
A month ago, India’s first driverless metro train in the national capital, Delhi, was launched. Driverless train in India? Yes! Like it or not, automation is happening and will continue to happen in places where you couldn’t have imagined before. Artificial Intelligence has swept away the world around us, leading to the natural progression of demand for skilled professionals in the job market. It is one field that will never go outdated and will continue to grow. Wondering how to leverage this opportunity? How can you prepare yourself for such a league of jobs that make the world go around? We have got a repository of ai viva questions to help you get ready for your next interview!
This article will cover the artificial intelligence interview questions and answers and help you with the much-needed tips and tricks to crack the interview. The article is divided into three types of artificial intelligence interview questions: basic artificial intelligence interview questions, intermediate level, and advanced AI viva questions.
AnalytixLabs is India’s top-ranked AI & Data Science Institute and is in its tenth year. Led by a team of IIM, IIT, ISB, and McKinsey alumni, the institute offers a range of data analytics courses with detailed project work that helps an individual fit for the professional roles in AI, Data Science, and Data Engineering. With its decade of experience in providing meticulous, practical, and tailored learning. AnalytixLabs has proficiency in making aspirants “industry-ready” professionals.
Basic Level AI Interview Questions and Answers
Some artificial intelligence interview questions and answers give the scope to form a broad answer, but it’s important to stay as concise as possible while answering. AI is a field where developments and updates are every day; hence, you must remember to go through a few while preparing for ai viva questions.
1. What do you understand by Artificial Intelligence? List some real-life applications of AI.
Artificial Intelligence is a branch of computer science wherein the human brain’s cognitive functions are studied and replicated on a machine or a system. The purpose of AI is to create intelligent machines that can mimic human behavior. It is needed to solve complex problems, automate routine work. Artificial Intelligence is extensively used in various industries, including science and technology, healthcare, telecommunications, energy.
Some of the AI applications are Google’s search engine, computer vision, speech recognition, decision-making, perception, reasoning, cognitive capabilities, classification of email as spam, detection of disease, virtual assistants such as Amazon’s Alexa, Echo, Google Home Speaker.
You may also like to read: 15 Real World Applications of Artificial Intelligence
2. What are the types of Artificial Intelligence?
Artificial intelligence can be divided into different types on the basis of capabilities and functionalities.
Based on Capabilities:
- Weak AI or Narrow AI or Artificial Narrow Intelligence (ANI): This type of AI is general AI, capable of performing some dedicated tasks with intelligence such as building virtual assistants. Examples: Siri, Alexa
- General AI or Artificial General Intelligence (AGI): Intelligent machines can perform any intellectual task efficiently as a human. This is also known as strong AI. Example: Pillo robot that answers artificial intelligence interview questions and answers pertaining to health.
- Artificial Superhuman Intelligence (ASI): This AI possesses the ability to do everything that a human can do and more. Example: Alpha 2, which is the first humanoid ASI robot.
Based on Functionalities:
- Reactive Machines: These are the basic types of AI. Based on present actions, one cannot use previous experiences to form current decisions and simultaneously update one memory. Example: Deep Blue.
- Limited Memory: It can store past data or experiences for a limited duration. They detect the movement of vehicles around them constantly and add it to their memory. This type of AI is used in self-driving cars.
- Theory of Mind: It is an advanced AI capable of understanding human emotions and people in the real world.
- Self-Awareness: This type of AI is the future of Artificial Intelligence that will possess human-like consciousness, emotions, and reactions. Such machines have the ability to form self-driven actions.
3. What is the difference between Strong AI and Weak AI?
| Strong AI | Weak AI |
| Strong AI is about creating real intelligence artificially, which means a human-made intelligence that has sentiments, self-awareness, and emotions similar to humans. | Weak AI is the current development stage of artificial intelligence that deals with creating intelligent agents and machines that can help humans and solve real-world complex problems. |
| It is a wider application with more vast scope. | It is a narrow application with limited scope. |
| The application has incredible human-level intelligence. | The application is good at specific tasks. |
| Strong AI uses association and clustering for this purpose. | Weak AI uses unsupervised and supervised learning for processing data. |
| Examples: Robotics | Examples: Apple’s Siri, Amazon’s Alexa |
4. What are the areas and domains where AI is used?
Artificial intelligence is used in many areas, some of which are:
- Speech recognition
- Facial recognition
- Chatbots or personal assistants
- Language detection and translation
- Self-driving cars
- Sentiment analysis
- Intent analysis
- Image processing
- Image tagging
- Search and Recommendation engines
- Game development
- Fraud detection
- Email classification
- Prediction of disease
- Forecasting sales
The most popular domains of AI are:
- Deep Learning
- Neural Networks
- Natural Language Processing
- Robotics
- Fuzzy Logic Systems
- Expert Systems
- Machine Learning
5. What are the tools of AI?
The tools of artificial intelligence are:
- Scikit Learn
- Keras
- TensorFlow
- PyTorch
- Theano
- Caffe
- MxNet
- Auto ML
- CNTK
- OpenNN
- H20: Open Source AI Platform
- Google ML Kit
6. What is the role of frameworks of Scikit-learn, Keras, TensorFlow, and PyTorch?
Scikit-learn is an open-source and standard library for Machine Learning. It is like one umbrella under which all the data preprocessing, feature selection, machine learning algorithms are included. It expands on the two most important libraries: NumPy and SciPy, where Numpy is used for scientific computing and data analysis and Scipy is used in statistical, mathematics, scientific, engineering, and technical computing.
