
In today’s competitive business landscape, accessing and analyzing huge quantities of data is crucial for staying ahead. Effective data analytics is the key solution to address uncertainties, providing insights into customer preferences, company issues, and efficient operational strategies.
The challenge lies in efficiently managing the vast and swiftly generated data as companies endeavor to capture and process it systematically. One solution is to establish data pipelines. These pipelines are engineered to gather data from diverse sources, store it, and offer seamless access without inconsistencies . This comprehensive procedure is referred to as Data Ingestion.
This article will focus on answering what data ingestion is and understanding its numerous related concepts, such as its type, basic elements, benefits, associated tools, differences with other processes, etc. Let’s start with defining data ingestion.
What is Data Ingestion?
Data ingestion is made up of two terms- data and ingestion. While data refers to any information a machine can process, ingestion means taking something in or absorbing it. In analytics-related data pipelines, the first step is a data ingestion, which aims to efficiently collect, load, and transform data for finding insights.
Ingestion of data is the obvious first step in this process. The data is collected from one or multiple sources, such as websites, applications, and third-party platforms, and is loaded onto an object store or staging area for further processing and analysis.
The issue with performing data ingestion is that the data sources can be diverse. It can be in large numbers, making the ingestion process inefficient and difficult to attain a decent speed. This is why, today, companies require individuals to have deep knowledge about this field to use the potentially available data effectively.
Before getting into the details and understanding its key elements, a quick note –
Explore our signature data science courses and join us for experiential learning that will transform your career. We have elaborate courses on AI, ML engineering, and business analytics. Engage in a learning module that fits your needs – classroom, online, and blended eLearning. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
Elements of Data Ingestion
There are three elements to a data ingestion process. These are source, destination, and cloud migration. Let us understand them one by one.
-
Source
Data ingestion aims to collect and load data. Therefore, one of the basic elements of data ingestion is the source. Here, source refers to any website or application that generates data relevant to your organization. Sources include CRM, customer applications, internal databases, third-party software, document stores, etc.
-
Destination
The next key element in data ingestion is the destination. In the data ingestion process, the data must be stored in a centralized system such as a data lake, a cloud data warehouse, or even an application like a messaging system, business intelligence tool, etc.
-
Cloud Migration
The final key element is cloud migration. Organizations can move to cloud-based storage and processing tools from traditional storage systems to perform data ingestion. This is essential for businesses today as data silos and handling large data loads are major hindrances in the effective use of data.
These three key elements are the basis of all the various operations performed under data ingestion. The next crucial concept is the various ways data ingestion can occur.
Types of Data Ingestion
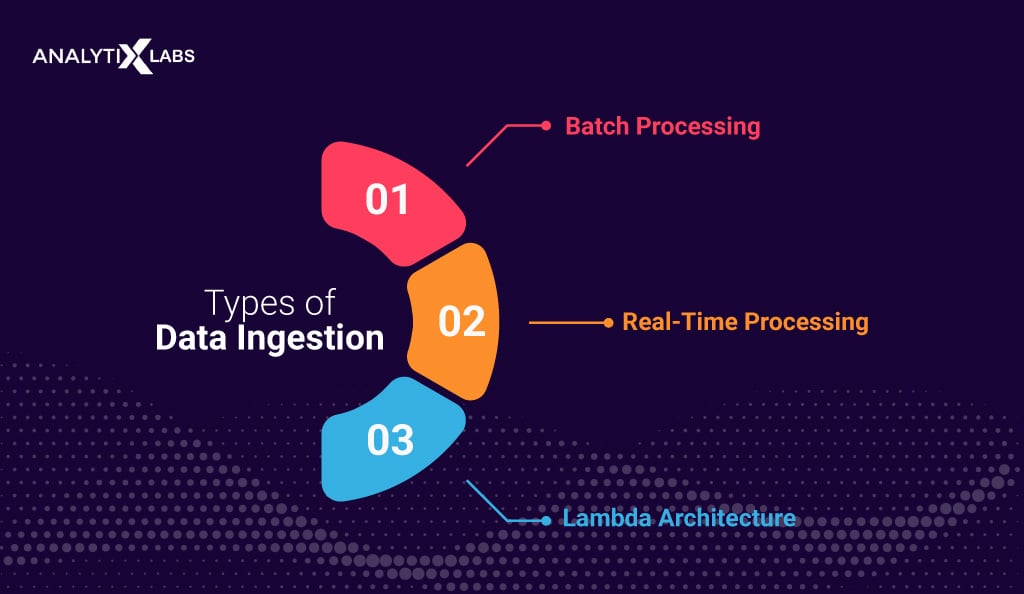
The ingestion of data can take place in many ways. There are primarily three ways through which data ingestion can be carried out. These include real-time, batch, and lambda.
