
Introduction
Data is growing at a tremendous speed, and this increase is nowhere going to lessen. Terabytes of data are produced on a daily basis from sources including social media, company’s data, financials, interactions by the users, businesses sensors, and electronic devices such as mobile phones and automobiles. These traits of Volume, Velocity, Veracity and Variety primarily constitute data as Big Data.
Big data analytics uses advanced tools and techniques to extract meaningful information and insights from big data. Big data architecture framework is the layout or map of how this data is received from the various sources, prepared for further ingestion, analyzed, and then eventually made available to the end-user.
In this article, we dive through what is Big Data Architecture framework, Big Data analytics architecture and application, big data architecture diagram, the big data analytics architecture technology used, the tools and techniques available for big data, and big data analytics architecture courses.
What is Big Data Architecture?
It is a comprehensive system of processing a vast amount of data. The Big data architecture framework lays out the blueprint of providing solutions and infrastructures to handle big data depending on an organization’s needs. It clearly defines the architecture components of big data analytics, layers to be used, and the flow of information. The reference point is ingesting, processing, storing, managing, accessing, and analyzing the data. A typical big data architecture framework looks like below, having the following big data architecture layers:
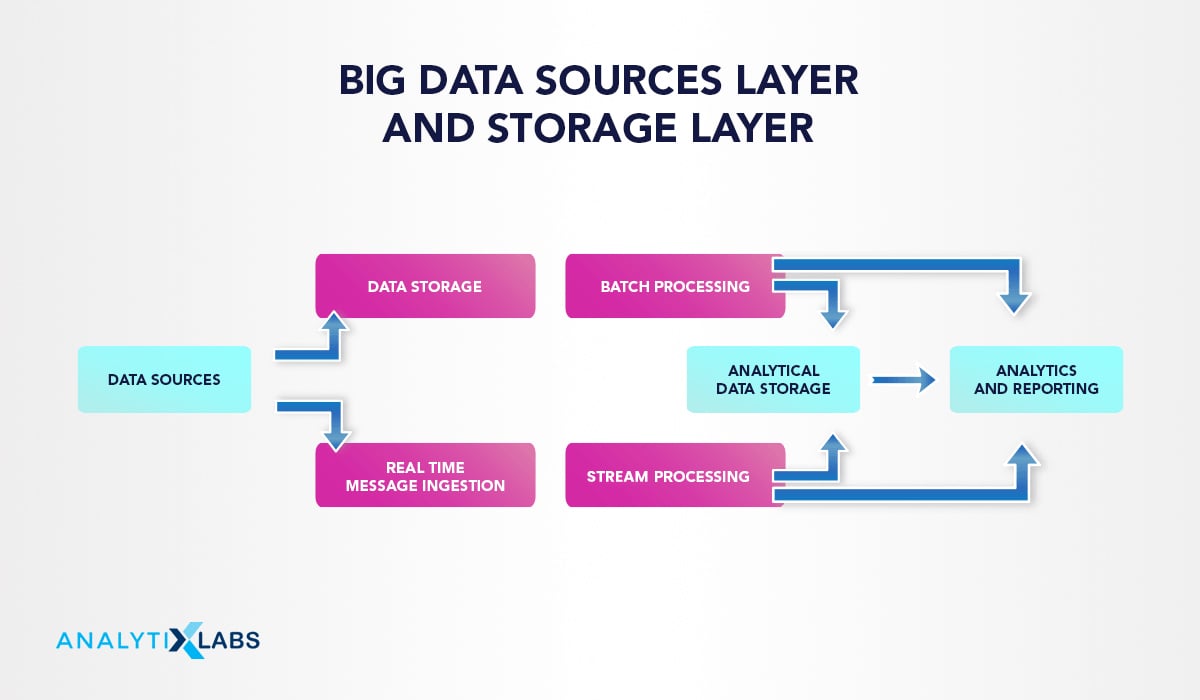
Big Data Sources Layer
The architecture of big data heavily depends on the type of data and its sources. The data sources are both open and third-party data providers. Several data sources range from relational database management systems, data warehouses, cloud-based data warehouses, SaaS applications, real-time data from the company servers and sensors such as IoT devices, third-party data providers, and also static files such as Windows logs. The data managed can be both batch processing and real-time processing (more on this below).
