
Ever since humans learned to communicate and exchange information, they have done their best to reduce the length or size of the information. Prior to the digital age, techniques like morse code were implemented. Later, telephones came into being, and voice transmission underwent innovations like cutting off high frequencies. Fast-forward to the present era – we are now dealing with information in digital form with the velocity, veracity, and volume increasing exponentially. As a result, data compression has become essential for efficient storage and transmission.
Why compress data?
Storing, managing, and transferring data becomes essential in data communication and other data-driven solutions. This is because no matter the degree of advancement in computer hardware (RAM, ROM, GPU) and forms of communication (internet), these resources are scarce.
To utilize these resources efficiently, the data is often required to be compressed, i.e., reduced to a smaller size without losing any or losing minimal information.
Varied kinds of data can be compressed. This includes numbers, text, video, images, audio, or even programs and software. These data types can be reduced in different ratios, such as 2:1, which means a data file with a 100 MB size can take up only 50MB of disk space after compression. This compression, also known as compaction, is performed through various compression techniques.
What is data compression technique?
data compression techniques in digital communication refer to the use of specific formulas and carefully designed algorithms used by a compression software or program to reduce the size of various kinds of data. There are particular types of such techniques that we will get into, but to have an overall understanding, we can focus on the principles.
Data compression can be performed by using smaller strings of bits (0s and 1s) in place of the original string and using a ‘dictionary’ to decompress the data if required. Other techniques include the introduction of pointers (references) to a string of bits that the compression program has become familiar with or removing redundant characters.
For a video, compression can be achieved by skipping every 3rd frame, as this will result (as one can imagine) in a 1/3 reduction in the size of the file. All such compression can dramatically reduce data size (in cases up to 70% or more without losing any significant data). Compression formats like ZIP, GZIP, etc., are used when transferring data via the internet.
The use of data compression techniques in digital communication greatly helps in reducing the time for a file transfer, the cost of storage, and traffic in the network.
Types of data compression techniques
While one can refer to this data compression technique PDF[source], to know about the various type of techniques available, the two common types that always stand out are:
- Lossy
- Lossless
Lossy compression
To understand the lossy compression technique, we must first understand the difference between data and information. Data is a raw, often unorganized collection of facts or values and can mean numbers, text, symbols, etc. On the other hand, Information brings context by carefully organizing the facts.
To put this in context, a black and white image of 4×6 inches in 100 dpi (dots per inch) will have 2,40,000 pixels. Each of these pixels contains data in the form of a number between 0 to 255, representing pixel density (0 being black and 255 being white).
This image as a whole can have some information like it is a picture of the 16th president of the USA- Abraham Lincoln. If we display an image in 50 dpi, i.e., in 60,000 pixels, the data required to save the image will reduce, and perhaps the quality too, but the information will remain intact. Only after considerable loss in data, we can lose the information. Below is an explanation of how it works.
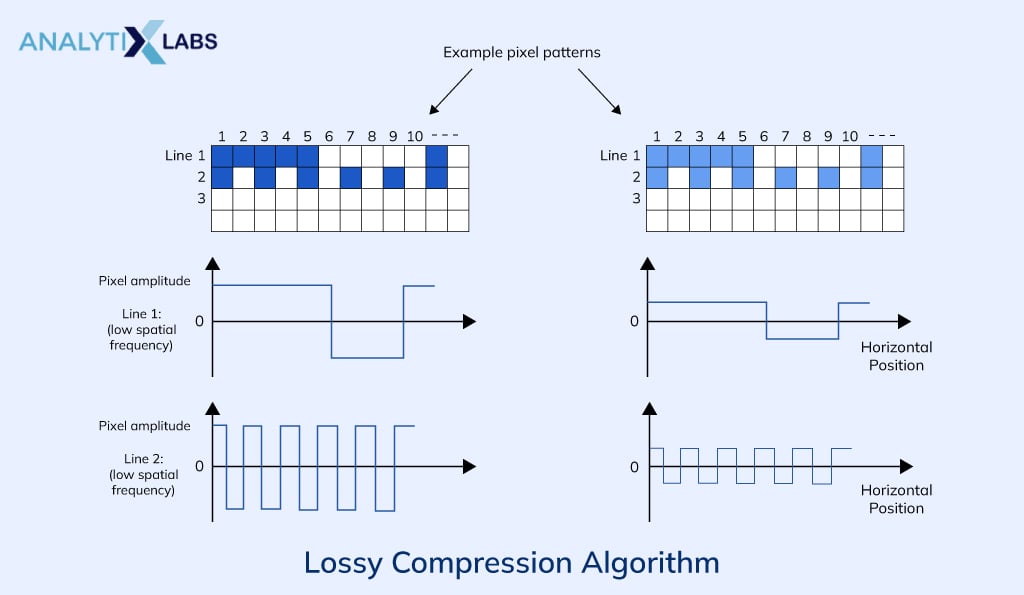
With the above understanding of the difference between data and information, we now can comprehend Lossy compression. As the name suggests, Lossy compression loses data, i.e., gets rid of it to reduce the size of the data.
