
There has been an increasing need to deal with large volumes of data across various sectors around the globe. Few statistics show that companies today deal with volumes of data they have never dealt with before. Companies, therefore, are increasingly spending large sums of money on big data analytics.
In 2022, $274.3 billion was spent by companies alone on projects involving big data.
The widespread adoption of big data has put professionals with big data skills in high demand. However, numerous buzzwords that have gained popularity over time are discussed when exploring big data technologies. These include terms like “Data Warehouse,” “Data Mart,” “Data Lake,” and “Delta Lake,” etc., which refer to approaches to data management.
While the technologies these terms represent may not be directly under the big data domain, they work closely with the various big data technologies. Therefore, you must know what these terms mean, their similarities and differences, etc. This article gives you a detailed insight into all these buzzwords.
To learn more about related Data Science Concepts and Terminologies, download our Data Science Bible Book
What is a Data Warehouse?
Companies today lay a lot of emphasis on data-backed decision-making. This ensures that the decisions taken by the leadership are backed by scientific means. To make such decisions, the top management needs reports that can give them situational awareness about the organization and its operating environment.
Mining data can help create these reports, bringing the hidden patterns to the surface. The issue, however, is that the data required by the data science professional is often not readily available. It is often scattered across the organizations in formats that may not be compatible with the data mining tools. This is where data warehouses have their role.
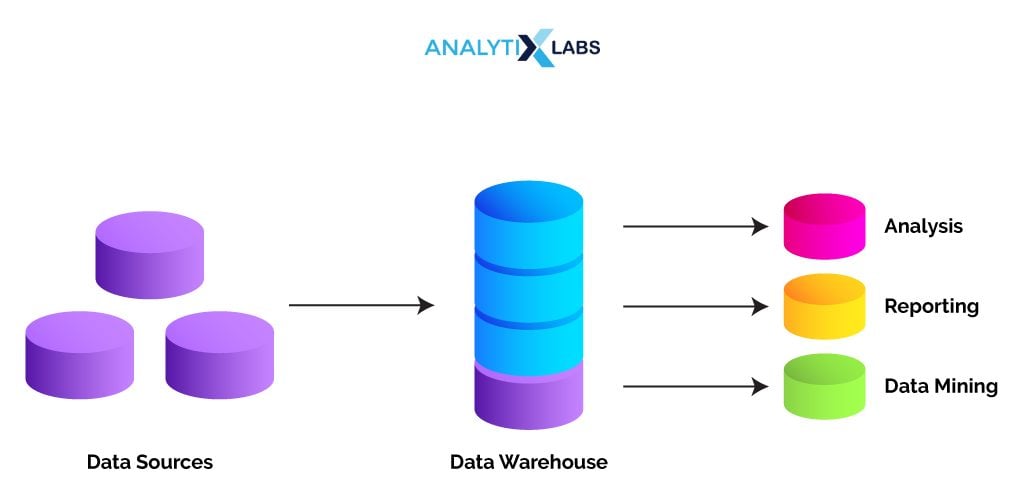
Data warehouses act as a central repository for an organization where data is loaded from different sources available within (and sometimes outside) the organization. A data warehouse, therefore, typically has historical data derived from transaction data belonging to one or more sources.
Also read: Data Warehouse Interview QnAs
There are a few peculiar characteristics of a data warehouse that can help you better understand it, such as
-
Subject Oriented
Data warehouses are designed to serve a particular business need and to make decisions around a particular business subject. A data warehouse, therefore, has data (information) around a particular subject. Sometimes, it excludes information that its user does not need to understand that subject. For example, a data warehouse may be created to understand sales or customer behavior and. Therefore, it will contain data concerning this subject.
-
Integrated
Data warehouses integrate data from heterogeneous sources such as flat files, online transaction records, and RDBMS. As the data is stored in a consolidated structured format, it is cleaned and processed to be consistent in its naming convention, attributes type, etc.
-
Time Variant
Generally, data warehouses store historical data, which is often indexed by time so that data can be easily retrieved for specific periods. However, it is possible to store and process real-time streaming data.