Storage Layer
The storage layer is the second layer in the architecture of big data receiving the data for the big data. It provides infrastructure for storing past data, converts it into the required format, and stores it in that format. For instance, the structured data is only stored in RDBMS and Hadoop Distributed File System (HDFS) to store the batch processing data. Typically, the information is stored in the data lake according to the system’s requirements.
Batch processing and real-time processing Layer
The architecture of big data needs to incorporate both types of data: batch (static) data and real-time or streaming data.
- Batch processing: It is needed to manage such data (in gigabytes) efficiently. In batch processing, the data is filtered, aggregated, processed, and prepared for analysis. The batches are long-running jobs. The way the batch process works is to read the data into the storage layer, process it, and write the outputs into new files. The solution for batch time processing is Hadoop.
- Real-Time Processing: It is required for capturing, storing, and processing the data on a real-time basis. Real-time processing first ingests the data and then uses that as a “publish-subscribe kind of a tool.”
Stream processing
Stream processing varies from real-time message ingestion. Stream processing handles all the window streaming data or even streams and writes the streamed data to the output area. The tools here are Apache Spark, Apache Flink, Storm.
Analytical datastore
The analytical data store is like a one-stop place for the prepared data. This data is either presented in an interactive database that offers the metadata or in a NoSQL data warehouse. The data set then prepared can be searched for by querying and used for analysis with tools such as Hive, Spark SQL, Hbase.
Analytics Layer
The analysis layer interacts with the storage layer to extract valuable insights and business intelligence. The architecture needs a mix of multiple data tools for handling the unstructured data and making the analysis. The tools and techniques for big data architecture framework are covered in a later section. On this subject, you may also like to read: Big Data Analytics – Key Aspects One Must Know
Consumption or Business Intelligence (BI) Layer
This layer is the output of the big data analytics architecture. It receives the final analysis from the analytics layer and presents and replicates it to the relevant output system. The results acquired are used for making decisions and for visualization. It is also referred to as the business intelligence (BI) layer.
AnalytixLabs, India’s top-ranked AI & Data Science Institute, is led by a team of IIM, IIT, ISB, and McKinsey alumni. The institute provides a wide range of data analytics courses, including detailed project work that helps an individual fit for the professional roles in AI, Data Science, and Big Data Engineering. With its decade of experience in providing meticulous, practical, and tailored learning, AnalytixLabs has proficiency in making aspirants “industry-ready” professionals.
You may also like to read about What is Big Data Engineering? Role, Skills, Job & Salary
Types of Big Data Architecture
Lambda Architecture Big Data
Lambda architecture is a hybrid approach that processes both batch (static) data and real-time processing data. It is employed for solving the problem of computing arbitrary functions. This deployment model approach aims to reduce latency and negligible errors while maintaining accuracy. The Lambda architecture big data is depicted like below:
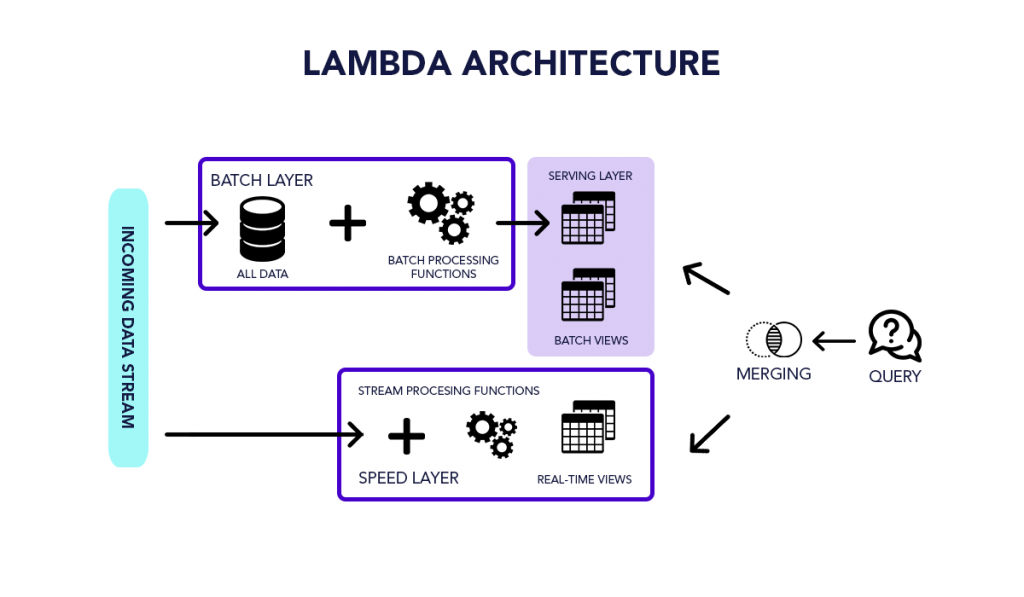
The layers in the lambda architecture big data are:
Batch Layer
It is the first layer in the lambda architecture big data that saves the incoming data in its entirety as batch views. The batch views are used to prepare the indexes. The data is immutable, meaning it cannot be changed, the source data remains identical, and only copies of the original data are created and stored. The batch layer ensures consistency by making the data append-only. There are two critical uses of the batch layer: first, handling the master dataset and then pre-computing the batch views.
Speed Layer
The speed layer manages the actual data that is not delivered directly to the batch layer, and it computes incremental functions on the new data. This layer too helps in reducing the latency and is not computationally loaded. The stream layer uses the processed data from the speed layer for correction.
Serving Layer
The batch views from the batch layer and the outcomes from the speed layer on a real-time basis traverses to the serving layer. This layer indexes the views for ensuring they can be queried by users and reducing delays by parallelization.
Kappa Architecture
An alternative to Lambda architecture big data is Kappa Architecture. The idea of this architecture is also to process both the real-time streaming and batch processing data. The Kappa architecture reduces the additional cost that comes up with the Lambda architecture big data by replacing the data sources medium with the message queuing.
Based upon the streaming architecture, a sequence of data is saved in the messaging engines, which further reads the data and converts it into the required format. Finally, it is saved for the end-user in the analytical database.
The real-time data is taken from the messaging engine and read and transformed, making the information readily available for the end-users. The architecture also creates more outputs by supporting the past saved data by taking in the batch way.
Additionally, the batch layer was removed in the Kappa architecture, and the speed layer was improved to provide reprocessing capabilities. The key difference with the Kappa Architecture of Big Data is that all the data is seen as a series or stream. The architecture uses the stream processing engine as the primary engine for data transformation, and the data is saved in the data lake. The Kappa big data architecture diagram looks like this:
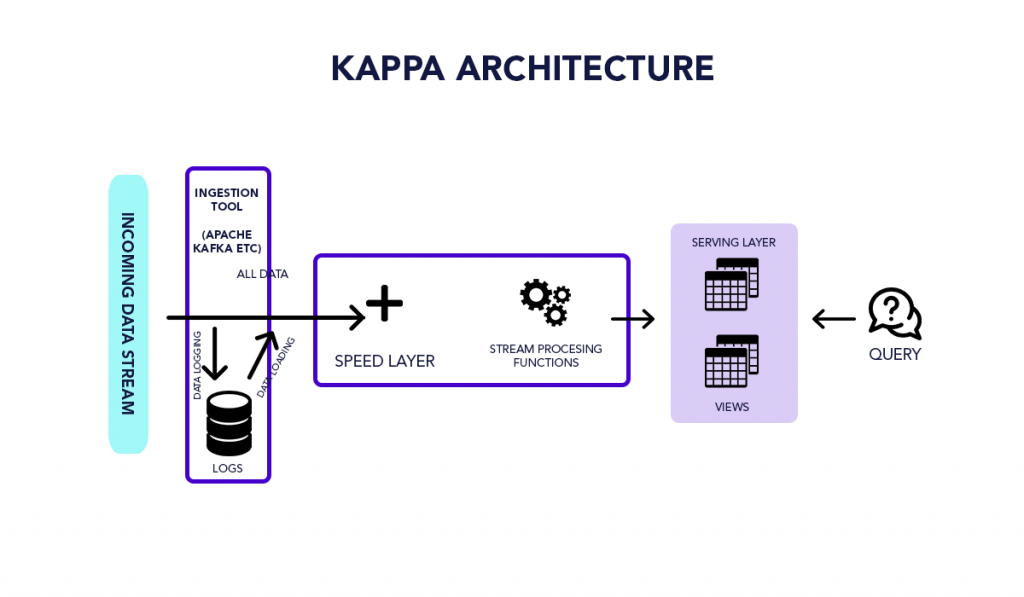
Big Data Tools and Techniques
Big data tools are categorized into four buckets according to their utility:
- Massively Parallel Processing (MPP)
- No-SQL Databases
- Distributed Storage and Processing Tools
- Cloud Computing Tools
- Massively Parallel Processing (MPP)
Massively Parallel Processing (MPP) is a storage construct with the purpose of managing the coordinated computations parallelly. An MPP system is also referred to as a “loosely coupled” or “shared nothing” system. The processing task is undertaken by breaking a large number of computer processors into separate pieces, and each of these pieces are processed simultaneously.