The business organization chooses from these data ingestion methods based on their requirements, goals, financial situation, IT infrastructure, etc. Let’s understand these three types.
-
Batch Processing
Batch processing transfers historical data to a target system at scheduled intervals, triggered automatically, ordered logically, initiated by queries, or prompted by application events. While it doesn’t provide real-time data, it facilitates large historical dataset analysis, handling complex analyses. Microbatching, a variant, offers results akin to real-time data, catering to diverse analytical needs.
In micro-batching, the data is split into groups and ingested in small increments, simulating real-time streaming. For example, the extension of Spark API is Apache Spark Streaming, which performs micro-batch processing.
Lastly, being a traditional data ingestion mechanism, it is supported by ETL programs, allowing it to be adopted on a widespread level. Also, in such a mechanism, the raw data is converted to match the target system before loading it. This helps for accurate and systematic data analysis in the target repository.
-
Real-Time processing
Real-time processing, also known as stream processing, is a data ingestion method that allows data to be moved from source to destination in real time. In this process, rather than loading the data in batches, the data is moved from source to target as soon as the ingestion layer in the data pipeline recognizes it.
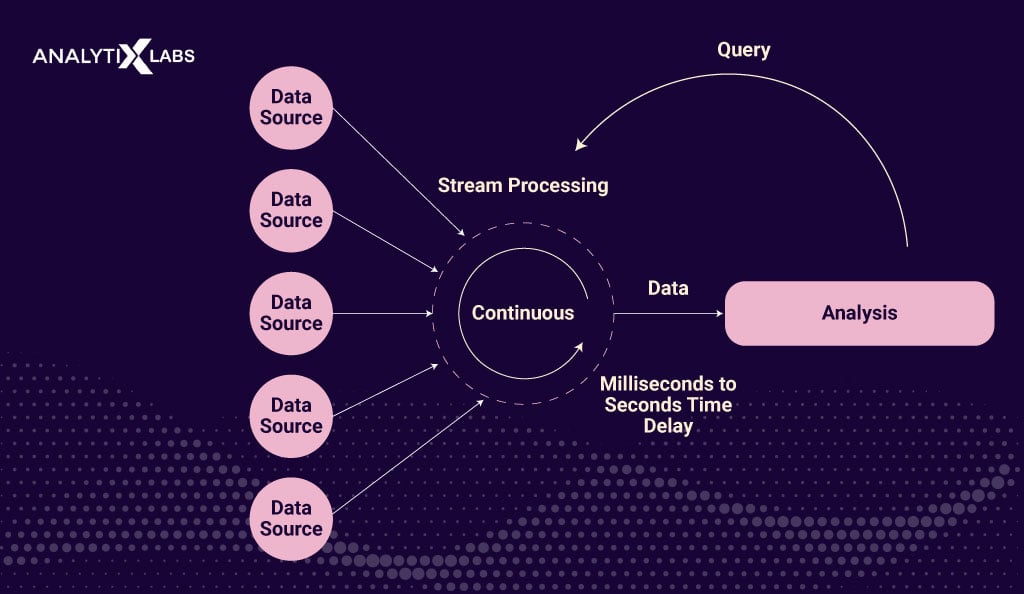
Leveraging real-time processing liberates data users from dependency on IT departments for extraction, transformation, and loading, enabling instant analysis of complete datasets for real-time reports and live dashboards.
Modern cloud platforms offer cost-effective solutions, facilitating the implementation of real-time data processing pipelines and empowering organizations with timely actions, like quick stock trading decisions.
A common data source is Apache Kafka, which is optimized for ingesting and transforming real-time streaming data. The fact that Kafka is open source makes it a highly versatile tool. Other advantages include its fast speed due to the decoupling of data streams, resulting in low latency and high scalability due to data being distributed across multiple servers.
Also Read: Flink vs. Kafka : Guide to Stream Processing Engines
-
Lambda Architecture
Lambda architecture, the final data ingestion type, merges batch and real-time processing. The ingestion layer comprises three layers: batch and serving layers index data in batches, while the speed layer indexes data not yet processed by the initial two slower layers.
This approach ensures perpetual balance among the three layers, guaranteeing continuous data availability for user queries with minimal latency.
Its chief advantage lies in offering a comprehensive view of historical data while concurrently reducing latency and mitigating the risk of data inconsistency. Regardless of the chosen data ingestion method, a standard framework and pipeline guide the process, with the subsequent sections elucidating the intricacies of the data ingestion framework, pipeline, and architecture.
