
Microsoft Excel is more than spreadsheets and numbers. For data analysts and scientists, it’s a go-to tool that makes exploring, cleaning, processing, and analyzing data easy. It is the starting point for professionals looking to explore the world of data as it lays down the basics that can open doors to more advanced analysis techniques.
This article will explore how MS Excel can be used for data exploration, analysis, and, most importantly, cleaning. The primary focus will, therefore, be on the various data-cleaning techniques in Excel. Before we go there, let’s understand the role of data cleaning in data analysis.
Why is Data Cleaning Important for Data Analysis?
Data cleaning is critical in almost all data analysis processes. A lack of data cleaning can cause data to have several impurities that can adversely impact the insights gained from it, leading the stakeholders to make wrong decisions. Therefore, data cleaning is crucial to ensure that the information in the data is relevant and accurate.
Data cleaning doesn’t happen in isolation and is often accompanied by various preprocessing steps that enhance data quality and efficiency. Analyzing data can take a lot of time, and if it is properly cleaned and processed, the effectiveness of the analytical tools can be improved.
Let’s have a look at the key data quality issues that are addressed through data cleaning techniques.
Common Data Quality Issues
Data can consist of many issues. The most common ones are-
- Inconsistent Format: It can occur when, for example, the date is in incorrect format, the column of a data has an incorrect data type, or the categories of a column are inconsistent, which causes issues during data aggregation, comparison, analysis, etc.
- Missing Values: While incomplete data can come up for various reasons, it can stunt the analytical potential of the data.
- Duplicates: Sometimes, records can appear multiple times, which can cause skewed analytical results, longer processing time, etc.
- Outliers: Outliers are values that significantly deviate from the data distribution. They can harm several key statistical measures, such as mean, leading to erroneous calculations.