There can be up to 200 or more processors working on applications interconnected on this high-speed network. Each of the processors handles different sequences of the programs, has separate operating systems, and does not share memory. Also, these processors are communicated via a messaging system that allows MPP to send messages between the processes.
The databases based on MPP are IBM Netezza, Oracle Exadata, Teradata, SAP HANA, EMC Greenplum.
2. No-SQL Databases
Not only SQL (or No-SQL) is a non-structured query language. It is used to store unstructured data and provides structures for heterogeneous data in the same domain. It is a schema-less non-tabular database storing data differently than relational databases. The NoSQL databases offer flexibility scalability with storing and handling large amounts of data. It also provides availability as is one type of distributed database making data available remotely or locally.
The types of NoSQL databases are:
- Key-value Pair Based
- Graphs based
- Column-oriented Graph
- Document-oriented
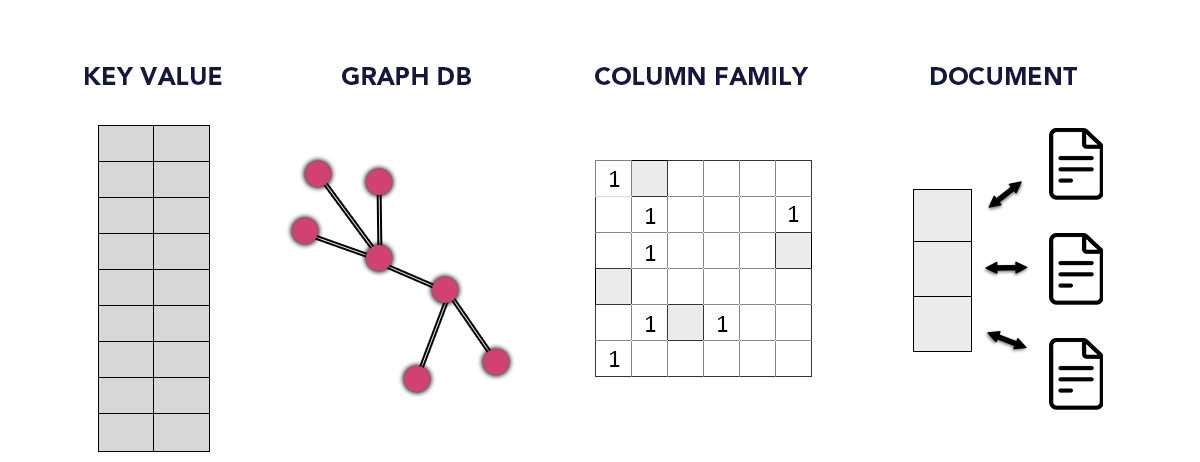
Key-value model:
This commonly used NoSQL database stores information in a hash table that is widely applied in dictionaries, collections, and associative arrays. It helps storage of the data without a schema. This stores data in a key-value pair. The key is unique and used for retrieval and updating of the data, and the value stored is a string, char, JSON, BLOB(Binary Large Objects)
The key-value store databases are Redis, Dynamo, Riak.
Graph-based model:
A graph database is multi-relational that stores both the entities and the relationships between those entities. This entity relationship is modeled using the nodes and edges, and the entities are stored as nodes, and the edges represent the relationships between those nodes (or entities). Graph-based models are used for mapping, logistics, social networks, and spatial data. These are also used to discover the patterns in semi-structured and unstructured data. The graph-based databases are Neo4J, FlockDB, Infinite Graph, OrientDB.
Column-based NoSQL database:
Based on the BigTable paper by Google, this database works on the columns. It is different from the relational database in the sense that the tables are a set of columns, and each column is independent and is considered separately. The values in the database are stored in a contiguous manner, and every column may not even contain a value. Since the data is available easily in a column, columnar perform well on the aggregation queries such as SUM, COUNT, AVG, MIN, MAX.