Data Ingestion Framework and Pipeline
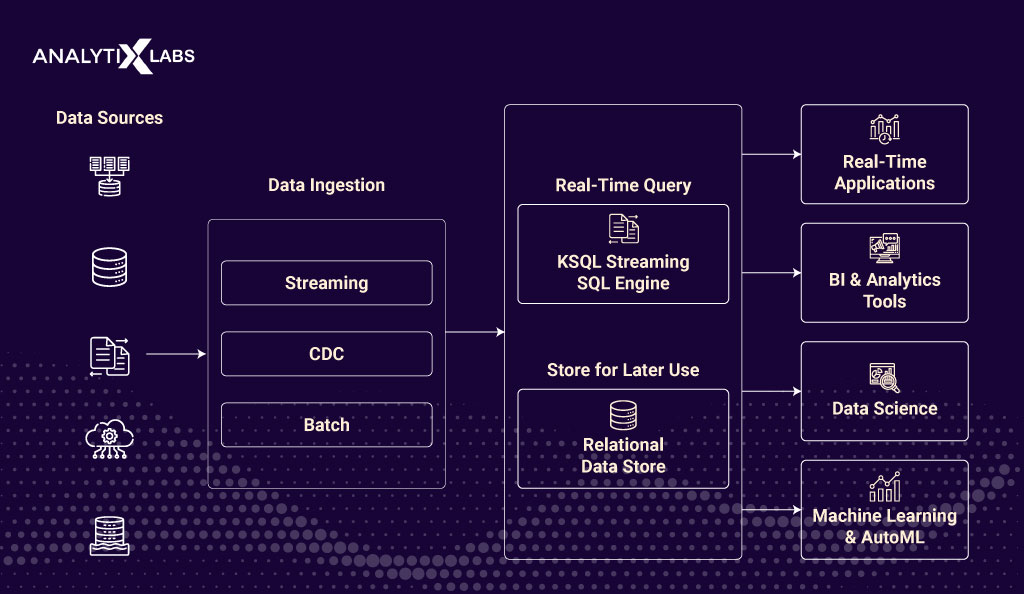
One needs to understand the data ingestion framework and the pipeline to understand the data ingest process better. Let’s understand these concepts below.
Data Ingestion Framework
The data ingestion framework is a unified framework that allows for extracting, transforming, and loading large datasets from multiple sources. Such a framework cannot only ingest data from varied sources in the same execution framework but also manage the metadata of these various sourced data in one place.
A good data ingestion framework has features such as high fault tolerance, auto scalability, extensibility, capability to handle model evolution, etc. Apache Gobblin is a common unified data ingestion framework for ingesting large volumes of data. It is particularly popular because it is an efficient, self-serving, and easy-to-use framework.
Data Ingestion Pipeline
The most crucial aspect of a data ingestion framework is how the data ingestion pipeline is designed. Let’s understand how a data ingestion pipeline can be created. Typically, the design of a data ingestion pipeline follows these key steps-
-
Step 1 – Identification of data sources
The first step is identifying what needs to be acquired, stored, and analyzed. The identification involves finding the relevant databases, data centers, servers, online sources, etc., that need access.
-
Step 2 – Identification of Destination System
The next step in building the data ingestion pipeline is identifying the system where the acquired data will be stored. The typical destination system includes data warehouses, data lakes, and other storage systems.
-
Step 3 – Identifying the Data Ingestion Method
The correct data ingestion method must be chosen based on business requirements, infrastructure availability, and financial constraints. Typically, the data ingestion can be either batch or real-time.
-
Step 4 – Design the Data Integration Process
Importing, processing, and loading the data into the target system must be carefully designed. The design should be such that the process gets automated to attain high accuracy and consistency.
-
Step 5- Monitoring and Optimization
A crucial step is to constantly monitor the performance of the data ingestion pipeline put in place. Based on the performance, necessary adjustments must be made to ensure the process runs efficiently.
You can better understand the data ingest process by understanding the framework and pipeline. To further understand what role data ingestion plays in the larger scheme of things, let’s understand the data ingestion architecture.