Advantages and disadvantages of Lossy Compression
- Advantage:
The advantage of lossy compression is that it’s relatively quick, can reduce the file size dramatically, and the user can select the compression level. It is beneficial for compressing data like images, video, and even audio by taking advantage of the limitation of the human sense. This is because of the limit of our eyes and ears as they cannot perceive a difference in the quality of an image and audio before a certain point.
- Disadvantage:
The disadvantage of lossy is that decompression of data compressed through lossy will not return the same data (in terms of quality, size, etc.). Still, it will hold similar information (this, in fact, is useful in some instances, such as streaming or downloading content on the internet). However, on the flip side, constant downloading and uploading of a file can compress and consequently distort it beyond the point of recognition, causing permanent information loss. Similarly, if a severe level of compression is used by the user, then the output file might not be anywhere close to the original input file.
Lossless Compression
Lossless compression, unlike lossy compression, doesn’t remove any data; instead, it transforms it to reduce its size. To understand the concept, we can take a simple example.
There is a piece of text where the word ‘because’ is repeated quite often. The term is comprised of seven letters, and by using a shorthand or abbreviated version of it like ‘bcz’, we can transform the text. This information of replacing ‘because’ with ‘bcz’ can be stored in a dictionary for later use (during decompression).
- Methodology: While lossy compression removes redundant or unnoticeable pieces of data to reduce the size, lossless compression transforms it through encoding it by using some formula or logic. Here’s how lossless compression works.
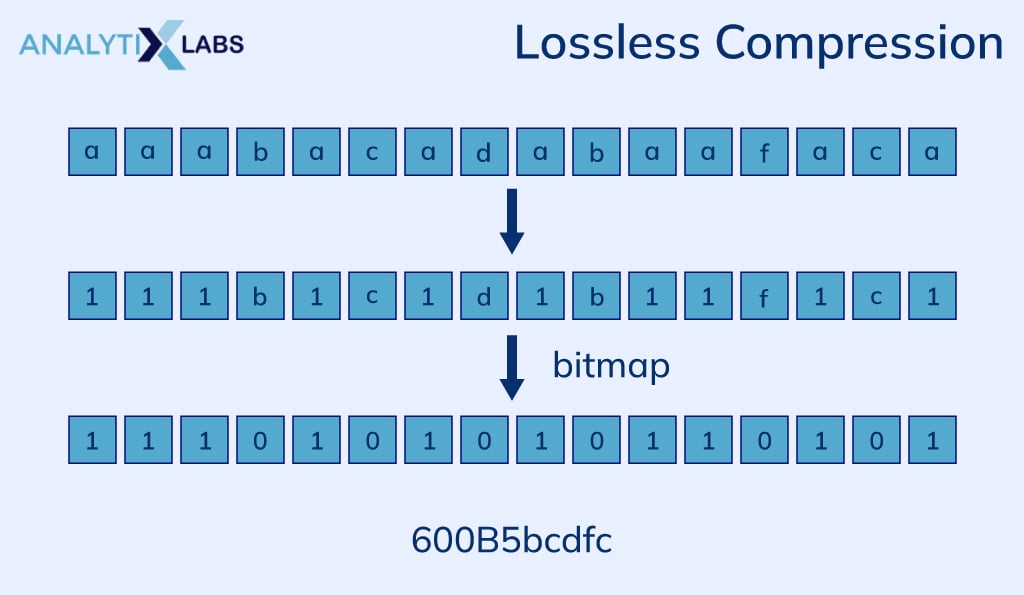
Advantages and disadvantages of Lossless Compression
- Advantage:
There are types of data where lossy compression is not feasible. For example, in a spreadsheet, software, program, or any data comprised of factual text or numbers, lossy cannot work as every number might be essential and can’t be considered redundant as any reduction will immediately cause loss of information. Here lossless compression becomes crucial as, upon decompression, the file can be restored to its original state without losing any data.
- Disadvantage:
There is a limit to data compression. If data is already compressed, then compressing it again will result in little to no reduction in its size. Also, it is less effective against larger file sizes.
Data Compression Techniques: Advantages and Disadvantages
There are several advantages of using the different data compression techniques discussed above, such as-
- Reduces the disk space occupied by the file.
- Reading and Writing of files can be done quickly.
- Increases the speed of transferring files through the internet and other networks.
Even with a range of advantages of the data compression techniques, there is a tradeoff as a cost is always associated with the compression of a file. This cost results in certain disadvantages such as-
- The processing time taken by complex data compression algorithms can be very high, especially if the data in question is large.
- Certain compression algorithms are resource-intensive and may cause the machine to go out of memory.
- There is a dependency on software that decompresses compressed files.
- The associated cost of compression can be monetary also, with certain software requiring you to pay licensing fee.
- Incompatibility issues can occur during decompression processes.
- Any error occurred during the transmission of compressed data can cause significant information loss.
Data Compression Technique Model
Let’s say, you refer to a research paper or a technical data compression techniques pdf. In that case, you will find numerous types of data compression models that use different compression algorithms pertaining to the two compression techniques discussed above.