This column-family is also known as the Wide-column or Columnar or Column Stores. These are used for handling data warehouses, business intelligence, Customer Relationship Management (CRM), catalogs of library cards.
The NoSQL databases that use columnar are Cassandra, HBase, Hypertable.
Document-Oriented NoSQL database:
The purpose of the document-oriented database is to store in the form of documents where each is structured, and data is stored in the key-value pair and the format of JSON or XML. These are applicable for e-commerce applications, blogging platforms, real-time analytics, Content Management systems (CMS).
The document-oriented NoSQL databases are MongoDB, Couch DB, Amazon SimpleDB, Riak, Lotus Notes.
3. Distributed Storage and Processing Tools
A distributed database is an infrastructure that has data centers having their own processing units. A common distributed database management system handles this collection of data storage chunks. It can be physically located in the exact location or spread over an interconnected network of computers. The distributed databases are homogeneous (having the same software and hardware across all the instances) and heterogeneous, supported by different hardware.
The top big data processing and distribution tools are Hadoop HDFS, Snowflake, Qubole, Apache Spark, Azure HDInsight, Azure Data Lake, Amazon EMR, Google BigQuery, Google Cloud Dataflow, MS SQL.
Some of the standard tools of distributed databases:
- Hadoop is an Apache open-source software solution to work with big data. It is used to store, process, and analyze big data and especially provide the needed loading processing tools to process the vast amount of data.
- MapReduce is a parallel programming model for efficiently processing and refining the large data into smaller sets by performing functions of compilation and organization of the data sets.
- Spark, another open-source project from the Apache foundation is to fasten the computational computing software process of Hadoop.
4. Cloud Computing Tools
Cloud Computing Tools is a term that describes network-based computing, which includes Internet-based development and services. It has a shared pool of configurable computing resources, which are on-demand network access having access from anywhere and any place and any time. These services are available for pay-for-use as and when needed and are provisioned by the service provider. The platform is very useful in handling big data.
The most common cloud computing tools are Amazon Web Services (AWS), Microsoft Azure, Google Cloud, Blob Storage, DataBricks. Oracle, IBM, and Alibaba.
For more on big data tools and in-depth features of each tool, refer to the 16 Top Big Data Analytics Tools You Should Know About and refer here for the big data architecture courses.
Big Data Architecture Application
The big data architecture technology uses and big data architecture and application are:
- Cleansing of the sensitive data: The big data architecture allows to remove the sensitive data right at the beginning given its ingestion workflow and does not save in the data lake.
- Partitioning of the data: Big data architecture ingests data both in the batch and real-time. The batch processing has a frequency and recurring schedule. The ingestion process and the job scheduling for the batch data are simplified as the data files can be partitioned. The tools including Hive, U-SQL, or SQL queries improve the query performance by partitioning the tables.
- Leverages parallelism and reduces job time: Another application is to disperse the workload across the processing units. The static batch files are created and saved in formats that can be split further. The Hadoop Distributed File System (HDFS) can cluster hundreds of nodes and can parallelly process the files, eventually decreasing the job times.
FAQs- Frequently Asked Questions
Q1. What are the main big data components?
Ans. The eight main big data components are:
- Volume
- Velocity
- Value
- Variety
- Veracity
- Validity
- Volatility
- Visualization
Q2. What is the structure of big data?
Ans. Big data is categorized into three ways:
- Structured data
- Unstructured data
- Semi-Structured data
For more details, please check-out: Characteristics of Big Data | A complete guide
Q3. What are the sources of big structured data?
Ans. Some of the sources for structured data are:
- Excel spreadsheets
- SQL Databases
- OLTP Systems
- Sensors such as GPS or RFID tags
- Network and Web server logs
- Medical devices
Q4. What are the architecture components of big data analytics?
Ans. The components of big data architecture framework are:
- Data sources
- Data storage
- Batch processing
- Message ingestion
- Stream processing
- Analytical datastore
- Analysis and reporting
Q5. What are the different types of big data architecture layers?
Ans. The different big data architecture layers are:
- Big Data Sources Layer
- Management & Storage Layer
- Analysis Layer
- Consumption or Business Intelligence (BI) Layer
You may also like to read:
1. In simple terms, what exactly is Big Data in Artificial Intelligence
2. Big Data Job Opportunities and Trends | Career in Big Data