Data Ingestion Architecture
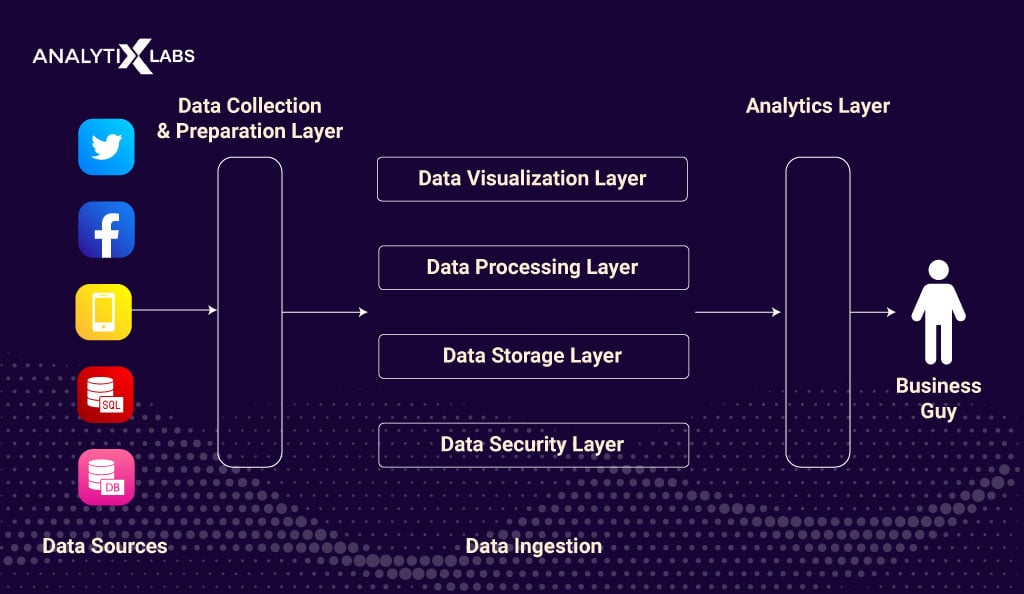
You can define the data flow by understanding the architecture of a data ingestion process. A typical data ingestion architecture consists of the following layers:
-
Ingestion Layer
The first layer of the data pipeline architecture is the data ingestion layer. This layer comes in contact with the various data sources and categorizes and prioritizes the data to determine the data flow for further processing.
-
Collector Layer
The purpose of this layer is to move data from the ingestion layer to the other layer of the data ingestion pipeline. Here, the data is broken for further analytical processing.
-
Processing Layer
This layer is the prime layer in a data ingestion pipeline processing system. This is because the data gained from the previous layer is processed in this layer. Here, data is classified and assigned to different destinations. Also, this is the first layer where the analytical process starts.
-
Storage Layer
The storage of the processed data is determined in this layer. The layer often performs complex tasks, especially when data is large. Here, the most efficient data storage location is identified for large amounts of data.
-
Query Layer
The primary analytical operations happen in this layer as it makes it feasible to query different operations on the data and prepare it for the next layers. The primary focus of this layer is to provide value addition to the data received from the previous layer and provide it to the next layer.
-
Visualization Layer
The final layer is the visualization layer, where the data is presented. It conveys to the user the value of the data in an understandable format.
You have now gained a decent understanding of data ingestion and how it works. It’s time to discuss the benefits of employing a data ingestion mechanism in your organizations.
Benefits of Data Ingestion
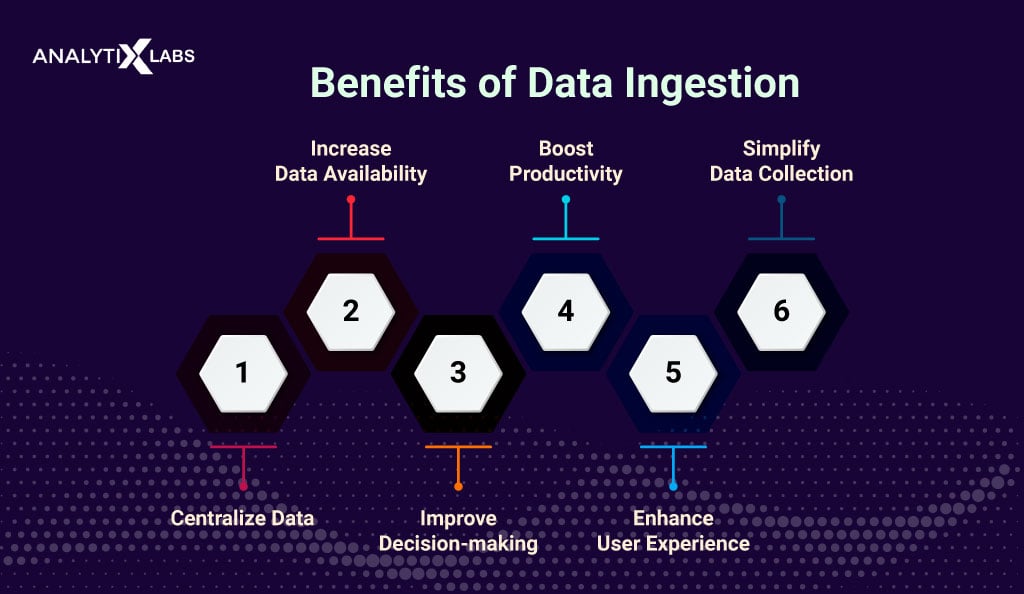
Data ingestion has several benefits as the foundational layer of your organization’s data analytics and integration architecture. The key benefits are the following-
-
Data Availability
Data ingestion allows the organizations to have the data readily available for analysis and other downstream applications.
-
Data Uniformity
Numerous data ingestion tools provide users with a unified business intelligence and analytics operations dataset. They achieve this by processing unstructured data and data in various formats into a unified dataset.
-
Data Transformation
Data Ingestion delivers data to target systems. It works in data pipelines that use ETL tools to transfer data from numerous sources (such as IoT devices, databases, data lakes, and SaaS applications) into predefined formats and structures. Thus, data ingestion plays a crucial role in effective data transformation.
-
Data Application
The ingested data can be used in numerous applications that help make the business more efficient, enhance customer experience, etc.
-
Data Insights
Data ingestion feeds business intelligence and analytics tools that, in turn, provide organizations with valuable insights about companies’ customer behavior, market trends, etc., crucial for business survival.
-
Data Automation
Data ingestion can help automate several manual tasks that help in increasing overall efficiency in the organization.
-
Data Complexity
The combination of ETL solutions and advanced data ingestion pipelines allows the transformation of various data types into data formats predefined by the data users. This allows for delivering complex data into data warehouses for further use.
-
Time and Money Saving
As discussed above, data ingestion helps automate various tasks related to data preparation. This not only ensures data quality and increased efficiency but also helps in cost-cutting and time-saving as the engineers that were earlier involved in the monotonous resource-consuming work of data transformation can dedicate their time to other important tasks.
-
Better Decision Making
Data ingestion, especially in real-time, allows for a real-time understanding of the environment in which the business is present. It helps the leadership to make informed decisions and identify opportunities and problems earlier than the competition.
-
Better Application Development
Numerous applications today are developed by feeding historical data to them. These include applications powered by machines and deep learning. Data Ingestion ensures that large amounts of quality data can move in quickly, helping software developers create better products.
-
Democratization of Data Analytics
Data Ingestion is now made available by several cloud platforms that allow small businesses to analyze big data and manage data spikes. This allows small companies to analyze the data and compete effectively with big players.
Despite the various benefits of incorporating data ingestion into a data pipeline, as highlighted earlier, it is also accompanied by several challenges. The following section delves into the common challenges associated with data ingestion.
Data Ingestion Challenges
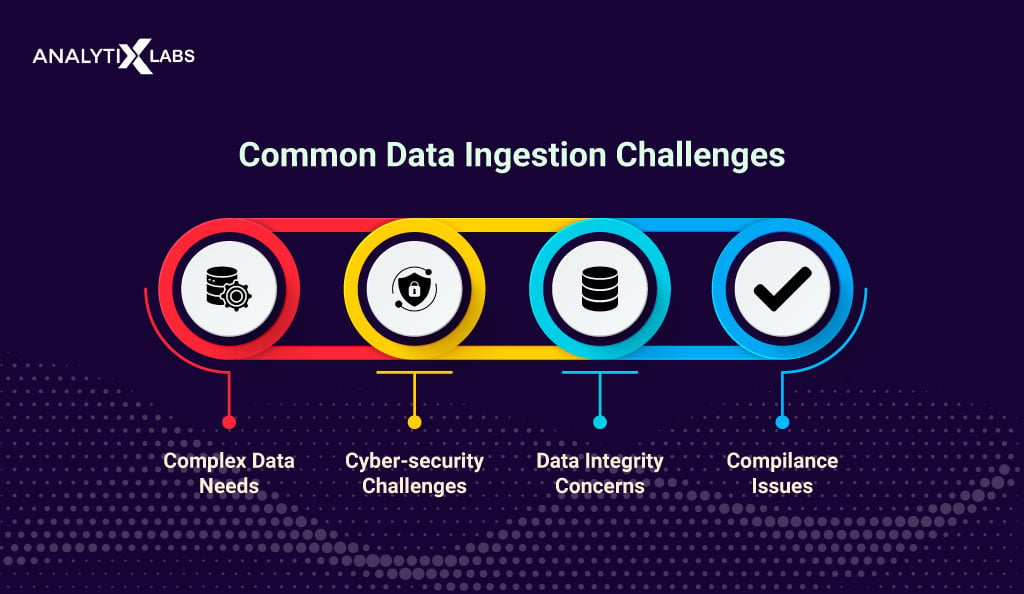
When creating data ingestion systems, data engineers and teams encounter several issues. The following are the major limitations of data ingestion.