While there can be many more issues (such as incorrect data, typos, etc.), the ones mentioned above are the key ones and need the most attention.
- Explore our Data Analytics and other ongoing courses here.
Have a question? Connect with us here. Follow us on social media for regular data updates and course help.
Now, let’s discuss Excel and how it can help solve the abovementioned issues.
Can You Use Excel to Clean Data?
MS Excel has great data-cleaning capabilities due to the various data-cleaning Excel formulas and tools it provides to the user. It offers Conditional Formatting to highlight different issues with data (such as outliers, duplicates, etc.).
In contrast, data-cleaning Excel functions and formulas like TRIM, PROPER, and SUBSTITUTE allow users to standardize and clean data. In addition, robust data cleaning tools in Excel, like PivotTables and Data Analysis, allow users to summarize and analyze data effectively.
To better understand Excel’s capabilities, let’s put it to use and explore some data-cleaning examples in Excel.
How to Analyze Data Using Excel?
Several data-cleaning Excel functions and tools allow you to explore and process data easily.
Note: We have used MS Excel 2016 for demonstration purposes.
To demonstrate Excel’s capabilities, we will use credit risk data (as shown below) that contains information about bank customers, their credit scores, and their loan approval status.
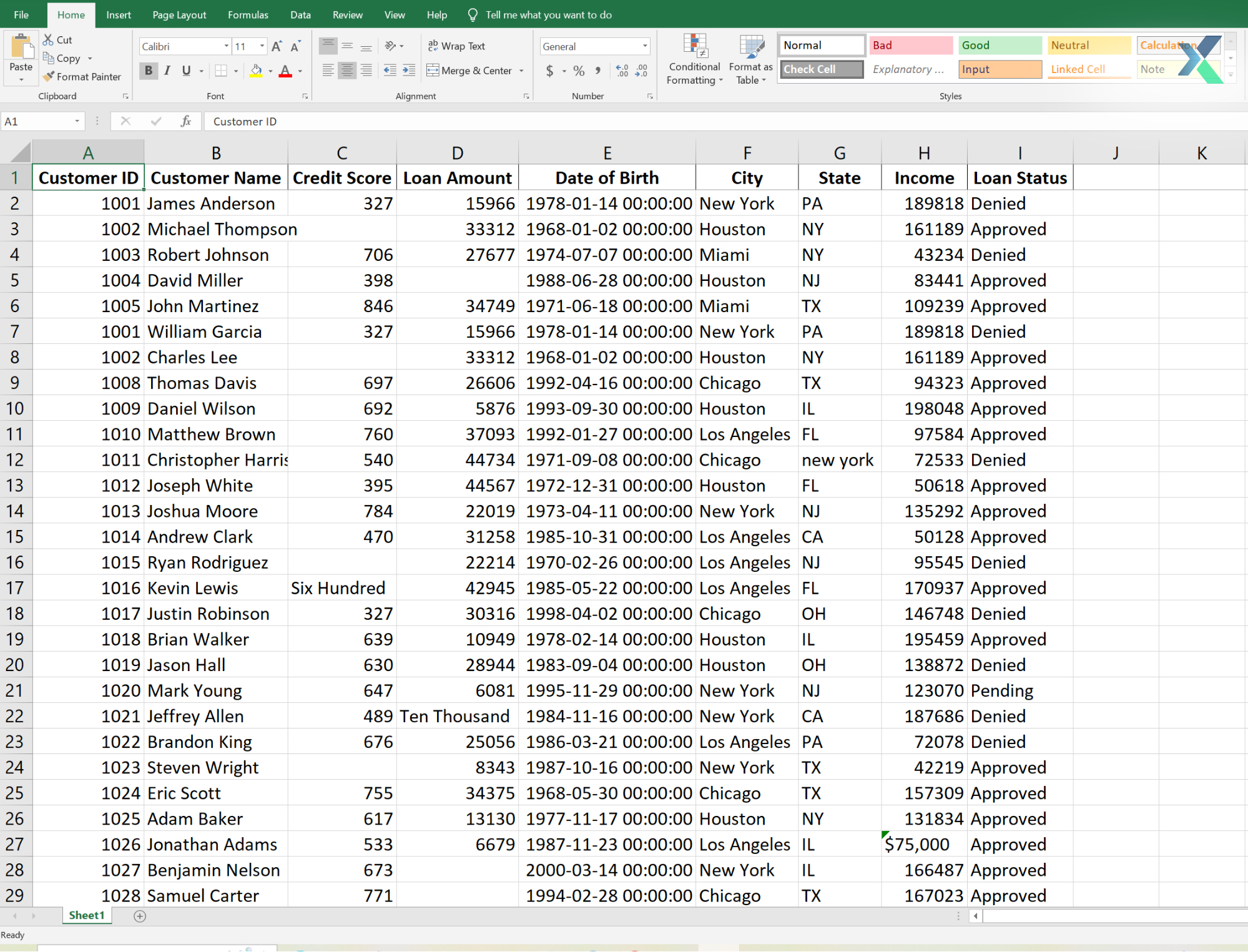
We will use this data to clean data. However, before cleaning data in an Excel spreadsheet, we will analyze exploratory data and identify the key issues.
Basic Data Exploration
The first step is to understand the data at hand. The following steps can help you do that using Excel.
1) Sorting by Custom Lists
You can sort the data using any particular column to understand it. For example, if you want to view the data such that it is sorted by the state column, then-
- Step 1: Select the column “State”.
- Step 2: Go to the ‘Home’ Tab >> ‘Editing group’
- Step 3: Select ‘Sort and Filter’
- Step 4: Select ‘Sort A-Z’

