutting-edge approaches as explained in the last section .
-
Catboost
Catboost is basically designed to handle categorical data and to avoid the very common errors in the machine learning model. As we discussed earlier, a gradient boosting classifier is one of the very important advantages of a gradient boosting algorithm to handle the categorical data and predict the expected result.
With Catboost you can work efficiently with the ‘string’ type categorical data as most of the other approaches are better with numerical data sets only . It can also work with multimedia-type data that includes audio, images, etc.
Advantages of Gradient Boosting
- As the gradient boosting model follows ensemble learning, it is easier to interpret and handle the data.
- It is more accurate than many other algorithms and with cutting-edge methods like bagging, random forest, and decision tree, accurate results are available. Also, this is one of the best algorithms to handle larger datasets and compute with the weak learners at least loss.
- This algorithm not only supports numerical datasets but is also efficient for categorical data handling.
- Gradient boosting algorithm in machine learning is a resilient method that checks over-fitting training datasets quite easily.
Disadvantages of Gradient Boosting
- As there can be multiple outliers in a dataset, gradient boosting cannot avoid them completely. As the gradient boosting classifier tends to correct the errors, it accepts the outlying values as well. So, it is quite a sensitive algorithm for outliers in a dataset that increases memory complexity.
- Another disadvantage of this algorithm is the tendency to solve each error of predecessor nodes that results in overfitting of the model. However, this can also be solved with the L1 and L2 regulation method that is also mentioned earlier.
- Gradient boosting models can be computationally expensive and can take a longer time to train the complete model on CPUs.
Real-life applications of boosting algorithms
To understand what is gradient boosting completely, you need to know its real-life applications and what exactly made this so popular now.
- Making medical data prediction becomes easier with this algorithm as the learning rate is much more accurate and it can also handle such large data of a medical service provider.
- Forecasting weather conditions in a region based on variations in humidity, temperature, pressure, and other factors.
- Developing hackathon platforms with better accuracy with a gradient boosting algorithm to make the contests even more technical and seamless.
- Boost the information technologies like SEO, and page ranking in any search engine with this boosting algorithm in real-time.
- Automating critical financial tasks became easier with a gradient boosting algorithm in machine learning as it is integrated with deep learning to perform fraud detection, pricing analysis, etc.
Frequently Asked Questions:
-
Which boosting algorithm is best?
There are different types of boosting algorithms available for machine learning like AdaBoost, gradient boosting algorithm, and XGboost.
XGboost is just a modified version of the gradient boosting algorithm in machine learning that can process parallelly and find the missing data automatically to be more memory efficient and it can also handle a larger data set.
On the other hand, Catboost can work with classification problems better. Adaptive boosting or AdaBoost is another popular gradient boosting algorithm that can work with any other machine learning algorithm and can handle weak learners in order to optimize the predicted result.
-
How does a gradient boosting tree work?
A gradient boosting tree is developed with n number of decision stumps where each successor tree learns from the errors of its parent tree and gradually the errors get reduced.
The gradient boosting tree works with weak samples, which works better than random samples. The gradient Boosting algorithm is based on ensemble learning where an ML model makes predictions based on n number of distinct models.
From these models, this learning approach finds less biased and varied data points. It ensures that the successor decision tree will be better trained. It is better than the random forests as with each iteration, the tree nodes get corrected.
-
Is gradient boosting the same as XGBoost?
XGBoost is an upgraded form of gradient boosting algorithm. It is not only faster but also more useful than GBM. In XGBoost, regularization processes are applied to the gradient boosting algorithm to make the data points trained quickly and efficiently.
Also, in XGBoost, there is no need to find the missing data points, as they have the efficiency to decide where to put a node in the tree.
Even though gradient boosting and XGBoost both can process large datasets, XGBoost is comparatively more memory and time efficient.
- Definitive Guide to Learning Hadoop: Beginners’ Edition
- How to become an AI engineer?
- How data reduction can increase efficiency in data mining
- How to learn AI and Machine Learning Tools by Yourself
- What are the Best Python Libraries for Machine Learning?
- How to use Naive Bayes Theorem in machine learning?