-
Scalability
It is particularly difficult for the data ingestion pipeline to identify the correct format and structure of the data for the target destination applications, especially when the data in question is humongous.
Also, maintaining data consistency when it belongs to multiple sources is a complex task. In addition, data ingestion pipelines also encounter performance issues when dealing with data at a large scale.
-
Data Quality
One of the biggest challenges data ingestion faces is maintaining data quality and integrity. The data ingestion pipeline needs data that crosses a certain quality threshold to gain relevant informational insights.
-
Diverse Ecosystem
Today, an organization deals with numerous data types with varied formats, sources, structures, etc., making it difficult for data engineers to build a sound-proof ingestion framework.
Unfortunately, most tools support certain data ingestion technologies, forcing organizations to use multiple tools and train the workforce to have multiple skill sets.
-
Cost
The biggest difficulty operating a data ingestion pipeline is cost, particularly because maintaining the infrastructure required for running such a process increases as the data volume grows. Organizations need to invest heavily in acquiring servers and storage systems, causing the cost of running such operations to increase dramatically.
-
Security
Data security is an important issue in today’s world. Data ingestion faces cyber security challenges as data is exposed when stored at different points during the ingestion process.
The exposure makes the data ingestion pipeline vulnerable to security breaches and leakages. Often, the data is sensitive, which, if compromised, can cause serious damage to the organization’s reputation.
Also read: Roadmap to Becoming a Cyber Security Expert in India in 2024
-
Unreliability
Incorrect data ingestion can lead to misleading and unreliable insights from data, resulting in data integrity issues. The primary challenge lies in identifying irregular or corrupted data, which is challenging to detect and eliminate, especially when mixed with a large amount of correct data.
-
Data Integration
Data ingestion pipelines are often self-designed. These pipelines are often difficult to connect with other platforms and third-party applications.
-
Compliance Issues
Most governments today have framed privacy laws and regulatory standards that organizations must follow when dealing with public data. Therefore, data teams must create an ingestion process that complies with all the legalities, which can be challenging, frustrating, and time-consuming.
There are, however, many ways through which you can address the difficulties and challenges faced by data ingestion mentioned above and maximize its benefits. These best practices are discussed ahead.
Data Ingestion Best Practices

There are several best practices that, if you follow, can help you overcome the difficulties faced during the data ingestion process. The following are the most crucial best practices.
-
Network Bandwidth
A high amount of business traffic can jam up your data ingestion pipelines. Also, the traffic is not constant, and there are often data spikes in several parameters. Data engineers need to define the maximum amount of data that can be ingested at a particular instance, which they can do by defining the network bandwidth. This acts as a parameter that needs to be flexible and should be able to accommodate necessary throttling.
-
Support for Unreliable Network
Data can be unreliable due to the various data formats an organization is dealing with. Let us understand with an example. Suppose an organization is ingesting various kinds of data from different sources, such as images, videos, audio files, log files, etc..
Typically, different data formats have different data ingestion speeds. The data pipeline is unreliable when all such varied data gets ingested from the same point. Therefore, data engineers must design the data ingestion pipeline to support all data formats without becoming unreliable.
-
Heterogeneous Systems and Technologies
A major challenge of data ingestion pipelines is that they need to communicate with various third-party applications and operating systems. Therefore, during the design phase, the data engineers must ensure that the data ingestion pipeline is compatible with other systems.
-
Choose the Correct Data Format
You need to convert the different data formats into a generalized format to analyze data. A best practice is ensuring the correct data format is compatible with all data analytics tools employed in the organization. This helps make access easy for anyone who wishes to run the analytical operation on the data.
-
Streaming Data
Depending upon the business goal, a business must ensure if they need streaming data for their analytics work. If yes, then the type of data ingestion should be real-time and designed in such a way from the beginning.
-
Singular Image of Data
The data pipeline should be designed so that while it may take data from multiple sources, it should combine them and provide a single image of the data to generate better insights.
-
Connections
The data engineers designing a data ingestion framework must ensure that it supports new connections without any issues and needs to remove older connections.
Establishing new connections within the existing data ingestion framework often requires several days to a few months. Therefore, during the design phase, data engineers must ensure that implementing new connections can be done seamlessly.
-
Flexibility
The data ingestion must be designed to alter the intermediate process based on the business requirement.
-
Latency
Today, extracting data from APIs and databases frequently occurs in real time. This data extraction process is challenging and involves a certain level of latency. When designing the pipeline and downstream applications, it is essential to consider and account for this latency.
-
Collect Relevant Data
The data engineers must choose sources that provide relevant data at every process stage. This guarantees that time, money, and other resources are not wasted on processing irrelevant data.
-
Timestamp data
During the data ingestion process, data from various sources is merged. To uphold data integrity, data engineers must ensure they collect and match the associated unique identifier (UID) and timestamp with other data pieces during data collection.
While data ingestion can be used for any amount of data, it is particularly utilized when dealing with big data. Therefore, it is valuable to explore data ingestion in big data.
Data Ingestion in Big Data
Big data platforms heavily rely on data ingestion as data pipelines need to be built to manage the constant flow of data being made available to an organization. As the incoming data can greatly vary in volume, format, structure, etc., it becomes inevitable for organizations to use big data tools to ingest the incoming data.
When creating a data ingestion pipeline, users have to focus on various parameters important in big data processing, such as –
- Velocity as it deals with the flow of data coming from machines, social media sites, human interactions, etc.,
- Size as it deals with the workload volume that a data ingestion pipeline must go through.
- Frequency as data is coming constantly requires streaming data ingestion methods, whereas historical data can be dealt with batch processing.
- Format as it deals with the type of data (structured, semi-structured, or unstructured) being dealt with by the data ingestion pipeline.
Several technologies have been developed to handle data ingestion in the big data domain. One of them is Hadoop, which was discussed earlier.
Also read: Top 12 Big Data Skills You Must Have In 2024
Hadoop Data Ingestion
Hadoop is a distributed file system optimized for reading and writing large files, i.e., big data. As data ingestion in big data is a major issue, Hadoop Data Ingestion is commonly used, typically by bringing data pipelines into a data lake. This allows for moving data from multiple silo databases to Hadoop, where the data can be easily handled.
In big data, Hadoop data ingestion takes place by importing or moving files to Hadoop (or Data Lake, GCS, S3, etc.), loading it into a landing server, and using Hadoop CLI to ingest data.
While we are on the tools and technologies employed for data ingestion in big data, let’s also explore the numerous data ingestion tools available today.
Also read: Quick Guide to Hadoop
Data Ingestion Tools
Today, there are multiple data ingestion tools. Let’s understand some key concepts around it.
-
Types of Data Ingestion Tools
The most basic one is hand code, where one has to hand code a data pipeline using familiar language and create a complex ‘what-if’ architecture to move data around. Then, single-purpose tools provide a drag-and-drop interface, allowing you to skip hand coding.
However, monitoring and managing pipelines created using such a tool becomes difficult after a point. The traditional data integration platform comes in handy; however, they need developers and architecture having domain-specific knowledge, making them slow and rigid. This is why today’s DataOps approach is much better, where the data pipelines are mostly automated.
-
Capabilities of Data Ingestion Tools
A good data ingestion performs the typical duties of data extraction, processing, and transformation but also has good security and privacy features along with the capability of scalability, data flow tracking, and visualization.
Sophisticated data ingestion tools today also provide a unified experience that allows users to handle unstructured data and schema drift, provide versatile connectivity and real-time data ingestion, and are largely cost-efficient.
-
Common Data Ingestion Tools
The common data ingestion tools available today are the following-
- Snowflake
- Microsoft Azure
- Amazon Web Services (AWS)
- Kafka
- Google Big Query
- Salesforce
- Apache Gobblin
- Apache Kafka
- Apache NiFi
- Amazon Kinesis
- Integrate.io
- Airbyte
- Hevo
- Matillion
- Precisely Connect
- Talend Data Fabric
This marks the end of the discussion on data ingestion. However, a few important concepts still need to be discussed. This is regarding the difference between data integration and other similar concepts, such as ETL and data integration. The next sections discuss the difference in data ingestion with these related concepts.