- Step 5: Select ‘Expand the selection’

- Step 6: Click ‘Sort’
All the data is sorted now based on the “State” column.

Just in case you want to organize the data based on a customer list, then you could do the same by following these steps-
- Step 1: Select the data
- Step 2: Go to ‘Data Tab’ → ‘Sort and Filter’ group
- Step 3: Select the ‘Sort’ dialog and choose the column you want to sort (“State” in our case)
- Step 4: Under the ‘Order’ column, choose Custom List.
- Step 5: Create or select a custom list (e.g., in our case, we will manually enter state abbreviations in the desired order) and click ‘OK’

- Step 6: Click ‘OK’ to apply the custom sorting.

The data is now sorted according to the customer order we provided.
P.S. We will sort it to the original form for the next function.
2) Filtering Data
If you want to view data based on a particular criteria, such as viewing records of customers belonging to California, then you can do it by applying filters to specific columns-
- Step 1: Select the Data Range (select the entire dataset in our case)
- Step 2: Go to ‘Data Tab’ → ‘Sort & Filter’ group >> Click on the ‘Filter’ button (flask-shaped)
- Step 3: Click the drop-down arrow in the column header you want to filter (in our case it is “State”)
- Step 4: Select Criteria: Choose specific values or use options like Text Filters or Number Filters (choose Text Filters, select and provide “CA”)

- Step 5: Click ‘OK’ to apply the filter

The data now only has records where the state is CA.
3) Conditional Formatting
To help you understand the data better, Excel provides conditional formatting that highlights cells that fulfill a specific condition. For example, we highlight cells with a loan amount between 10 and 30 thousand.
- Step 1: Select the Loan Amount Column (you can select the range of cells too)
- Step 2: Go to ‘Home’ Tab → Conditional Formatting (under ‘Styles’ group) → ‘Highlight Cells Rules’
- Step 3: Choose ‘Between’
- Step 4: Enter the lower and upper bounds (e.g., in our case, it’s between 10,000 and 30,000)
- Step 5: Select ‘Formatting Style’ (select red as a fill color) and click ‘OK’.

Conditional formatting is a powerful tool. By altering step 3, you can highlight cells with specific text, duplicates, etc.
How to Identify Data Types and Inconsistencies?
Once you have a brief idea about the data, the next stage is to identify its key issues, which will help you clean the data in an Excel spreadsheet. The key issues include incorrect data types, empty values, and other inconsistencies.
1) Check for Incorrect Formatting or Data Types
Columns pertain to specific data types such as text, numbers, dates, etc. However, if they are stored in incorrect format, they can cause problems when performing various data manipulation-related operations.
Therefore, it becomes critical to identify those cells where the format is incorrect so that any erroneous analytical insights can be avoided. In our dataset, the Credit Score column is not of numeric data type, indicating that there might be an incorrect formatting issue. We will perform the following steps to identify the cells causing the issue.
- Step 1: Select the column with formatting issues (it is “Credit Score” for me)
- Step 2: Go to the ‘Home’ Tab → under the ‘Styles’ group, select ‘Conditional Formatting’ → ‘New Rule’

- Step 3: In the New Formatting Rule dialog, choose the “Use a formula to determine which cells to format” option
- Step 4: Enter the following formula to detect text in a numeric column: =ISTEXT(C1) (entering C1 as “Credit Score” is in the C column).
- Step 5: Click ‘Format’, choose a color (we will choose red in our case) to highlight the cells, and then click ‘OK’.

- Step 6: Click ‘OK’ again to apply the rule.

Once done, the cells that contain text get highlighted, allowing you to treat them (either by deleting such cells or entering the correct numerical values).
2) Flagging Blanks or Null Values
Incomplete data can hinder your analysis, so it’s essential to identify those cells that contain blanks or null values. Conditional Formatting again comes in handy here as it allows you to highlight such cells.
- Step 1: Select the entire dataset
- Step 2: Go to Home Tab → under ‘Styles’ select ‘Conditional Formatting’ → ‘New Rule’
- Step 3: Choose ‘Format only cells that contain’
- Step 4: In the first drop-down, select ‘Blanks’
- Step 5: Select ‘Choose Formatting’ and pick a fill color (we picked yellow) to highlight blank cells.

- Step 6: Click ‘OK’.

This allows you to find all the empty cells.
3) Flagging Outliers
Outliers are abnormally large or small values. There are numerous ways of identifying them. Below, you will identify the outliers in the “Loan Amount” column using the IQR (inter-quartile) method.

- Step 1: Calculate the Quartiles (1st quartile (Q1) and 3rd quartile (Q3)) in an empty cell by using the following formula.
>Q1: =QUARTILE(D:D, 1) (using D:D as “Loan Amount” is in the D column in our data).
>Q3: =QUARTILE(D:D, 3)
- Step 2: Calculate the IQR in another cell by using the formula: =Q3 – Q1 (Q3 and Q1 cell references are L3 and L2 in our case)
- Step 3: Determine Outlier Boundaries by using the following formula
- Lower Bound: =Q1 – 1.5 * IQR (Q1 and IQR cell references are L2 and L4 respectively)
- Upper Bound: =Q3 + 1.5 * IQR (Q3 and IQR cell references are L3 and L4 respectively)