-
Non-Volatile
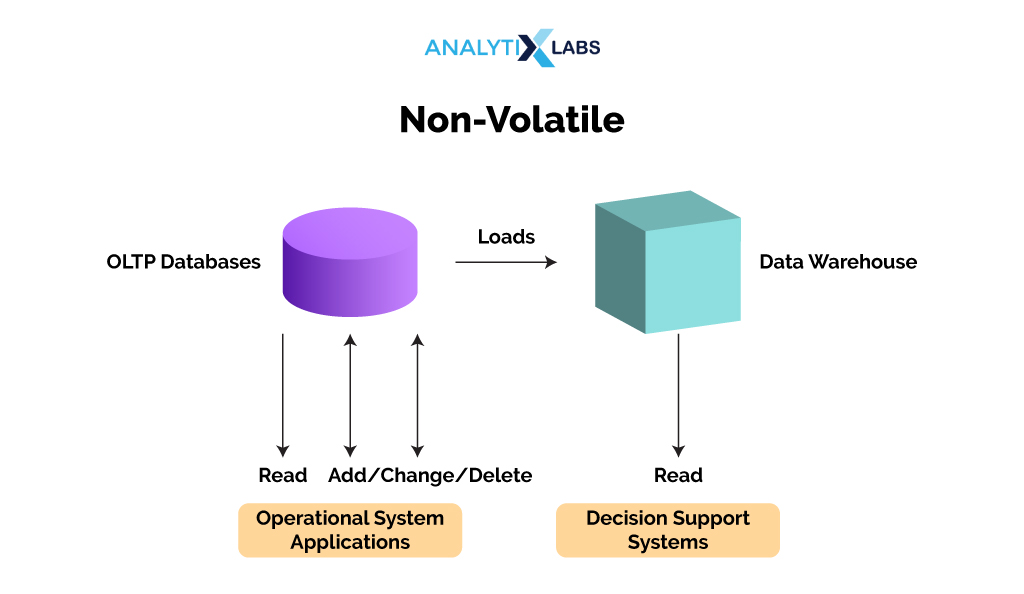
Data Warehouses provide physically separate data storage. Therefore, operational updates like updation, insertion, or deletion of data do occur in the data warehouse. Thus, the data typically remains unchanged once it is entered into the data warehouse. Any changes to the data are done in its corresponding database, making the data warehouse a stable platform.
Thus, a data warehouse is primarily responsible for maintaining the organization’s historical information and acts as the foundation for its decision-making capabilities, as the analysis and reporting are done based on the available data.
Organizations now turn to data warehouses to quickly analyze summarized historical data, enhancing strategic decision-making. However, rising data volumes necessitate embracing another vital tool – the Data Lake.
To understand the comparison between a data lake and a data warehouse, it’s crucial to grasp the concept of a data lake. But first, a small note-
Explore our signature data science courses and join us for experiential learning that will transform your career. We have elaborate courses on AI, ML engineering, and business analytics. Engage in a learning module that fits your needs – classroom, online, and blended eLearning. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
What is a Data Lake?
Companies often face challenges utilizing data warehouses due to the diverse nature of their data—generated or captured in various structures. The time and resources needed to clean and structure such data for data warehouse storage can be inadequate. In these situations, organizations need a space to store raw data until it’s ready for further analysis. This is where data lakes play a crucial role.
A data lake serves as a storage repository for organizations, allowing quick loading of large volumes of data. Unlike a data warehouse, it employs a flat architecture, storing data in its native format through object storage rather than hierarchical tables. This approach provides greater flexibility regarding data storage, usage, and management.
You need to be aware of a few more aspects of data lakes to understand them better.
-
Big Data and Data Lake
Big data and Data lakes are often considered closely related because data lakes often store big data that are often in different formats (structured to unstructured data). Also, a data lake is often built on Hadoop systems as it allows for using the distributed processing framework.
As big data cannot easily fit into the rigid schema requirement of data warehouses and is not compatible with their environment, it relies on data lakes as they can support numerous schemas. Therefore, organizations today rely heavily on data lakes as a platform for performing big data or advanced analytics involving large amounts of untraditional data.
Also read: Quick Guide to Hadoop
-
Data Lake Design and Architecture
Data Lakes can be used in various ways using a combination of technologies. Let’s explore some data lake examples. Companies can deploy Hadoop with Hbase and the Spark processing engine, run a NoSQL database on top of HDFS, or go the cloud storage route and run Spark against data stored in AWS S3.
Various organizations adopt distinct data lake architectures to cater to their specific needs. The purposes served by data lakes also vary among companies. Some use data lakes as read-only storage dumps, while others filter and process data before ingestion. Many data lakes incorporate analytical sandboxes and dedicated storage spaces for specific individuals or departments, resulting in diverse data lakes across organizations.