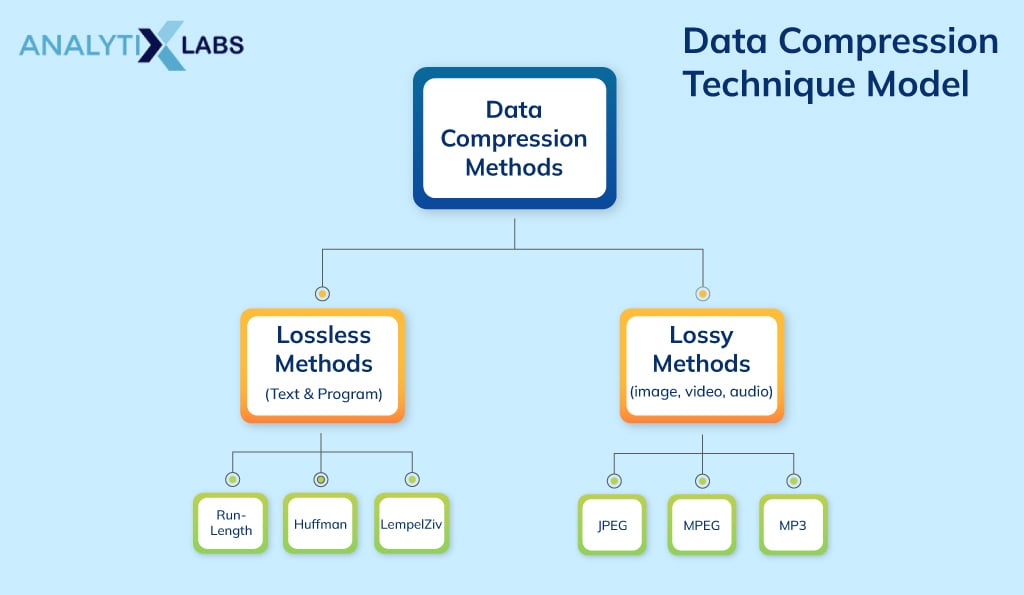
Following are the most common data compression models-
Lossless compression technique models
The most common models based on lossless technique are-
- RLE (Run Length Encoding)
- Dictionary Coder (LZ77, LZ78, LZR, LZW, LZSS, LZMA, LZMA2)
- Prediction by Partial Matching (PPM)
- Deflate
- Content Mixing
- Huffman Encoding
- Adaptive Huffman Coding
- Shannon Fano Encoding
- Arithmetic Encoding
- Lempel Ziv Welch Encoding
- ZStandard
- Bzip2 (Burrows and Wheeler)
Lossy compression technique models-
The most common models based on the lossy technique are-
- Transform coding
- Discrete Cosine Transform
- Discrete Wavelet Transform
- Fractal Compression
Neural network-based models
Some neural network-based models are also used for compression, such as-
- Multilayer Perceptron (MLP) based compression (used for image compression)
- Convolutional Neural Network (CNN) based compression such as Deep Coder (used for video compression)
- Generative AdversualNetwork (GAN) based compression (used for real-time compression)
This is all about data compression techniques. If you have any questions on how these models function, we are happy to help. Meanwhile, here are a few commonly asked questions on data compression techniques.
Data Compression Techniques: FAQs
1. What are some common data compression examples?
Data compression is used whenever there is a need to reduce the size of data. Common examples include:
- Image compression: Certain digit cameras compress the images for efficient storage. Also, to address the reduction in camera speed due to large raw images, compression is done. This is why the images are often saved as a jpeg that uses lossy data compression technique of data compression compared to png that uses lossless compression.

- Audio compression: A few years back, the team working on the standards of audio and video systems identified the advantages of the representation of audio data digitally. This group, known as MPEG (Motion Pictures Experts Group), came up with an audio-video encoding mechanism known as MPEG-1. The most common form of audio compression is mp3, i.e., MPEG-1 Layer 3, where each successive layer gets more complex and removes redundant data. Mp3 is a lossy compression, which can reduce the quality; however, its lossless counterparts, such as audio in WAV and FLAC format, can also be used. All such formats are used to store audio on CD/DVD, stream music on websites, etc.

- Disk compression: Most Operating Systems include some form of compression to store data on the disk. While the compressed files require more time for the OS to access, the upside is the quick processing speed gained from this compression.
- Archive files: Multiple files can be placed in a file that can then be compressed. Here file formats like ZIP and RAR come in handy, and this helps in the ease of transferring files and creating their backup.
2. What is the compression technique in data compression?
There are broadly two types of data compression techniques—lossy and lossless. In lossy, the insignificant piece of data is removed to reduce the size, while in lossless compression, the data is transformed through encoding, and its size is reduced.
3. What is used for data compression?
Traditionally, devices like ‘Morse Key’ and ‘More Code Receiver’ were used to pass and receive information in Morse code, a type of data compression. Today, different software implements various types of models built on data compression algorithms. For example, in Linux and Windows, programs like gzip and ZIP are used respectively, whereas, on macOS, StuffIt is the standard tool to perform data compression. To achieve compression in videos, GIF (Graphics Interchange Format) format is used while JPEG (Joint Photographic Experts Group) is used for images.
Additional resources you can read:





