
The accumulation of data has increased rapidly in recent times. The development in internet availability, computer hardware advancements, and data science are the prime reasons behind this growth.
Today, companies use techniques like data minig to identify patterns in data, identify irregularities, establish linkages, etc. By performing all these operations under data mining, a business can better understand the environment around them and make better decisions.
More on Data Mining: Top 11 Powerful Data Mining Techniques To Learn in 2024
This article will focus on the Apriori algorithm, a pivotal and widely employed data mining algorithm. Delve into the details below to discover what the Apriori algorithm entails, explore different aspects such as its definition, functionality, merits, drawbacks, and applications, and gain a comprehensive understanding of the Apriori algorithm in data mining through examples.
What is the Apriori Algorithm?
Before discussing the Apriori Algorithm, let’s first start with its origin. R. Agarwal and R. Srikantto are the creators of The Apriori algorithm. They created it in 1994 by identifying the most frequent themes through Boolean association rules. The algorithm has found great use in performing Market Basket Analysis, allowing businesses to sell their products more effectively.
The use of this algorithm is not just for market basket analysis. Various fields, like healthcare, education, etc, also use it. Its widespread use is primarily due to its simple yet effective implementation, as it utilizes the knowledge of previous common itemset features. The Apriori algorithm greatly helps to increase the effectiveness of level-wise production of frequent itemsets.
To understand the workings of the Apriori algorithm in data mining, you first need to explore the various concepts such as itemsets, association rules, association rule mining, etc, which we will discuss below.
-
Itemset
Iteset refers to a set of items combined. We can refer to an item as a k-itemset because it has a k number of unique items. Typically, an itemset contains at least two items.
-
Frequent Itemset
The next important concept is frequent itemset. A frequent itemset refers to an itemset that occurs most frequently. For example, a frequent itemset can be of {bread, butter}, {chips, cold drink}, {laptop, antivirus software} etc.
Now, the next issue is how to define a frequent itemset. To understand this, we determine a threshold value for certain metrics like Support and Confidence. While we will delve into a detailed discussion of support and confidence later in this article, let’s also address them precisely here.
Support is a metric that indicates transactions with products or items purchased together (in a single transaction). Confidence indicates those transactions where the products/items are purchased one after the other.
Mining frequent itemsets is the process of identifying them, and this involves using specific thresholds for Support and Confidence to define the frequent itemsets. The issue, however, is finding the correct threshold values for these metrics.
-
Association Rule Mining
To further explain the Apriori Algorithm, we need to understand Association Rule Mining. The Apriori algorithm works by finding relationships among numerous items in a dataset. The method known as association rule mining makes this discovery.
For example, in a supermarket, a pattern emerges where people buy certain items together. Let’s assume that individuals might buy cold drinks and chips together to make the example more concrete. Similarly, it’s also found that customers also put notebooks and pens together in a purchase.
Through association rule mining, you, as a supermarket owner, can leverage identified relationships to boost sales. Strategies like packaging associated products together, placing them in close proximity, offering group discounts, and optimizing inventory management can lead to increased profits.
Association rule mining is complex in practice, involving thousands of items with numerous potential relationships. The challenge lies in sifting through this complexity to identify meaningful business connections, as not all relationships are relevant. Without proper techniques, the process can be akin to finding a needle in a haystack.
-
Use of Apriori Algorithm for Association Rule Mining
Implementing the Apriori algorithm performs the task of association rule mining, carefully examining the data to discover patterns. Let’s continue the above example.
There can be thousands of products that a supermarket might be selling at any given point in time. As they record the transactions, i.e., the products sold to customers, association mining is possible on such transaction data. A general association rule mining algorithm finds all possible associations, i.e., combinations of all the products in transaction data. Then, it loops these combinations through every transaction to find the association rules.
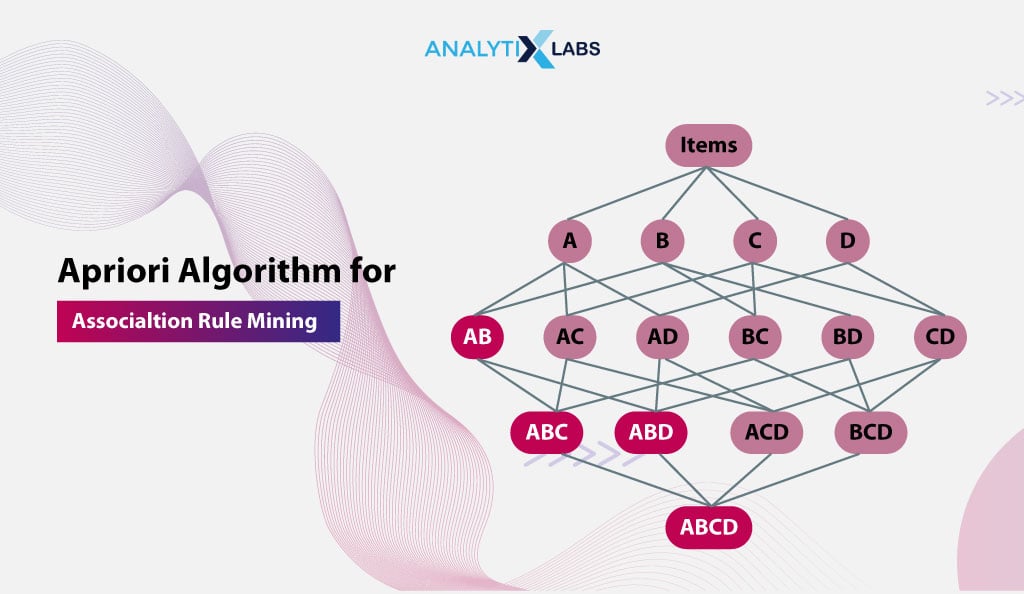
To put what I said in context, let’s say a supermarket sells four products – A, B, C, and D. This would mean that there can be 11 ways one can buy a combination of these products.
- A, B
- A, C
- A, D
- B, C
- B,D
- C, D
- A, B, C
- B, C, D
- A, C, D
- A,B,D
- A,B,C,D
In association rule mining, the Apriori algorithm efficiently discovers item combinations by iteratively looping through transactions, initially counting occurrences to identify large 1-itemsets. This approach avoids the inefficiency of calculating all possible combinations in a single iteration, especially with numerous items.
The 1-itemsets in our example (where you were dealing with four items – A, B, C, and D) would be {A}, {B}, {C}, {D}. A certain threshold is then identified, and if it is found that the count of occurrences of these products is less than the pre-determined threshold, then that particular product is discarded from all the plausible combinations. This dramatically reduces the total number of combinations, making the process faster.
To properly answer what the Apriori algorithm is, you first need to explore the important metrics calculated during its working.
Key Metrics for Apriori Algorithm
As discussed above, the number of possible associations can be in the thousands, especially if the number of items is large. The question is now how to identify the associations that are better than the others. This is where key metrics of the Apriori algorithm come into play.
When implementing the Apriori algorithm, we calculate three key metrics—Support, Confidence, and Lift—to identify the best associations. Each of these parameters can be regarded as an Apriori property. They are computed for various associations and then compared against a predetermined threshold. Let’s discuss these parameters in detail.
-
Support
Support indicates an item’s popularity, calculated by counting the transactions where that particular item was present. For item ‘Z,’ its Support would be the number of times the item was purchased, as the transaction data indicates.
Sometimes, this count is divided by the total number of transactions to make the number easily representable. Let’s understand Support with an example. Suppose there is transaction data for a day having 1,000 transactions.
The items you are interested in are apples, oranges, and apples+oranges (a combination item). Now, you count the transactions where these items were bought and find that the count for apples, oranges, and apples+oranges is 200, 150, and 100.
The formula for Support is-
Support (Z) = Transactions containing item Z / Total transactions
The Support, therefore, for the above-mentioned association would be
Support(Apple) = 200 / 1000 Support(Apple) = 0.20
Support(Orange) = 150 / 1000 Support(Orange) = 0.15
Support(Apple+Orange) = 100 / 1000 = 0.10 Support(Apple+Orange) = 0.10
In the Apriori algorithm, such a metric is used to calculate the “support” for different items and itemsets to establish that the frequency of the itemsets is enough to be considered for generating candidate itemsets for the next iteration. Here, the support threshold plays a crucial role as it’s used to define items/itemsets that are not frequent enough.
-
Confidence
Another Apriori property is Confidence. This key metric is used in the Apriori algorithm to indicate the probability of an item ‘Y’ being purchased if a customer has bought an item ‘Z’. If you notice, here, conditional probability is getting calculated, i.e., in this case, it’s the conditional probability that item Z appears in a transaction, given that another item Y appears in the same transaction. Therefore, the formula for calculating Confidence is
P(Z|Y) = P(Y and Z) / P(Y)
It can also be written as
Support(Y ∪ Z) / Support(Y)
Confidence is typically denoted by
(Y → Z)
In the above example, apples and oranges were bought together in 100 transactions, while apples were bought in 200 transactions. In such a case, the Confidence (Apples → Oranges) would be
Confidence (Apples → Oranges) = Transaction containing both Apples and Oranges / Transaction only containing Apples
Confidence (Apples → Oranges) = 100 / 200
Confidence (Apples → Oranges) = 0.5
The value of Confidence can be interpreted by using a pre-determined threshold value. If the value of Confidence is beyond the pre-determined threshold value, then it indicates Z is more likely to be purchased with item Y.
In the above example, a value of Confidence = 0.5 means that the association between “apple” and “orange” is 0.5, which means that when a customer buys “apple”, there is a 50% chance that they will also buy “orange”.
This information can be useful in recommending products to customers or product placement optimization in a store. If, for example, your pre-determined threshold value is 0.3 then this association can be considered.
-
Lift
After calculating metrics such as Support and Confidence, you can reduce the number of associations by selecting a threshold value for these metrics, considering associations beyond the set threshold.
However, even after applying thresholds for such metrics, there still can be a huge number of associations that require further filtering. Here, another metric known as Lift can be helpful. Lift denotes the strength of an association rule. Suppose you need to calculate the Lift(Y → Z); then you can do so by dividing Confidence(Y → Z) by Support(Z), i.e.,
Lift(Y 🡪 Z) = Confidence(Y 🡪 Z) / Support(Z)
Another way of calculating Lift is by considering Support of (Y, Z) and dividing by Support(Y)*Support(Z), i.e., it’s the ratio of Support of two items occurring together to the Support of the individual items multiplied together.
In the above example, the Lift for Apples 🡪 Oranges would be the following-
Lift(Apple 🡪 Orange) = Confidence(Apple 🡪 Orange) / Support(Orange)
Lift(Apple 🡪 Orange) = 0.5 / 0.15
Lift(Apple 🡪 Orange) = 33.33
Support(Y) and Support(Z) in the denominator indicate the independent occurrence of Y and Z in transactions. A high value in the denominator of Lift indicates that there is no such association rule as the purchase happens because of randomness. Therefore, Lift helps you to identify the association rule to consider.
A Lift value of 1 generally indicates randomness, suggesting independent items, and the association rule can be disregarded. A value above 1 signifies a positive association, indicating that two items will likely be purchased together. Conversely, a value below 1 indicates a negative association, suggesting that the two items are more likely to be purchased separately.
Now, with a grasp of the Apriori algorithm’s fundamental concepts and key metrics, let’s delve into understanding this algorithm’s role in data mining.
What is the Apriori Algorithm in Data Mining?
As you would have noticed by now, the Apriori algorithm is perfect for performing tasks such as market basket analysis. The Apriori algorithm in data mining can help data analysts understand the underlying patterns in their data and help businesses handle their customers better. This section discusses how the Apriori algorithm works when mining data.
Apriori algorithm Steps in Data Mining
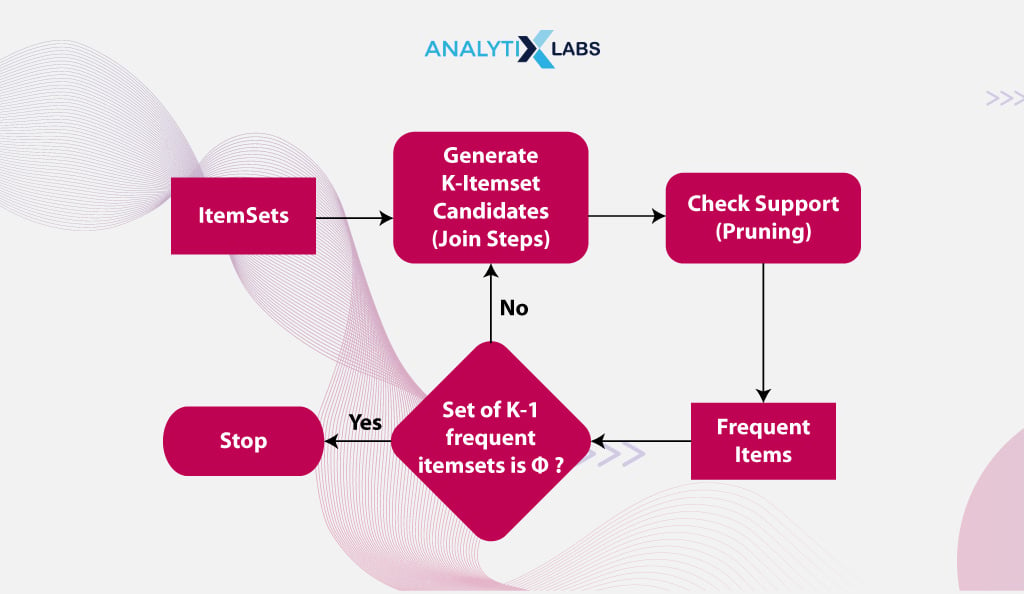
Typically, Apriori algorithm steps in data mining are the following-
-
Define minimum threshold
The first step is to decide on the threshold value for the support metric. The metric determining the minimum number of times an item should appear in the data to be considered significant is “Support.” The support value is based on data size, domain knowledge, or other considerations.
-
Create a list of frequent items
After determining the support threshold, the subsequent step involves scanning the entire dataset to identify items that meet the support threshold. The selected itemsets, meeting the support threshold, are called frequent itemsets.
-
Create candidate item sets
The next step is to use the previously identified frequent k-item sets and generate a list of candidate item sets. The length of these candidate itemsets is k+1.
-
Calculate the Support of each candidate
The algorithm needs to scan the dataset again and count the frequency of every candidate item, i.e., the number of times each item appeared in the data.
-
Prune the candidate item sets
The minimum threshold is again used to remove itemsets that fail to meet the minimum support threshold.
-
Iterate
This can be considered the most crucial stage of the Apriori algorithm. Steps 3 – 5 are repeated until no frequent itemsets can be generated.
-
Generate Association Rules
The algorithm now generates the association rules using the final frequent item sets identified at the end of the previous step.
-
Evaluate Association Rules
Metrics such as Confidence and Lift can be employed to filter the relevant association rules. At the end of this step, you get association rules that indicate the probability of a customer purchasing an item Z if they have already purchased an item Y (here, Y and Z are itemsets).
To better understand all the Apriori algorithm steps in data mining mentioned above, I will explain the Apriori algorithm with example transaction data and create association rules.
Understanding Apriori Algorithm with an example

Let me now explain the apriori algorithm with an example. Suppose you are dealing with the following transaction data.
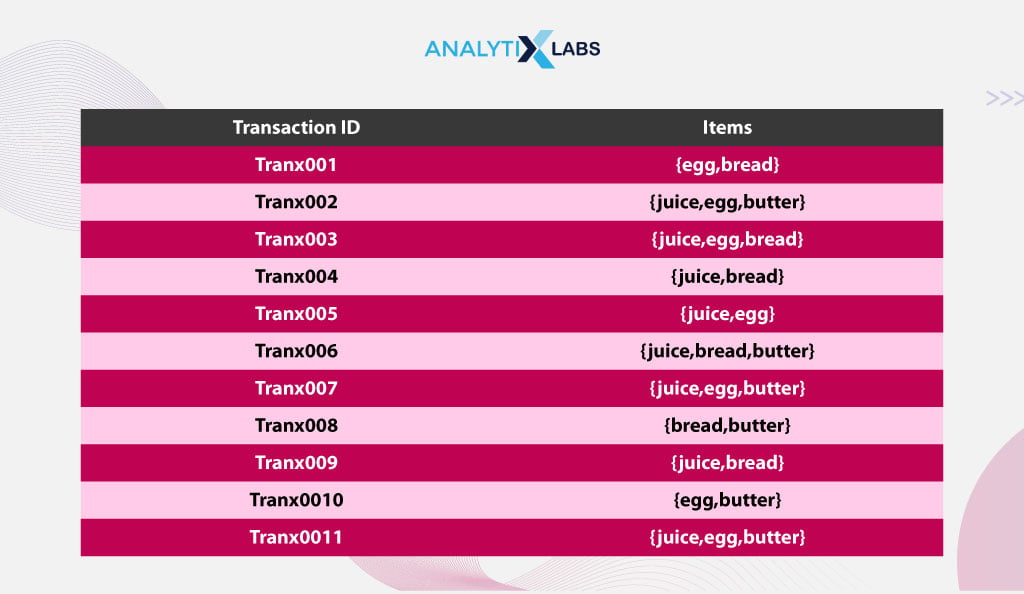
Step 1: Deciding Threshold
In this example, the threshold value of Support is considered as 3. Therefore, an item must appear in at least three transactions to be considered frequent.
Step 2: Computing Support
The frequency for each unique item in the data is calculated, i.e., the Support for 1-itemsets.

As all the 1-itemsets support is more than the support threshold of 3, they can be classified as frequent 1-itemsets and used to generate the candidates for 2-itemsets.
Step 3: Forming Candidate Itemsets
The above frequent 1-itemsets are considered to generate the candidate 2-itemset. Here, the combinations for all the above-identified frequent products are calculated such that each combination consists of two items. For the items bread, butter, egg, and juice, the 2-itemsets are
- {bread, butter}
- {egg, bread}
- {egg, butter}
- {juice, bread}
- {juice, butter}
- {juice, egg}
Step 4: Finding Frequent Combinations
The transaction data is scanned for the above combinations, and their support value is calculated, as seen below.
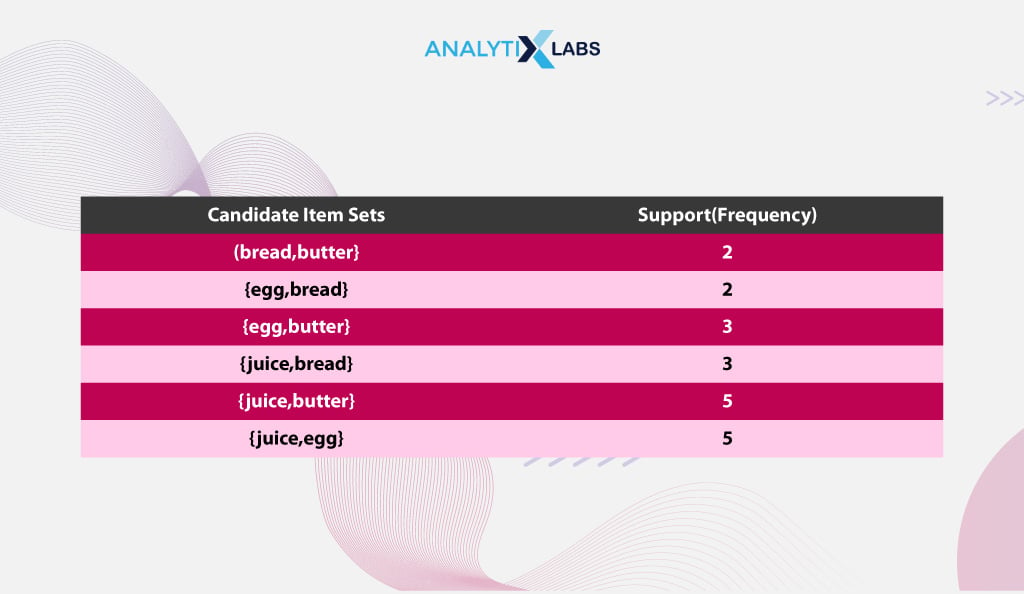
According to the above data, juice and egg were purchased together in five transactions, whereas egg and bread were bought together in only two transactions. Now, if you go by the support threshold value of 3, then the frequent 2-itemsets would be the following-
- {egg, butter}
- {juice, bread}
- {juice, butter}
- {juice, egg}
These frequent 2-itemsets can now be used to generate candidates for 3-itemset, and they would be
- {juice, bread, butter}
- {juice, egg, bread}
- {juice, egg, butter}
The support value for the above itemsets would be as follows-

As you would have noticed, of the 3-itemsets, only one can be considered frequent as only {juice, egg, butter} itemset has the support value of 3 or above. Now, as only one itemset remains, a candidate for 4-itemsets cannot be generated, leading us to terminate the process of finding the frequent itemsets. Therefore, the association rules can now be generated.
Step 5: Forming Association Rules
The main purpose of explaining the Apriori algorithm with example in data mining was to show you how one can come up with association rules. In our example, for the items egg, butter, and juice, the following association rules can be generated
- {egg, butter} 🡪 {juice}
- {juice, butter} 🡪 {egg}
- {juice, egg} 🡪 {butter}
Step 6: Calculating other metrics
For this example, I am using the confidence metric to define the utility of my association rules.
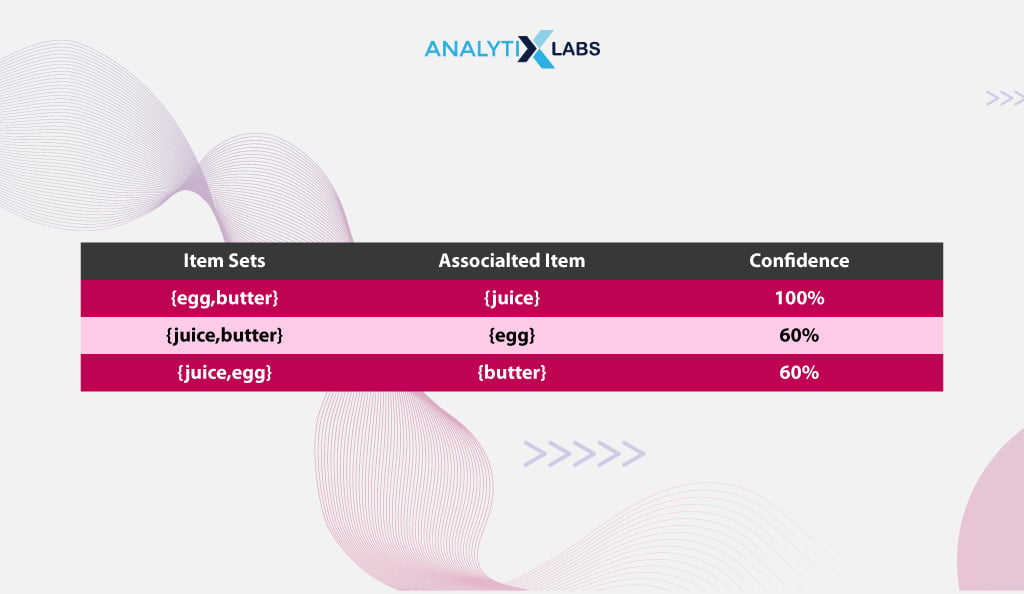
If you consider a confidence threshold of 0.7, i.e., 70%, then of all the associations mentioned above rules, the one that you can use to recommend products to the customer or optimize product placement would be {egg, butter} 🡪 {juice} as here you find a high value of Confidence that if a customer buys egg and butter, they are highly likely to purchase juice also.
So far, the discussion around the Apriori algorithm has been in terms of data mining and particularly market basket analysis. Machine learning and big data analytics fields also use this algorithm. Let’s also look at how Apriori Algorithm in big data analytics and machine learning work.
Apriori algorithm in Machine Learning and Big Data Analytics
Machine Learning often aims to solve complex problems. While traditional algorithms have been able to solve supervised learning problems, innovation in algorithms is particularly required when solving unsupervised problems such as clustering. The Apriori algorithm in machine learning has been used as a clustering algorithm.
For example, the Apriori algorithm in machine learning allows machine learning engineers to analyze large amounts of data and find complex patterns and associations in an unsupervised learning setup.
The Apriori algorithm finds application in big data scenarios, supported by languages like Spark and Python that provide libraries for its implementation. Despite its utility, the algorithm’s efficiency for big data remains a challenge, showcasing limited improvements over time. Next we have the various methods to improve the efficiency of the Apriori algorithm.
Also read:
As ML and DL are the base of AI, expertise in them is the need of the hour. Before going forward, you can check out our exclusive courses on Deep Learning with Python learning module and machine learning certification course, or book a demo with us.
Explore our signature Data Science and Analytics courses that cover the most important industry-relevant tools and prepare you for real-time challenges. Enroll and take a step towards transforming your career today.
Methods to Improve Apriori Efficiency

There are multiple ways through which the efficiency of the aprio algorithm can be elevated. Some of the most prominent ways of making this algorithm efficient are the following-
-
Hash-Based Technique
It’s a technique that uses a hash-based structure known as a hashtable. A hash function generates the table, producing the k-itemsets and their respective counts.
-
Transaction Reduction
One way to make the Apriori algorithm efficient is by reducing the number of transactions it has to scan. Marking transactions as containing less frequent items or removing them altogether accomplishes this.
-
Partitioning
The iterative scanning of the dataset in the Apriori algorithm is the primary reason it is inefficient. Therefore, reducing the number of scans is one way of making it efficient. The partitioning method only necessitates database scans for identifying the frequent itemsets.
In this approach, an itemset is deemed potentially frequent if it is identified as frequent in at least one part of the database.
-
Sampling
Sampling is always a great way to increase the efficiency of any process. For the Apriori algorithm, sampling can be used where a random sample ‘S’ from a dataset ‘D’ can be considered.
The scan to find the frequent item is then done on S. The issue here might be that the algorithm might fail to find the global frequent itemset, but it’s a trade-off to increase efficiency. This trade-off can be managed by tuning the value of parameters like ‘min_sup’.
Also read : What is Sampling Technique in Statistics
-
Dimensionality Reduction
Another way to reduce data is by performing data dimensionality reduction using techniques such as Principal Component Analysis (PCA) or Singular Value Decomposition (SVD). This helps reduce noise, redundant features, etc., helping in increasing the algorithm’s efficiency.
Also read: Factor Analysis Vs. PCA (Principal Component Analysis)
-
Dynamic Itemset counting
Another technique that can greatly enhance the efficiency of the Apriori algorithm is the dynamic itemset technique. Here, new candidate items are added at any marked starting point of the dataset when the dataset is being scanned.
-
Parallel Computation
One way to make the Apriori algorithm more efficient is by working on a distributed system or using multi-core processes. This can allow the processing of multiple itemsets in parallel, helping the algorithm’s performance.
-
Variations of the Apriori algorithm
One may ask you which algorithm requires fewer scans of data. The answer to that would be that one can use other variants of the Apriori algorithm, such as the FP-Growth algorithm or the Eclat algorithm. These modified Apriori algorithms can provide better performance depending on the data and the business requirements you are dealing with.
Let’s now look at the various advantages and disadvantages of the Apriori algorithm.
Advantages of Apriori
The following are the most important advantages of the Apriori algorithm for data mining.
-
Simplicity and Ease of Implementation
The biggest advantage of the Apriori algorithm in data mining is that it’s a highly intuitive algorithm. The fact that it is easy to implement and understand makes it accessible even to those who may not have a deep understanding of data mining, data analytics, machine learning, etc.
-
Efficient Pruning
Rather than considering all the possible association rules, the Apriori algorithm works relatively efficiently by performing pruning. By narrowing down the number of plausible items to explore, it reduces the calculations required, thereby accelerating the overall process.
-
Scalability
The Apriori algorithm can easily work with large datasets. It’s highly scalable as it can run on distributed systems, making it a favored algorithm for data mining for large-scale operations.
-
Unsupervised
The algorithm doesn’t require labeled data. This makes it a great algorithm for working in an unsupervised learning setup. As data is not labeled more often than not, the usefulness of the Apriori algorithm only increases.
-
Support
The fact that it’s a highly popular algorithm helps the support that it gets. Almost all major data mining tools support this algorithm, and many users use it for association rule mining.
Apart from these advantages of the Apriori algorithm, there are a few major disadvantages that you should know about.
Disadvantages of Apriori
The following is the users’ most common difficulty when using the Apriori algorithm.
-
Computational Complexity
The biggest drawback of using the Apriori algorithm in data mining is that it is extremely computationally expensive. For example, a dataset containing 104 frequent 1-itemsets will generate 107 2-length candidates.
Hence, numerous calculations are necessary when computing Support, and this challenge becomes more pronounced when handling large datasets, extensive itemsets, or low support threshold values.
-
Multiple Scans of the dataset
The algorithm is time-consuming, requiring multiple full dataset scans to generate the frequent itemsets.
-
Numerous Rules
The Apriori algorithm can create many association roles, making reviewing and identifying the relevant ones difficult.
-
Susceptible to Data Sparsity
The Apriori algorithm doesn’t perform well if the data is sparse. Here, sparse refers to datasets with a low frequency of itemsets.
Despite all these advantages and disadvantages of the Apriori algorithm, it has found its use in several domains. Now, we will discuss a few applications of Apriori Algorithm.
Application of Apriori Algorithm
Multiple Apriori algorithm examples indicate its usefulness. Some of the most prominent application areas of the Apriori algorithm are the following-
-
Web Usage
Apriori Algorithm helps uncover web patterns, i.e., understand how users navigate a website. The algorithm’s information helps developers create and design user-friendly websites.
-
Medical
The Apriori algorithm helps identify drug combinations and patient factors associated with adverse drug reactions. It is also used for diagnosing diseases by looking at the symptoms that occur together.
-
Forestry
Implementing the Apriori algorithm on forest fire data allows for analyzing and estimating the frequency and intensity of forest fires.
-
Recommendation System
Many applications today perform auto completions when you are typing something on an application. Likewise, on streaming platforms such as Netflix, YouTube, and Spotify, content recommendations are provided to users. These all are outcomes of association rules provided by algorithms like Apriori.
-
Network Traffic Analysis
In cybersecurity, the Apriori algorithm becomes useful as it can monitor network traffic. The Apriori algorithm first establishes the frequent patterns of normal web traffic. This is then used to distinguish from any other behavior that can be unusual or which comes under cyber threat.
-
E-Commerce and Retail
The most quintessential Apriori algorithm example is its use in e-commerce. Most e-commerce and retail stores employ algorithms like the Apriori algorithm to analyze customers’ purchase patterns. This helps them bundle their products, optimize inventory, cross-sell products, etc.
Conclusion
The Apriori algorithm is a crucial tool in data mining, commonly used for frequent itemset mining and association rule learning. It proves particularly valuable in tasks like market basket analysis for creating recommendation systems, emphasizing interpretability. Despite its advantages, including flexibility and ease of use, it has notable limitations. Apriori can be computationally expensive and time-consuming, especially when handling noisy and sparse data.
FAQs
- What are the two steps in the Apriori algorithm?
The two steps in the Apriori algorithm are-
- Step 1: Create a frequency table and identify frequent itemsets by checking their support value against the threshold value.
- Step 2: Create association rules and filter the relevant rules.
- How do you use the Apriori algorithm?
You can use the Apriori algorithm by calculating three key metrics: Support, Confidence, and Lift. You can utilize widely-used languages and tools, including MS Excel, Python, R, etc., to execute the Apriori algorithm for data mining.
- What is the Apriori algorithm search?
Apriori algorithm search refers to the iterative scanning of the database to find the frequent itemsets. The algorithm employs the technique of frequent pattern mining (FPM) to identify the crucial patterns and hidden relationships between the items present in the dataset.