-
Characteristics of Data Lakes
There are certain characteristics unique to data lakes that give them their unique identity. Some of these are as follows-
- Data lakes are highly flexible as they can hold any data from the source systems; thus, no kind of data is turned away.
- Data lakes can easily scale horizontally, allowing them to easily deal with large volumes of data from diverse sources.
- Data in a data lake can be stored in an untransformed or nearly untransformed state, thereby allowing it to be stored the way it was received from the source system.
- Data from data lakes can be transformed in an approach known as schema-on-read where, based on the need and analytical requirements, the data is modified and made to fit in a schema.
- Data Lakes follows a common folder structure with consistent naming conventions.
- Data Lakes typically integrates well with big data technologies like Apache Hive, Apache Spark, and Apache Hadoop for various data analytical processes.
- Data Lakes works well for real-time data ingestion, helping organizations perform real-time analytics.
- Users of data lakes are provided with a searchable data catalog for easy understanding of data.
- To identify sensitive data, a data classification taxonomy is associated with a data lake, allowing users to have information about the content, data type, usage scenarios, group of users, etc.
As these two data management platforms are clear, let’s explore the difference between a data lake and a data warehouse.
Data Lake Vs. Data Warehouse – Key Differences
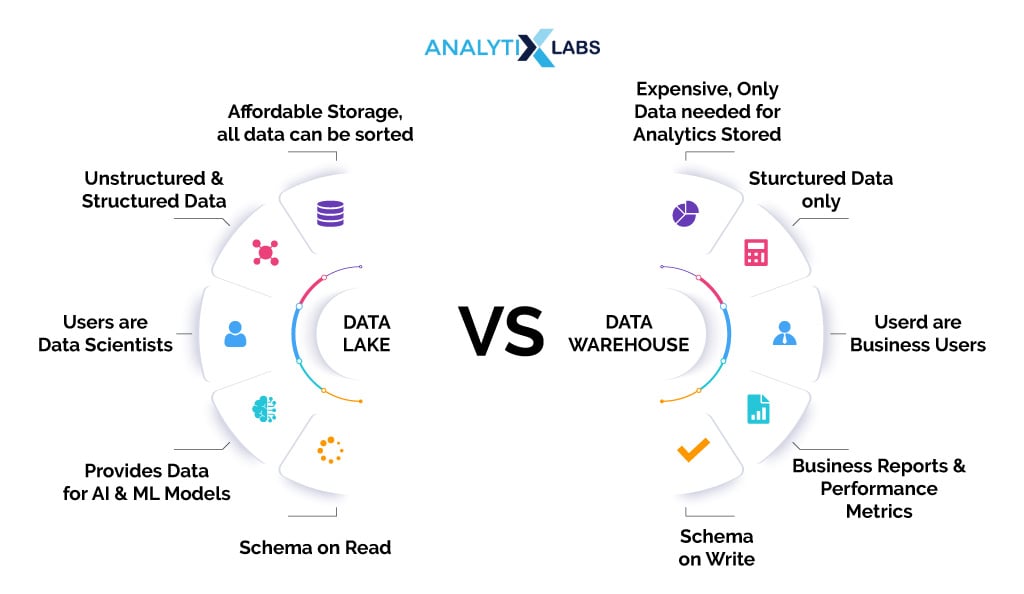
Data warehouses and data lakes are the two most popular data management platforms. Thus, it’s important to explore data lake vs data warehouse as both differ in a few crucial ways. The table below summarizes the key differences between data lake and data warehouse–
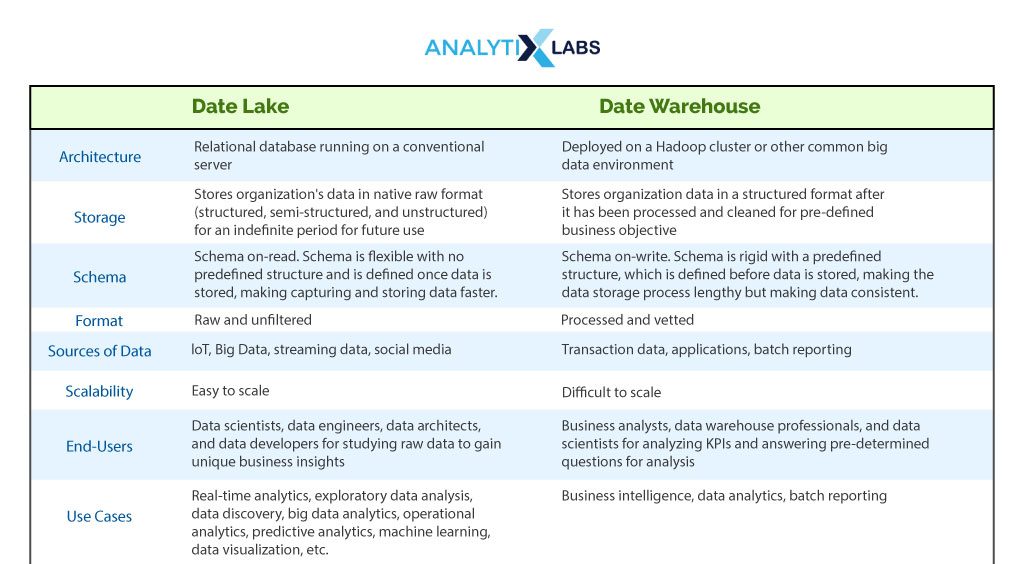
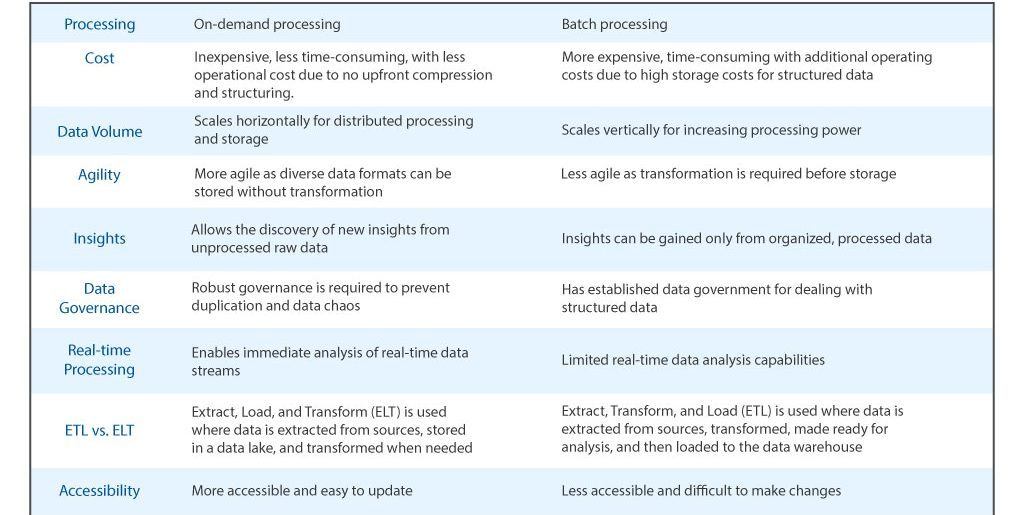

As you now know what a data lake and data warehouse are, let’s focus on another crucial data management technology: a data mart .
What is a Data Mart?
The Data Mart closely relates to and can be considered a subset of the Data Warehouse. If you recall, data warehouses are subject-oriented, and data marts are crucial in achieving this characteristic.
Data marts serve as focused repositories within the broader landscape of data warehousing. Unlike data warehouses that store data for the entire business, data marts specifically cater to distinct business divisions, facilitating streamlined data access for specific teams and employees.
Data marts are specialized subsets of a data warehouse designed for specific analytical needs in a particular business domain. They house summarized and aggregated data tailored for a specific business function, including metrics and key performance indicators. User-friendly and optimized for non-technical users, data marts offer quick access, querying, and analysis of relevant data.
They are derived from larger enterprise data warehouses, allowing users to aggregate domain-specific data within the overarching warehouse structure. Different types of data marts, including dependent, independent, and hybrid, can coexist within a data warehouse.
Given we have discussed three major types of data management platforms (data warehouses, data marts, and data lakes), let’s do a comparative study so that the distinction between data lake vs data warehouse vs data mart is completely clear.
Understanding Data Warehouses, Data Marts, and Data Lakes
When learning about data management, you often encounter three common terms: data warehouses, data marts, and data lakes. When comparing data warehouses and data lakes, introducing another data management technique, data mart, can add complexity and potentially lead to confusion. Below, we will learn some similarities and differences between these three data management techniques.
Similarities
Similarities between data warehouses, data marts, and data lakes are as follows.