Data Ingestion vs. ETL
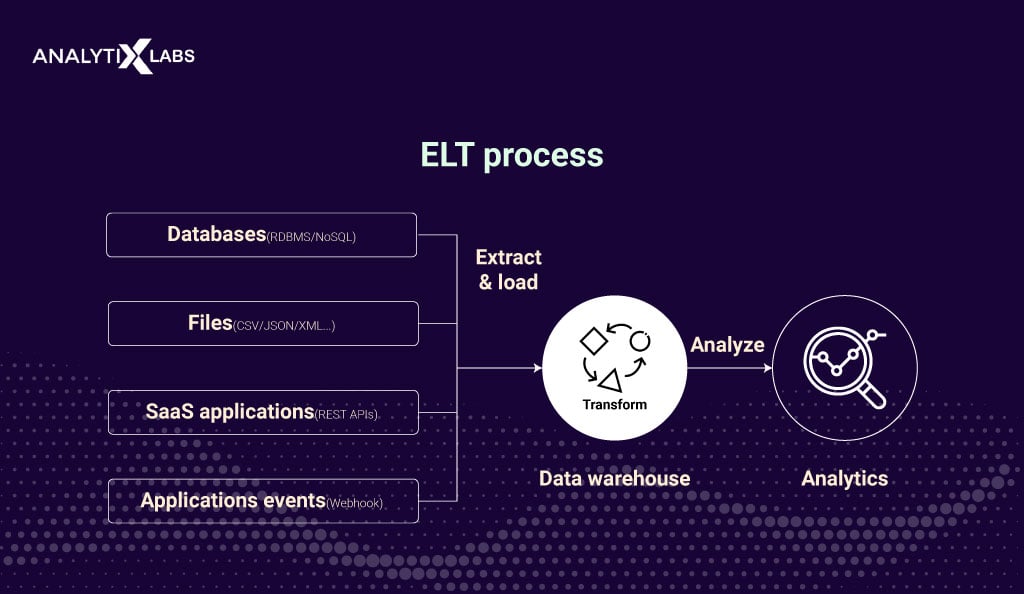
A concept commonly confused with data ingestion is ETL. ETL stands for extraction, transformation, and load. It is a data integration pipeline concept for extracting raw data from various sources, transforming it using secondary processing, and eventually loading and transforming data into a target database, typically a data warehouse.
These pipelines are particularly crucial in data transformation as they ensure the curating of high-quality data in a format that is ready to use. Common ETL tools include Stitch, Fivetran, Xplenty, etc.
On the other hand, data ingestion is a process utilized in data pipelines, where it collects raw data from various sources and transfers it to a centralized repository for further processing and analysis.
Now, if you look at the individual definitions, they seem similar, but there are a few crucial differences between them, as shown in the comparative table below.
Next, let’s also look at another concept commonly confused with data ingestion, which is data integration.
Data Ingestion vs. Data Integration
Data ingestion and data integration are two different but related concepts. They are related because data ingestion originated as a part of data integration, which is a much more complex process. Also, both concepts deal with moving data from one system to another. However, to comprehend the differences, let’s understand them individually.

-
Key Differences
- Data Ingestion is responsible for putting data into a database. On the other hand, data integration pulls the same data from the database and moves it to another system for further use.
- Data integration is more important when an organization needs to use one company’s product with another or when there is a need to combine your internal business process with the systems and processes of an external organization.
- Another key difference between the two is that data ingestion introduces data into a storage repository by involving ETL tools, allowing information to move from one source system (e.g., Marketing) to a repository (e.g., SQL Server).
- On the other hand, data integration involves combining various datasets into an integrated, generalized dataset or data model, which different departments’ applications can then use.
As previously mentioned, data ingestion is just a fraction of the broader data integration process. The conversation has delved into data ingestion and integration because these concepts are frequently intertwined.
Conclusion
Data Ingestion is a crucial process of a data pipeline. It ensures that the data entering the pipeline maintains its integrity and does not destabilize it. The data ingestion layer works with other layers, gathering data from various sources and moving to the next layer.
The final layer typically provides great insights into the data by visualizing it. In today’s world, where companies are trying their best to make sense of all the data at their disposal, knowledge of data ingestion becomes crucial, and you must explore more about this field.
Frequently Asked Questions
-
What is an example of data ingestion?
There are numerous examples of data ingestion, such as
- Getting the most out of a marketing campaign by ingesting a constant stream of data from numerous sources.
- Performing real-time data ingestion for making decisions in the stock market.
- Streaming data for infrastructure monitoring such as electricity grids, etc.
- Companies get daily activity reports to understand the performance of the business.
-
What is data collection and ingestion?
Data collection is the process of collecting raw data from various sources. In contrast, data ingestion involves dealing with the collected data and processing and preparing it to move it into a central repository for analysis.
We hope this article expands your knowledge of data ingestion. If you want to learn more similar data management and analytics concepts, feel free to contact us.