- Step 4: Flag the Outliers by using Conditional Formatting:
>Select the cells containing the loan amount values
>Go to ‘Home’ Tab → ‘Conditional Formatting’ → ‘New Rule’
>Select ‘Use a Formula to determine which cells to format’
>Enter the formula for highlighting lower outliers
[=D2 < $L$6 (here $L$6 is the cell reference containing the Lower Bound value)]
Choose a color to highlight the outliers (we will choose blue)

- Step 5: Repeat Step 4 but with the following formula and a different color to highlight upper outliers-
=D2 < $L$7 (here $L$7 is the cell reference containing the Upper Bound value)
We choose the color red to highlight upper outliers

4) Performing Consistency Checks
Another issue with data can be inconsistent values. This happens especially in categorical data where data is not provided uniformly. For example, labels can sometimes be abbreviated in different cases, etc.
To demonstrate this, you will consider the “State” column, which should have certain state names in an abbreviated format, and use Excel’s Data Validation option to identify inconsistent cells.
- Step 1: Select the cells with state values (in our case, it starts from G2 down to the last data row)
- Step 2: Go to the ‘Data’ Tab → under the ‘Data Tools’ group, select ‘Data Validation’ → ‘Data Validation’
- Step 3: In the ‘Settings’ tab, under the ‘Allow’ option, choose ‘List’ and enter valid state abbreviations (e.g., NY,CA,TX,FL,IL,NJ,PA,OH) as the allowed values in the ‘Source’ box.

- Step 4: Click ‘OK’

- Step 5: After setting data validation, return to the ‘Data Tab’
- Step 6: Click on ‘Data Validation’ → ‘Circle Invalid Data’
Excel will now circle any cells that don’t match your stated abbreviations. This allows you to identify entries like “new york” that are mentioned instead of “NY”. You can now manually review and correct circled entries to ensure all states are entered using abbreviations, ensuring consistency.

-
Data Cleaning
After identifying the issues, the next step is to correct them. In this section, we will provide numerous data cleaning examples in Excel by addressing the abovementioned issues and take a few more steps to clean and prepare the data further.
1) Removing Duplicates
To remove duplicates from the data, you can go through the following steps-
- Step 1: Select the complete Dataset (or the specific column(s) where duplicates might exist)
- Step 2: Go to the ‘Data’ Tab → under the ‘Data Tools’ group, select ‘Remove Duplicates’
- Step 3: In the dialog, select columns that you want to check for duplicates (e.g., we will select “Customer ID”)

- Step 4: Click OK.
Once done, Excel will provide a summary of duplicates found and removed.

2) Correcting Data Inconsistencies
In the previous section, you found inconsistencies like “New York” being mentioned instead of “NY”. To resolve this, you can perform Find and Replace by-
- Step 1: Select the column where find and replace is to be performed
- Step 2: Press Ctrl + H to open the ‘Find and Replace’ dialog box
- Step 3: In ‘Find what’, enter the incorrect value (we will mention “new york”)
- Step 4: Enter the correct value in ‘Replace with’ (we provide “NY”)

- Step 5: Click ‘Replace All’ to standardize the values

You can use the same methodology to solve other issues identified earlier, such as removing text or symbols in numerical columns to convert them into the correct data type.
Data cleaning Excel formulas can also resolve other hidden inconsistencies in the data. These include extra spaces, incorrect cases, etc., which can also be resolved by using formulas such as TRIM() and PROPER() or UPPER(), respectively.
3) Handling Missing Values
Several empty cells were identified previously. To better understand the data, filling the empty cells is imperative. Many data cleaning techniques in Excel can help you resolve such issues, with one such technique being missing value imputation. Below, we perform missing value imputation using the median in the “Credit Score” column.
- Step 1: Calculate the Median in an empty cell by typing the following formula: =MEDIAN(C:C) (we use C:C as the “Credit Score” is in the C column)

- Step 2: Copy the cell with the median value (by right-clicking the cell with the median value and choosing Copy or by pressing ‘Ctrl+C’) and paste it in the same cell as values (right click 🡪‘Paste Special’ 🡪‘Paste as values’)

- Step 3: Copy the median value (press’ Ctrl + C’ on the cell with the median value, which is now stored as a value)
- Step 4: Select the Column with missing values (select all the cells of the column “Credit Score”)

- Step 5: Select all of the empty cells by pressing ‘Ctrl + G’ → ‘Special’ → ‘Blanks’ → ‘OK’
- Step 6: Paste the copied median value in all the empty cells by pressing ‘Ctrl + V’

These steps eliminate the “Credit Score” columns’ empty cells.

We followed the same steps for the “Loan Amount” column, which had missing cells.
4) Outlier Capping
Apart from missing values, we also identified outliers in the previous section. One way to handle outliers is by capping, where values above the upper bound are capped at the upper limit, and values below the lower bound are capped at the lower limit, respectively. As you had already calculated the upper and lower bound values earlier, you can now use them to perform the capping.
- Step 1: Select the column next to the “Loan Amount” column and press “Ctrl + Shift + +” to add a new column.
- Step 2: Name the new column “Loan Amount Capped.”
- Step 3: In the first empty cell of this column, paste the following formula to cap values
= IF(D2 < $M$2, $M$2, IF(D2 > $M$3, $M$3, D2))

Note: $M$2 and $M$3 are the cell references to where the Lower Bound and Upper Bound are stored
This formula does the following:
>If the value is less than the lower bound, it sets the value to the lower bound
>If the value exceeds the upper bound, it sets the value to the upper bound
>Otherwise, it keeps the original value

- Step 4: Drag this formula down the column to apply the capping for all values in the “Loan Amount” column.
- Step 5: Copy the “Loan Amount Capped” column and paste it as values on top of the same column.
- Step 6: Delete the original Loan Amount column by selecting the column and pressing “Ctrl + -“
- Step 7: Rename the “Loan Amount Capped” to “Loan Amount”

5) Data Type Conversion
If the data is consistent, then its typecasting is extremely straightforward.

Let’s take the example of the “Date of Birth” column, whose data type is currently “Custom”.

As the column is inconsistent, you can simply select it and select an appropriate data type from the “Number Format” drop-down to perform type casting.

You can specify the strp code to have the dates in a particular format by following the required steps.
- Step 1: Go to the “Number Format” drop-down
- Step 2: Select “More Number Formats…”
- Step 3: Select “Number” Tab
- Step 4: Select “custom” under the “Category” section
- Step 5: Provide a custom date format under the “Type” option

The data was clean and consistent, so we typecasted all the required columns.
-
Creating Data Profiles
As the data is now clean, you can look forward to analyzing it. In this section, you will use various data cleaning tools in Excel to create various kinds of reports and graphs to find key insights about the data.
1) Summary statistics
You need the Analysis Toolpak to calculate summary statistics, which provides the ‘Data Analysis’ tool in the ‘Data’ tab. If you don’t have the necessary add-on, the tool might be missing from your ‘Data be making it look like-

To install the add-on, you first need to follow these steps-
- Step 1: Go to ‘File’ → ‘Options’ → ‘Add-ins’ → Under ‘Manage’ select ‘Excel Add-ins’ from the drop-down → select ‘Analysis Toolpak’ 🡪 Click ‘Go’

- Step 2: Select ‘Analysis ToolPak’ and click on ‘OK’

The ‘Data Analysis’ option will be available in the ‘Data’ tab under the ‘Analysis’ group.

As you have the necessary tool now, you can perform summary statistics by following these steps-

- Step 1: Go to ‘Data’ tab and select ‘Data Analysis’ from the ‘Analysis’ group
- Step 2: In the ‘Data Analysis’ dialog, select ‘Descriptive Statistics’ and click ‘OK’

- Step 3: Set ‘Input Range’ by choosing the column that is to be analyzed (e.g., we select the cells pertaining to “Loan Amount”)
- Step 4: Check the ‘Summary Statistics’ option
- Step 5: Click ‘OK’

This generates summary statistics for the intended column and provides metrics like mean, median, variance, standard deviation, etc.
2) Histograms
The ‘Data Analysis’ tool can also be used to create histograms.
This time, you will select ‘Histogram’ from the option.

You will then provide the range for the cells pertaining to “Loan Amount”, select ‘labels’ and ‘Chart Output’ and click ‘OK’.

This gives you a simple histogram plot of the “Loan Amount” column.

3) Data Summaries (using PivotTables)
The next step in analyzing data is creating summary tables. To do so, Excel has a wonderful function known as a Pivot Table that allows users to easily group and aggregate data. Below, you will group the data by loan status and aggregate it using the loan amount column.
- Step 1: Select the entire dataset (including headers)

- Step 2: Go to Insert Tab → PivotTable
>In the “Create PivotTable” dialog, ensure the data range you selected is correct.
>Choose where to place the PivotTable (new or existing worksheet; you select the new option)
>Click ‘OK’

- Step 3: Set PivotTable Fields by going to the ‘PivotTable Fields’ pane and dragging the following:
>’Loan Status’ to ‘Rows’ (this will allow you to use this column for group by)
>’Loan Amount’ to ‘Values’ (this will allow you to aggregate the data based on it)
- Step 4: Provide summary metrics by
> Clicking on the “Loan Amount” field in the ‘Values’ area (by default, the sum metric will be selected)
> Selecting ‘Value Field Settings…’
> Selecting a summary metric (e.g., ‘Count’)

- Step 5: Add additional metric
>Having other metrics, again drag the “Loan Amount” to ‘Values’
>Update the metric on the new “Loan Amount”
> Repeat until all the required metrics are implemented (you implement the following summary functions – ‘Average’, ‘Max’, and the default one, ‘Sum’
This PivotTable will summarize loan amounts grouped by the Loan Status and help us come up with the following insights-
- There are more accepted loan applications than rejected
- The total amount of accepted loans is significantly higher than the rejected
- There are few pending loan applications
4) Bar Charts (Frequency Plot)
Excel can also be used to visualize the data. Below, you will create a frequency bar plot for the “Loan Status” column.
- Step 1: Use the pivot table created earlier and copy-paste the first two columns separately.
- Step 2: Select the table (including headers).

- Step 3: Go to ‘Insert’ 🡪‘Insert Column or Bar Chart’ under the ‘Charts’ group

- Step 4: Select ‘Clustered Columns’

You can similarly use this combination of creating PivotTable (or simply slicing the required columns and copy-pasting them separately) and inserting graphs to create various kinds of plots such as pie charts, stacked bar plots, scatterplots, boxplots, etc.
-
Data Preprocessing
Various preprocessing steps must be performed to improve the data quality and prepare it for sophisticated analysis involving predictive models and complex statistical tests. You will explore some of the steps below using Excel.
Also read: Guide to Data Processing – Learn Types, Methods, Stages and its Role in ML
1) Data Normalization and Standardization
The data must often be on a standard scale for more accessible analysis and comparison. To do so, various data transformation techniques like normalization or standardization) are applied to ensure the data has a consistent range and distribution across the various (numerical) columns.
-
Normalization
Below, we will normalize all of the numerical columns in the data by
- Step 1: Creating New columns for the numerical columns

- Step 2: Applying the normalization formula in the first empty cell (below the formula is for normalizing the “Credit Score” column)
=(C2 – MIN($C$2:$C$101)) / (MAX($C$2:$C$101) – MIN($C$2:$C$101))

- Step 3: Drag the formula to all the rows

- Step 4: Do the same for all remaining numerical columns
Through this normalization, all the numerical columns range between 0 and 1.

-
Standardization
Similarly, standardization could also be performed just by swapping the min-max formula with the following
=(C2 – AVERAGE($C$2:$C$101)) / STDEV($C$2:$C$101)
This will ensure that the numerical column(s) are standardized such that their mean is 0 and standard deviation is 1 (this is because the standardized values are the z-scores of the original values).
2) Encoding and Binning data
Data scientists often have to encode or bin data for better analysis. While encoding involves transforming categorical data into numerical data, binning is the opposite, as numerical data is converted into categorical data here. Fortunately, Excel has a wonderful formula known as IF() that can help us accomplish both tasks.
-
Encoding
For example, to encode the “Loan Status” column, we have followed these simple steps-
- Step 1: Create a new column “Loan Status Encoded”
- Step 2: Write a nested IF() formula (by providing conditions and their statements) in the first empty cell
=IF(L2=”Approved”,1,IF(L2=”Denied”,0,2))

- Step 3: Copy and paste the cell by dragging to all the rows

-
Binning
Similarly, you have to write a nested IF() condition for binning. Below, you bin the “Credit Score” column using the following criteria.
Poor: 300-579
Fair: 580-669
Good: 670-739
Excellent: 740-850
- Step 1: Create a new column “Credit Score Binned” column

- Step 2: Write the nested IF() formula using the above criteria in the first empty cell
=IF(C2<=579, “Poor”, IF(C2<=669, “Fair”, IF(C2<=739, “Good”, “Excellent”)))

- Step 3: Copy and paste the cell by dragging to all the rows

3) Splitting and Merging Columns
During data analysis, information must often be combined or pulled apart. Excel has several formulae and tools that allow you to split and merge columns.
-
Column Splitting
For example, you can use the Delimited tool if you need to split the customer name into first and last names.
- Step 1: Select the “Customer Name” column
- Step 2: Go to ‘Data’ Tab → ‘Text to Columns’

- Step 3: Choose ‘Delimited’ and click ‘Next’

- Step 4: Select the appropriate delimiters:
>You check the ‘Space’ delimiter as the first and last names in your data are restricted using a space
>Click ‘Next’

- Step 5: Choose Destination:
>Select where you want the split columns to appear (choose the adjacent columns; however, before doing so, you will create an empty column next to the “Customer Name” column)
>Click ‘Finish’

- Step 6: Rename the columns appropriately (change the original column name to “First Name” and the new ones to “Last Name”

-
Column Merging (Concatenating)
Suppose you need to create a complete address of the customers by combining the city and state information into a single column. This will require you to do the opposite of what you have done above. In Excel, you have a great formula known as CONCATENATE(). Refer to the steps below to understand how to use this.
- Step 1: Create a new column (we have named it “Full Address”)

- Step 2: Write a CONCATENATE() formula in the first cell to merge the first cell of the “City” and “State” columns and restrict it by a comma and a space
=CONCATENATE(J2, “, “, K2)

- Step 3: Drag the formula to all the cells.

As you can see, Excel is a competent tool for cleaning data. However, it has some drawbacks that you should be aware of.
Challenges of Cleaning Data in Excel
Despite its capabilities, Excel faces some significant challenges, which include-
- Difficulty with Large and Complex Datasets: Excel has limited rows and columns; therefore, it has a ‘hard time cleaning and managing large datasets
- Limited Automation: Data cleaning in Excel is a highly manual task, increasing the chances of human error and making automation difficult.
- Complicate Implementation: The formula and functions can often be confusing and cumbersome, making implementing common data-cleaning tasks inefficient.
- Collaboration Difficulties: Collaborating using Excel is difficult as it has limited integration and support with other tools.
Despite these challenges, data cleaning in Excel remains highly popular, and you can follow a few tips to enhance its effectiveness.
Additional Tips and Practices
Several ways can help you overcome the issues discussed above. These include-
- Break down large datasets into smaller ones to use Excel for big datasets.
- Use macros or PowerQuery to automate data cleaning in Excel.
- Breakdown formulas into smaller and multiple steps, allowing for easier implementation and debugging
- Use Microsoft OneDrive or SharePoint to enhance collaboration, track changes, and implement version control.
Conclusion
Despite being around for a while, Excel is still considered a great tool for data analysis and decision-making. Features like Data Validation, Conditional Formatting, and PivotTable make it handy for data exploration, cleaning, and preparation.
While there are some challenges in dealing with complex data and automation, users can overcome them using SharePoint and Macros. Ultimately, using Excel to clean and prepare data for analysis remains highly common, and it is still the go-to tool for anyone who deals with data.
FAQs
- What is data cleaning in Excel?
It is the process of using Excel to clean and prepare data for analysis. It includes detecting and correcting inconsistencies, errors, and inaccuracies in data using Excel’s various tools and functions.
- What are examples of data cleaning?
Common examples of data cleaning in Excel are-
- Duplicate removal
- Missing value imputation
- Outlier capping
- Type casting
- Correcting Data Format
- Data Encoding and Binning
- Data Splitting and Merging