- Cloud Options: All three have cloud storage options, and all major cloud service providers provide you with these storage techniques.
- Single Repository: They all allow you to integrate data from multiple sources using multiple pipelines and move data for storage into a central repository.
- Reliable Data: They all provide organizations with reliable data and preserve historical data.
- Querying Tools: SQL and other common languages can be used with all of them to extract data.
- Metadata: Access to metadata of the store information is provided by all three platforms.
- Scalability: All three platforms are extremely scalable, and their storage and other capabilities can be easily expanded depending on the data volume and business process requirements.
Differences
The three data storage and management platforms have a few key differences.
- Data Sources: Data warehouses and data lakes have multiple external and internal sources. In contrast, data marts have fewer sources, with the primary source being the parent data warehouse.
- Schema: Data warehouses and data marts require designing a particular schema to store data, whereas data lakes have no such requirements. Any type and format of data can be loaded onto them.
- Focus: Data warehouses and data lakes store data from multiple business units, allowing centralized and integrated data storage across the organization. Data marts focus mainly on one subject and are more decentralized, often filtering data from other existing data warehouses.
- Data Quality: In data warehouses and marts, the data quality is much superior to that of data lakes. This is because they perform several data accuracy checks, which is false with data lakes.
- Utilization: Multiple projects and departments utilize data warehouses and data lakes and have a much longer lifespan. In contrast, data marts are project-focused and have limited usage and lifespan.
- Design: Data warehouses and data marts use a top-down approach, whereas data marts are for a bottom-up approach.
- Pre-processing: ETL tools are required to clean and transform data to be loaded onto data warehouses or data marts, whereas data lakes have much more flexibility and do not require much data pre-processing. Data lakes’ data is first loaded and then transformed using an ETL approach.
- Performance: In terms of performance, i.e., querying data, a data lake is fast, a data warehouse is faster, while a data mart is the fastest. This distinction arises because data lakes are for high storage volume and cost-effectiveness at a reasonable speed. While the other two platforms prioritize performance to generate reports efficiently.
While the discussion involves data lakes, it’s a good idea to explore a related concept, such as data lakehouse and delta lakes, which are becoming increasingly popular. This is something we will explore next.
Data Lake vs. Data Lakehouse vs. Delta Lake
Data Lakehouse and Delta Lake are two other platforms closely associated with Data Lakes. This section explores data lakehouse vs. data lake and delta lake vs. data lake. Let’s first understand what they are and then explore in what ways they are different from data lakes.
Data Lakehouse
Data warehouse and data lakes have their advantages and disadvantages. However, users wish to store data in a platform that provides both these platforms’ capabilities. This is why a new hybrid architectural approach, a data lakehouse, is emerging that combines the advantages and addresses the challenges associated with both platforms.
A data lakehouse allows users to store all types of data in various formats in a central repository. Like a data lake, a data warehouse can store large amounts of data in its native form. However, resembling a data warehouse, it imposes a schema to uphold data quality and consistency. Data lakehouses provide a data warehouse’s query and analytical capabilities at data lakes’ cost and storage capabilities.
Compared with a data lake, common differences between it and a data lakehouse are as follows.
- Storage and processing: In the data lakehouse, the storage and processing are unified and have the analytical capabilities of the data warehouse. Store diverse raw datasets in their native format while conducting structured and optimized analytics and queries like a data warehouse. Data lakes, on the other hand, lack structured processing capabilities.
- Schema: Data lakehouses allow for data structure evolution (schema evolution) without disrupting existing data or analytics, which is difficult in data lakes.
- ACID: Data alehouse provides transaction guarantees to maintain data consistency by incorporating ACID (Atomicity, Consistency, Isolation, Durability) transactions. In data lakes, no in-built support for such transactions is present.
- Analytical tools: Data lakehouses are more compatible with SQL-based querying and other common analytical tools, while data lakes rely on big data processing tools like Hive and Apache Spark.
