
Data warehouses are becoming increasingly popular and are being adopted by companies around the globe on a large scale. This has caused several companies to have questions about data warehousing in their interview process involving data science professionals. This article will review the top 30 data warehouse interview questions that every recruiter will ask in your next interview.
Let’s start first by understanding what a data warehouse means.
What is a Data Warehouse?
To answer the crucial questions about data warehouse concepts interview, you must understand what data warehouse is all about.
Organizations build electronic central repositories, known as data warehouses (DWH), to store large volumes of data. These repositories generally store historical and structured data from disparate sources.
These sources can be from various business units of an organization, allowing for quality and consistent data to be available in a single place.
Data warehouses are generally created for specific business areas (e.g., finance, sales, customer relationships). Organizations heavily rely on data warehouses for decision-making as they enable the creation of data-backed reports. These reports are created by analyzing and understanding complex underlying patterns in the data available in a data warehouse.
Data warehouse is also known by several other terms, like –

- Data Warehouse (DW)
- Enterprise Data Warehouse (EDW)
- Business Intelligence Systems
- Decision Support Systems (DSS)
- Information Warehouse
- Integrated Data Warehouse
- Data Warehouse Appliance
- Data Mart
Let’s now focus on the basic data warehouse interview questions and answers . But before that –
Explore our signature data science courses and join us for experiential learning that will transform your career. We have elaborate courses on AI, ML engineering, and business analytics. Engage in a learning module that fits your needs – classroom, online, and blended eLearning. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
Data Warehouse Interview Questions: Beginners
If you are a fresher, there is a high chance that the data warehouse questions will be really basic.
Q1. What is a data warehouse?
Ans. The central repository where data from multiple sources is stored is known as a data warehouse. Such a repository helps provide integrated information that different departments of an organization can query and analyze the results to gain better insights.
Often, a data warehouse is a prime source for all the report generation and various data analytical operations and thus is considered the heart of the business intelligence (BI) system.
Take a look at the data architecture to get a clear understanding.
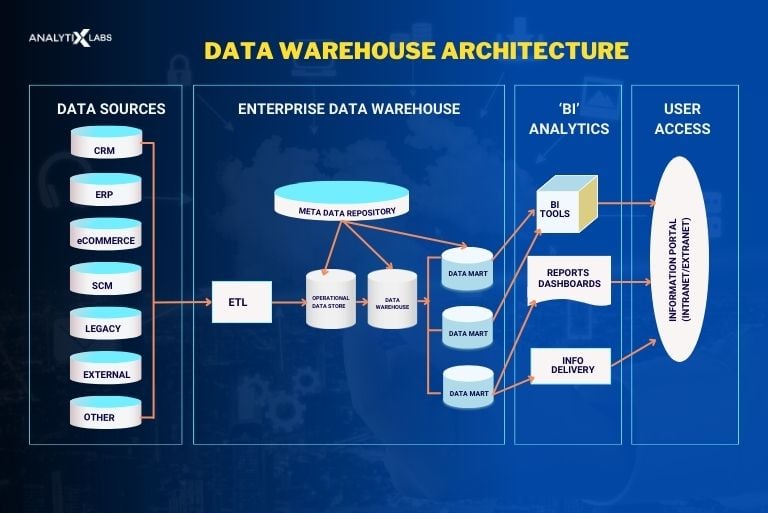
To test your basic understanding, many data warehouse concepts interview questions can be around OLAP and OLTP, and you should be aware of what these terms mean.
Q2. What is an OLAP in the context of data warehousing?
Ans. OLAP stands for Online Analytical Processing. It refers to a database that has a multidimensional structure, allowing for data analysis from multiple dimensions and perspectives. Thus, OLAP allows for collecting, managing, processing, and presenting multidimensional data for numerous analytical and management processes. To do all this, it uses an OLAP cube.
In an OLAP cube, the data is organized into a multidimensional grid. This grid comprises multiple cells, where every cell has values that can be analyzed and used for reporting. OLAP cubes are often used by data scientists when they are trying to analyze large datasets.