Delta Lake
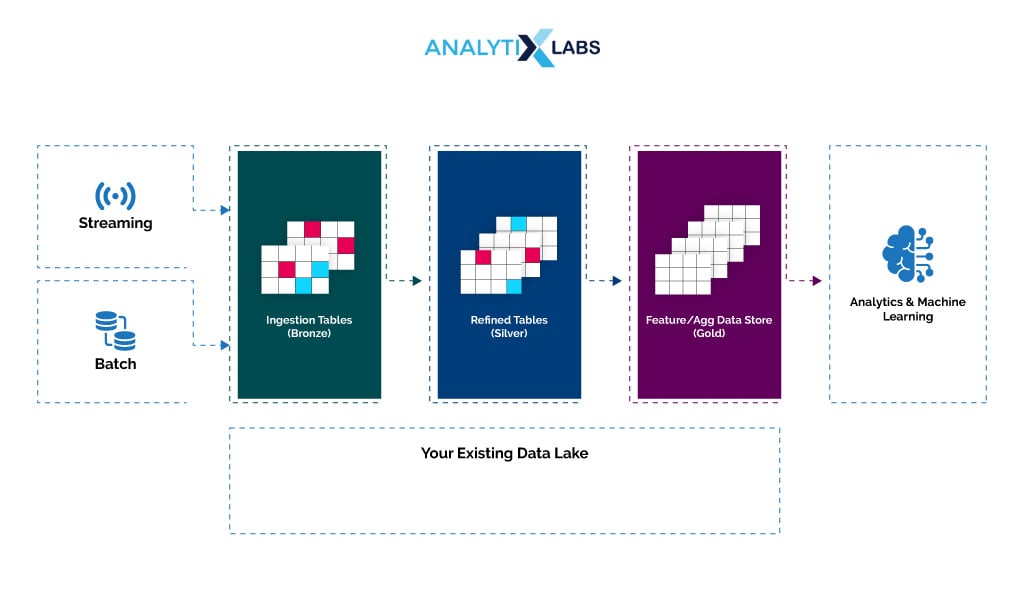
Delta Lake is similar to Data Lake but incorporates crucial features such as ACID transactions, lineage tracking, and schema enforcement. This makes this platform much more reliable and manageable than data lakes, making it ideal for streaming data applications. Each of these features is crucial.
ACID ensures that the data is consistent despite errors and failures. As ACID ensures that all changes in data are made as a single unit (using an all-or-nothing approach), the data becomes reliable the way it is in data warehouses. Schema enforcement, however, brings a consistent format to the stored data, allowing users to query and analyze it easily. Designers define a schema and use tools to enforce it in the delta lake.
Finally, lineage tracking in Delta Lake reveals data’s creation, processing, and transformation history, enabling users to audit data, adhere to regulations, and troubleshoot issues. Examples of delta lakes are Apache Delta Lake, Databricks Delta Lake, etc.
Below, we will explore Delta Lake vs Data Lake and focus on how Delta Lake is crucially different from the traditional Data Lake.
- Data format: The data in a data lake is raw, but in a delta lake, it has some format like JSON, Avro, or parquet.
- ACID Transactions, Schema Enforcement, and Lineage Tracking: Data lakes have no inbuilt support for ACID transactions, no schema enforcement, and do not track the data lineage. In contrast, delta lakes have all these features in-built.
- Reliability and Cost: Delta lakes are high in cost and reliability, while data lakes are low in both these aspects.
If you find data Lakehouse and Delta Lake similar, do remember they are different, with the most significant difference being as follows-
- Architecture: Data Lakehouse follows a hybrid architecture combining the best data warehouse and data lake capabilities. But Delta Lake is a data management system that runs on Apache Spark.
- Data warehouse features: Data lakehouses integrate several features of data warehouses, such as supporting optimized analytical queries. Delta lakes, in contrast, act more as a storage layer with some processing capabilities and don’t aim to replace data warehouses.
- Data Processing: Data lakehouses utilize SQL-based interfaces for simplified data access. Delta Lakes leverages Apache Spark, which excels in handling large data and executing complex workloads but presents greater operational complexity.
Lastly, big data is always somewhere in the background whenever these platforms are being discussed. Next, we will discuss how big data differs from the most common data storage platform – data warehouse.
Big Data vs. Data Warehouse
A common confusion occurs between big data vs. data warehouses as both these domains deal with large volumes of data. However, they are two different technologies. A data warehouse is a central repository for storing data from varied sources. Big data refers to analyzing large volumes of raw data generated daily.
Both these technologies involve integrating data from multiple sources, expanding the analytical capabilities of an organization, following a subject-oriented approach, and being time variant in nature. But they are different in a few ways. The key differences between big data and data warehouses are summarized in the table below:
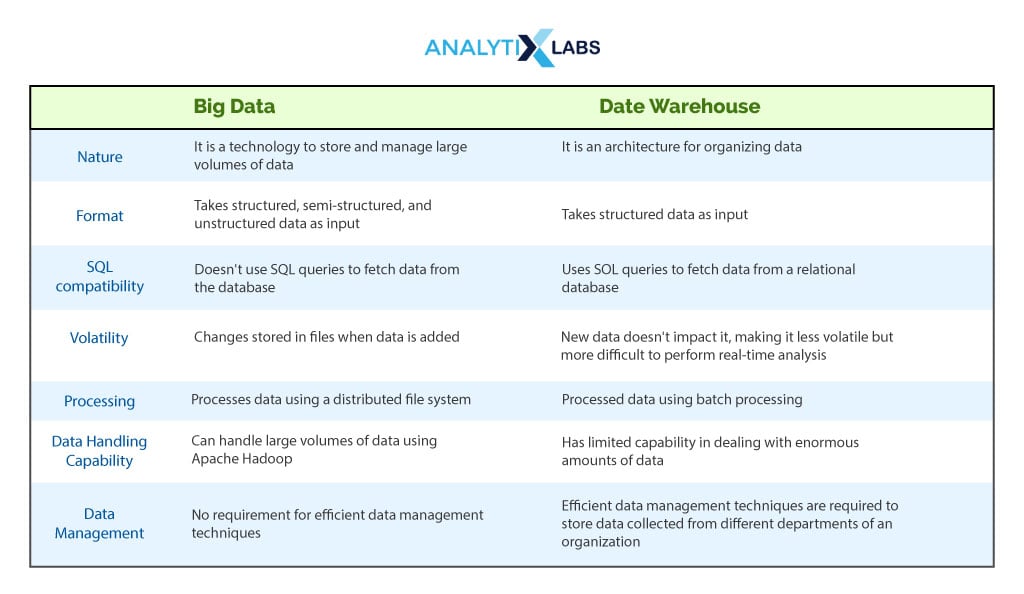
Conclusion
The demand for data management tools like a data warehouse, data mart, data lake, delta lake, etc., is on the rise, and so is the need for professionals who know such tools. The global data management market is set to grow to USD 122.9 billion by 2025.
The rising demand for data management professionals underscores the importance of staying up-to-date with relevant technologies in the field. It’s crucial to anticipate the transition from traditional to cloud-based data management platforms in the future. After all, the Cloud Database and DBaaS market size tends to reach USD 57.5 billion by 2028.
FAQs:
- Can data lake replace data warehouse?
In exploring a data lake vs a data warehouse, you must understand that the purpose of a data warehouse and a data lake is inherently different. While a data warehouse stores clean, processed, and structured data for analysis and reporting, a data lake stores unstructured, semi-structured, and unstructured data for flexible exploratory data analysis. Thus, these two technologies complement each other and are not replacements for each other.
- What is an example of a data lake?
A great data lake example is the Simple Storage Service (S3) bucket provided by Amazon Web Service (AWS) – a cloud platform. S3 is used as the foundation for building a data lake. It enables organizations to store large volumes of semi and unstructured data, such as videos, images, logs, JSON, CSV, etc., in the native format. Organizations engaged in complex big data analysis often use Amazon S3 to store data generated from IoT devices, social media feeds, weblogs, etc.
- What is the difference between data lake and data visualization?
Data Lake is a storage repository that allows for storing large amounts of data of diverse data types from various sources. It, therefore, helps organizations store large amounts of data in their native format with ease.
Data visualization, on the other hand, presents the insights from the data in a visual format through graphs and charts. It allows data science professionals to understand trends, patterns, and complex information with high interpretability and ease. Thus, both these technologies are different. While one (data lake) is a data management technique, the other (data visualization) is a data analysis technique.
- What is the difference between a data lake and cloud storage?
Data lake and cloud storage are distinct but related terms. While both these technologies deal with data storage and management, they differ in a few ways. While Data Lake stores large amounts of raw data without processing, cloud storage can do the same through storage objects like Amazon’s S3 and Azure’s Blob Storage, but it is much more secure and scalable.
Data lakes deployed in on-premises data centers have downstream processing and analytics tools associated with them, such as Apache Spark and Apache Hive. Cloud Storage, in contrast, can provide analytical tools within the ecosystems, such as AWS providing Athena or Google providing BigQiery.
Therefore, while data lake is a specific data storage tool, cloud storage is a more general purpose that can provide capabilities comparable to the data lake.