They allow them to look at the data from different angles, allowing for a better understanding of it. In the context of data warehouses, OLAP cubes are created using the data stored in data warehouses, making the data more usable and practical.
Q3. What are the typical guidelines you should follow when selecting an OLAP system?
Ans. There are several dedicated OLAP tools out there. However, when selecting an OLAP system, one needs to ensure that the OLAP system has the following capabilities-
- An OLAP system should provide a multidimensional conceptual view of the data, making it feasible for the users to use methods like slice and dice.
- The OLAP system should provide the users with a high level of transparency regarding the underlying data repository, data sources, computing operations, etc. All of this allows increased productivity and improved efficiency for the users.
- The OLAP’s tool server should be easily integrated with numerous clients with minimal coding effort, allowing the server to map and consolidate data from disparate databases.
- The OLAP system should allow multiuser support, allowing various users to access the same data simultaneously. The system, however, must ensure that data integrity and security are not compromised.
- Ideally, the OLAP system should allow an unlimited number of data dimensions.
Q4. What is OLTP?
Ans. OLTP means online transaction processing. In this system, the data gets modified when received in the warehouse and often has many concurrent users.
Data warehouse questions can also examine how well you can differentiate between different data warehousing concepts. Thus, you should prepare for questions that allow you to distinguish between different technologies.
Q5. State some key differences between OLAP and OLTP.
Ans.
The key differences between OLAP and OLTP are as follows-
|
OLTP |
OLAP |
|
|
|
|
|
|
|
|
|
|
Q6. What are the common functions performed by OLAP?
Ans. The key functions performed by OLAP include the following-
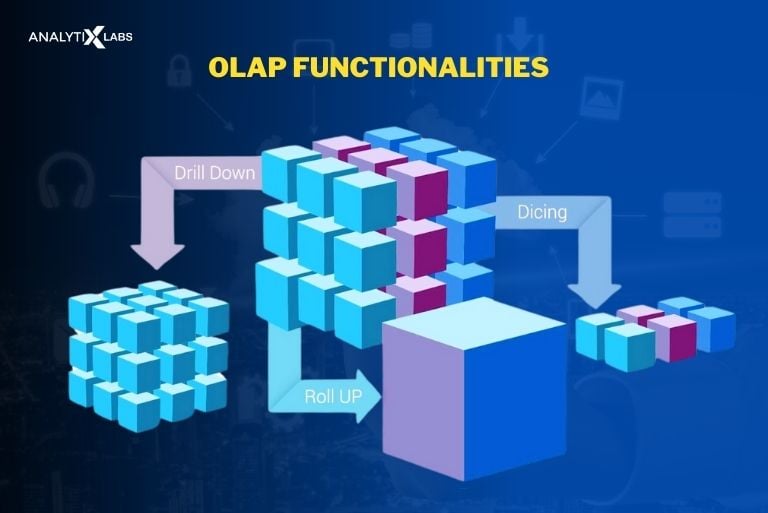
- Roll-Up
- Drill-Down
- Slice
- Dice
- Pivot
When exploring data warehouse interview questions and answers, you must focus on the ones exploring fact tables, as it is an important aspect of data warehousing.
Q7. What is a Fact Table?
Ans. The central table in a data warehouse that holds the raw data is known as a fact table. There are several rows and columns in a fact table where every row represents an event (e.g., a transaction) while every column represents a particular aspect of the event.
A fact table typically holds data about sales transactions, customer interactions, etc. Thus, organizations use the fact table to hold data about any business events.
Such a table is crucial for analysis and report generation, such as customer behavior reports, sales performance reports, trend analysis, etc.
To provide additional context to the data on the fact table, they are often linked to other tables in the data warehouse.
For example, a fact table holding transaction data may be linked to a customer dimension table, allowing information about the customer involved in the transaction, such as their name, contact information, address, etc.
Q8. What are the different types of Fact Tables?
Ans. There are broadly three types of fact tables.
| TRANSACTIONAL | The most common and basic type of fact table is a transaction fact table that indicates the occurrence of an event at any given time. It has one row per transaction and holds data at a highly detailed level, with several dimensions linked to it.
Users can have extensive dimensional grouping and use features like roll-up, drill-down, etc., when using this type of fact table. Thus, a transaction fact table provides a fundamental view of a corporate process. |
| SNAPSHOT | A snapshot fact table is used if one has to provide the condition of things at a specific time. As the name suggests, it provides a “snapshot of the moment” to the organization. Organizations use such a table to examine their performance at different time intervals.
A snapshot table differs from a transaction table as it contains non-additive and semi-additive information. Unlike a transaction fact table (where each occurrence of an event leads to the addition of a new row), a snapshot fact table represents the performance of activity at different (often regular) time intervals (such as the end of the day, week, month, etc.). However, these two tables are not mutually exclusive, and the snapshot table relies on the transaction fact table to retrieve detailed data. |
| ACCUMULATING | Accumulating fact tables provide a well-defined beginning and end to any activity or process.
A table often has multiple data stamps reflecting the events or predictable stages occurring during the lifespan of the activity. Such tables often have a dedicated column with timestamps indicating the last time the row was updated. |
Q9. What is a factless fact table?
Ans. A factless fact table defines data relationships in a data warehouse by establishing the relationships between the elements of different dimensions. There are two types of such tables – event-tracking and coverage tables.
An event tracking table is where there is no measured value of an event, whereas, in a coverage table, the conditions around an event are provided.
For example, creating a negative analytical report of a store that cannot sell specific products during a designated period will be based upon a coverage table, which would have the list of products available to the store and the ones sold.
Q10. What is a dimension table?
Ans. A dimensional table is a table in the data warehouse’s star schema. They contain dimension attributes, keys, and values and describe the dimensions. A dimensional table describes the objects in the fact table and is the foundation for dimensional modeling. They are linked to the fact table using a primary key that allows every record to be uniquely identified.
Q11. Explain a few key differences between the fact table and the dimension table.
Ans.
|
Fact Table |
Dimension Table |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Q12. What is metadata?
Ans. Metadata is used in data warehouses as it holds information about how data interacts with other data, allowing for better classification and organization of files.
Metadata, therefore, allows data professionals to find the required data easily in a data warehouse. Metadata can be of two types – structural and administrative.
While structural metadata describes an object’s classification, administrative metadata contains information about a data object’s history, former uses, and previous users.
Data warehousing interview questions can often test your knowledge of the tools and techniques available for data warehousing services. You must prepare questions that test your knowledge of these aspects, too.
Q13. What are the common Data Warehouse solutions used in the industry today?
Ans. Common data warehouse solutions are as follows-
- Snowflakes
- Oracle Exadata
- GCP Big Query
- AWS Redshift
- SAP BW4HANA
- Microfocus Vertica
- Teradata
- Apache Hadoop
Q14. What are the common ETL tools used during data warehousing activities?
Ans. Common ETL tools are listed below.
- Informatica
- Talend
- Abnitio
- Oracle Data Integrator
- Skyvia
- Microsoft – SQL Server Integrated Services (SSIS)
- Pentaho
- Xplenty
Q15. What is the difference between structured and unstructured data?
Ans. Organizations typically deal with data in two forms – structured and unstructured. The schema is clear in structured data and can fit in a fixed table. Thus, DBMS is often used to store this type of data.
Common protocols include ODBS, ADO.NET, SQL, etc. Unstructured data has no defined schema or structure and is mostly unmanaged.
Unlike structured data, unstructured data can be easily scaled in runtime and are more flexible regarding the data type they can store. Common protocols include XML, JSON, SMTP, etc.
Also read: Understanding Data Structure in Big Data
Let us look at more advanced data warehouse interview questions that are ideal for intermediate professionals.
Intermediate Data Warehouse Interview Questions
Q16. What is a data model?
Ans. In data warehousing, a diagram that displays the various sets of tables and the relationship they share is known as a data model. Any software that creates database objects for storage and manipulation uses data models, including data warehouse systems.
During the creation of data warehouses, data models are designed and developed in three main stages – conceptual, logical, and physical.
In the conceptual stage, a diagram with squares and lines is created, with the squares representing entities and lines, establishing the relationship between them. This provides a very abstract and high-level understanding of the key attributes that should be there in the data warehouse.
In the logical stage, the data model goes beyond the conceptual level, provides more details, and identifies its key and non-key attributes. A key attribute, for example, can be a time entity, such as a date, that defines the uniqueness of an entity. Such an attribute also considers relationships with the other tables, such as one-to-one, one-to-many, or many-to-many.
Lastly, the data model reaches the physical state where the entities and attributes are replaced with tables and columns. While entities and attributes are specific to a logical data model design, the tables and columns mentioned in the physical data model are specific to a database.
Q17. What is data modeling?
Ans. Data modeling is a concept in data engineering that uses data models. Here, software development projects such as the development of a data warehouse are broken down into simple diagrams presented in the form of flow charts, thereby providing a visual representation of the problem and its solution.
Data models, therefore, are common frameworks that allow developers to define how the data is to be used within the information system and the requirements needed to support the proposed process.
Data modeling involves data modelers working close to business stakeholders and users of the data warehouse so that the developed warehouse serves the organization’s purpose.
Also read: Understanding Market Mix Modeling for Predictive Analytics
Q18. What does a slowly changing dimension mean?
Ans. The data dimension slowly changes over time, possibly due to numerous reasons. Common reasons include changes in customer demographics, business processes, new product launches, etc. A slowly changing dimension (SCD) tracks the changes, enabling companies to understand the data better.
Q19. What are the three types of slowly changing dimensions?
Ans. The three types of SCD are as follows.
- SCD Type 1: The current record (new data) is overwritten on the previous record (old data).
- SCD Type 2: A new record (new data) is created for a new change, creating another dimension record.
- SCD Type 3: A new column is added to track changes; thus, a current value field is created to include the new data.
Q20. What are the different types of data warehouses?
Ans. There are multiple types of data warehouses, the most prominent ones being enterprise, operational data store, and data mart.
| Enterprise Data Warehouse | An enterprise data warehouse brings an organization’s functional areas together cohesively. Such a data warehouse allows individuals across the organization to easily access the corporate data in a centralized location, allowing for efficient data analytics and reporting. Enterprise data warehouses allow for easily finding and wrangling data from different systems. |
| Operational Data Store | Operational Data Store, aka. ODS allows the access of data directly from a database. The data stored in such a warehouse is cleared and rectified of any redundancy through associated business rules. It is used for smaller data and simple queries. |
| Data Mart | A data mart is a specific data warehouse structure developed with the organization’s business domain in mind. As information about the organization’s business unit is contained, every company has its specific data mart. |
Data warehouse interview questions can often be based on the response to your previous questions. For example, as you mentioned Data Mart in the previous response, more questions around it can be expected.
Q21. What are the different types of data mart?
Ans. Three main types of data marts are dependent, independent, and hybrid.
| Dependent data mart | A dependent data mart is developed using external, operational, or sources. As the source company can access the data in a single warehouse, making the data availability centralized, it enables the development of more data marts. |
| Independent data mart | An Independent data mart has no central data warehouse or connection to other data warehouses. Each data mart holds self-contained information that can be used independently for analysis and report generalization. Such data marts are established for small groups within an organization. |
| Hybrid data mart | A data mart combines elements of the dependent (centralized) and independent (decentralized) data mart. Such a data mart holds the data centrally for an enterprise but contains decentralized data for specific departments or units of the organization. It is most effective when small data-centric applications are employed. |
Q22. What is a junk dimension?
Ans. A junk dimension is a type of dimensional table with attributes not belonging to the fact table or any other existing dimensions. These attributes contain flags and text (e.g., indicators like yes/no, true/false, non-generic comments, etc).
When exploring data warehousing questions, you must focus on those questions that test your knowledge of how a data warehouse is built from scratch. One such question is discussed below.
Q23. What are the key stages in developing a data warehouse?
Ans. There are seven crucial stages in developing a data warehouse. These are as follows
- Stage 1: Determining business objectives
- Stage 2: Collecting and analyzing information
- Stage 3: Identifying the core business processes
- Stage 4: Developing a conceptual data model
- Stage 5: Identifying data sources and creating data transformation plans
- Stage 6: Setting up the tracking duration
- Stage 7: Implementing the finalized plan
Q24. What is the difference between a data warehouse and a database?
Ans. The database collects structured data in a logically organized manner in a computer system. A database management system (DBMS) is responsible for managing the database. There are several differences between a data warehouse and a database. Some of the key differences are as follows-
|
Data Warehouse |
Database |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Expect some data warehouse interview questions that test your knowledge of the different types of data warehouses, too.
Q25. What is real-time warehousing?
Ans. Real-time data warehousing is a kind of data warehouse where the data is collected, stored, and managed in real time.
This allows organizations to make decisions using the most up-to-date information. Unlike traditional data warehouses (that use batch processing where data is periodically loaded into the warehouse), real-time data warehouses have relatively low latency between data generation, storage, and analysis.
Such warehouses are commonly employed when an organization needs real-time analysis by processing streaming data.
Q26. What is active data warehousing?
Ans. Active warehousing is where a data warehouse supports the storing of historical as well as real-time data. Thus, the data in an active warehouse is both historical and dynamic.
Such a data warehouse allows for automating routine processes whereby it automatically makes decisions for the OLTP systems.
An active data warehouse is employed whenever an organization needs an up-to-date unified value of its customer base across all its business lines.
Q27. What is a star schema?
Ans. A logical schema structure in data warehouses defines how the data is represented and organized. It defines the relationships between the tables and data elements and their structure.
A schema is crucial for effectively storing, retrieving, and maintaining the data in the data warehouse. Star schema is The most common type – a multidimensional model commonly used by data warehouse developers.
In the star schema, the fact and dimension tables are contained within the schema, with the fact table at the center and multiple dimensional tables surrounding it. Thus, a fact table contains the crucial metrics regarding the events and business processes, whereas a dimension table provides context.
In such a design, there are fewer foreign key joins. When the structure of such a schema is drawn out in a diagram, it looks like a star, hence the name star schema.
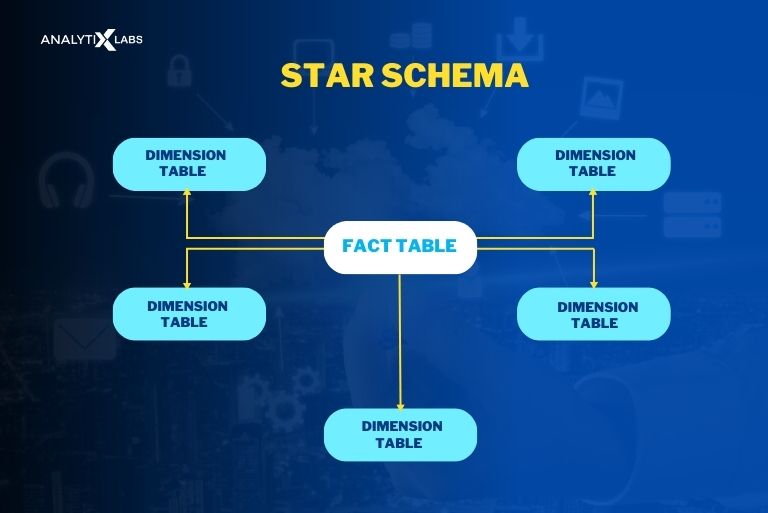
Q28. What is a snowflake schema?
Ans. Another popular type of schema is snowflake schema. Here, the fact, dimension, and sub-dimension tables are all within the schema. While it is similar to a star schema in that it uses the fact and dimension table, it is different because it goes for a normalized structure.
What I mean by normalized is that multiple related tables store data to reduce redundancy. In a snowflake schema, the dimension tables have levels of hierarchy referred to as sub-dimensions.
When such a structure is drawn out in a diagram, it looks like a snowflake, hence the name snowflake schema.
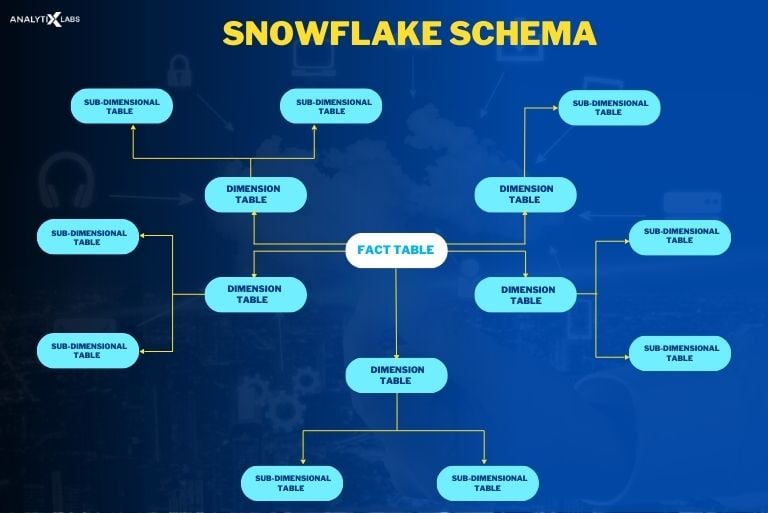
Q29. What are the differences between star and snowflake schema?
Ans. The most crucial differences between star and snowflake schema are as follows-
|
Star Schema |
Snowflake Schema |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Q30. Explain the top-down and bottom-up approaches in a data warehouse.
Ans. There are two primary approaches to designing and developing a data teahouse. These are top-down and bottom-up.
- Top-down approach
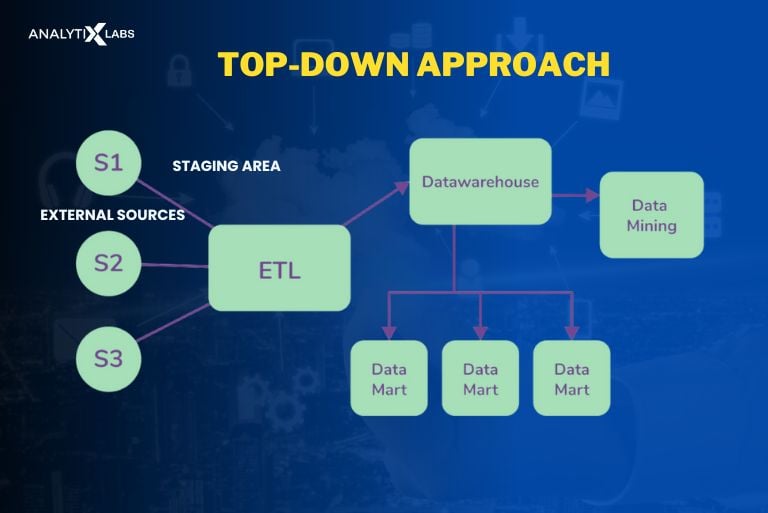
In the top-down approach, the business goals and objectives defined by the organization’s leadership and top-level management are the starting point.
Here, the data sources are first located, followed by ETL tools to stage the data, which requires processing as the data might be in different structural formats. The clean data is then stored in the data warehouses that act as the central repository.
Data marts are created for specific business units depending on the organizations’ requirements. While the metadata rests in the data warehouse, the real-time gets stored in the data mart. Lastly, this data is mined and analyzed to create reports.
- Bottom-up approach
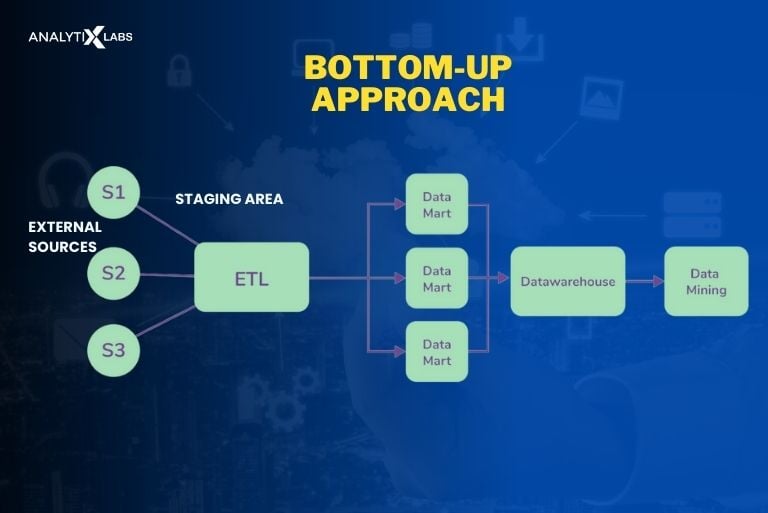
In the bottom-up approach, the data warehouse is built incrementally. Like before, the data is gathered from external sources and goes to the staging area, but here, it is directly stored in a data mart and becomes available for analysis.
These data marts are gradually consolidated to create a comprehensive data warehouse. This way, the results can be delivered quickly, and the user feedback can be considered as the data warehouse takes shape.
Often, important questions about data warehousing and data mining are asked in interviews. Therefore, let’s explore a few questions about data mining, too.Data Mining Questions to Explore (with data warehouse interview questions)
A closely related concept to data warehousing is data mining. After all, data warehousing aims to get the required data available to the data professionals so that they can mine and analyze it to form reports based on which the leadership can make informed decisions.
Therefore, you should expect a few data mining and DWH interview questions. A few crucial data mining interview questions can be as follows.
Q31. What is data mining?
Ans. The extraction of knowledge from large volumes of data is known as data mining. Complex tools and technologies are employed in data mining to extract valuable information from the data that may not be visible immediately.
Q32. What are the typical tasks performed in data mining?
Ans. Common data mining activities are as follows-
- Regressing
- Classification
- Clustering
- Forecasting
- Association Rule Discovery
- Sequential Pattern Discovery
Q33. What are the key stages in a data mining project?
Ans. The key stages in a data mining project’s life cycle are-
- Business Understanding
- Data Understanding
- Data preprocessing and cleaning
- Modeling
- Model Evaluation and Validation
- Model Deployment
Q34. What are the key steps in knowledge discovery?
Ans. The essential steps during KDD are-
- Data cleaning
- Data integration
- Data transformation
- Data mining
- Pattern evaluation
- Knowledge Presentation
Q35. What is the difference between data mining and data warehousing?
Ans. In data mining, the data is used to find patterns and relations, allowing for a better understanding of them. Various tools are deployed to perform corporate analysis, risk management, fraud detection, market analysis, etc.
On the other hand, data warehousing provides a platform for cleaning, integrating, and consolidating the data to be mined. Query tools are used to extract the required data in the required format so that the relevant data mining tools and techniques can be deployed for creating reports.
Conclusion
Data warehousing is crucial today, where information-driven decision-making is becoming the norm. More and more companies today expect you to know about data warehouses, and you can expect questions about data warehousing in your interviews.
While the important questions discussed in this article about data warehousing and data mining will give you a head start, you should explore this topic more and reach the maximum level of preparation for your interview involving data warehouses.
Additional FAQs.
1) What are the four stages of a data warehouse?
The four stages of data warehouses refer to the key stages of its development cycle. These stages are-
- Planning and Defining Objectives
- Designing and defining the architecture
- Building a physical data warehouse and deploying ETL processes
- Deploying and maintaining data warehouse
2) What are the four key components of a data warehouse?
There are four key components to any data warehouse. These are-
- Data Sources
- ETL Processes
- Database
- BI Tools
We hope these questions help you prepare better for your upcoming interview or at least know the kind of knowledge you must have before you start applying for relevant roles.