Keras is an open-source library written in Python for artificial neural networks It is designed to enable fast experimentation with deep neural networks.
TensorFlow is an open-source software library with a focus on data flow and differential programming. It is used for machine learning applications.
PyTorch is an open source machine learning library based on the Torch library. It is used for applications such as computer visioning and natural language processing. It was primarily created by Facebook’s AI Research Lab.
Read the Ultimate Python Data Science Libraries to Learn to know the required libraries and frameworks.
7. Name some popular programming languages in AI.
Python is the most popular programming language for AI because of its modularity. Python offers open-source libraries such as Matplotlib, NumPy, Scikit-learn, and Tensorflow making the workflow efficient.. The other commonly used languages for AI are:
- R
- Lisp
- Prolog
- Java
- Julia
- Haskell
You may also like to read: Top 50 Python Interview Questions for Data Science
8. What is the difference between inductive, deductive, and abductive learning?
| Inductive Learning | Deductive Learning | Abductive Learning |
| The learning happens from a group of instances and draws its conclusions accordingly. | Here, first obtain the results, derive the conclusions and then it improves based on the past results or previous decisions. | The conclusions are derived according to different instances. |
| It uses K-nearest neighbors (KNN), Support Vector Machines (SVM), and statistical learning algorithms. | Machine learning algorithm using a decision tree. | It is based on deep neural networks. |
9. What is the difference between Statistical AI and Classical AI?
Statistical artificial intelligence focuses on inductive thought given a set of patterns or trends. On the other hand, classical artificial intelligence is based on deductive thought, using a set of constraints, deduce a conclusion.
10. Are AI and ML the same? If yes, how, and if not then why so?
No, Artificial intelligence and Machine Learning are not the same. Artificial Intelligence is a field of computer science concerned with building machines that are capable of thinking like humans and performing tasks that typically require human intelligence. AI is a rule-based if-else programming input approach that is static and hardcoded.
M is a subset of AI wherein the machines are not specifically or explicitly programmed to perform certain tasks but rather the machines learn by themselves and improve automatically through experience. In contrast to AI, ML is dynamic where the rules are not predefined and are not known beforehand.
You may also like to read: Top 45 Machine Learning Interview Questions and Answers
11. What is the difference between Artificial Intelligence, Machine Learning, and Deep Learning?
Artificial intelligence is the all-encompassing branch of computer science to build machines that are capable like humans. Example: Robotics
Machine learning is the subset of AI. It is the practice of getting machines to make decisions without being programmed. It aims to build machines learning through data so that they can solve problems. Example: churn prediction, detection of disease, text classification.
Deep Learning is the subset of Machine Learning. It has neural networks that can perform unsupervised learning from unstructured data. They learn through representation learning, and it could be unsupervised, supervised, or semi-supervised. Deep learning aims to build neural networks that automatically discover patterns for feature detection. Example: uncrewed cars and how they can recognize stop signs on the road.
For more details, please also read Data Science vs. Machine Learning vs. AI Deep Learning – What is the difference?
12. What is Machine Learning? What are the types of Machine Learning?
A subset of artificial intelligence, Machine learning is the study of algorithms and models, which computers use for performing specific tasks without having particular instructions. It is a framework that takes the past data and identifies the relationships among the features and machines can predict the new data with the help mathematical relationships by getting dynamic, accurate and stable models.
The types of Machine Learning are:
- Supervised Learning
- Semi-supervised Learning
- Unsupervised Learning
- Reinforcement Learning
13. What are the different algorithms used in Machine Learning?
The different algorithms in Machine Learning depend on the type of the algorithm: Supervised or Unsupervised Learning. Under supervised learning, the algorithms are:
- Linear Regression
- Logistic Regression
- Decision Trees
- K-Nearest Neighbors (KNN)
- Naive Bayes
- Support Vector Machines
- Ensemble Learning (Random Forest, Bagging, Boosting)
Except for Linear Regression that can be used for regression problems and Logistic Regression and Naive Bayes, which can be used only as classifiers. Rest all can be used for both regression and classification problems
Under unsupervised learning the algorithm are:
- K-means Clustering
- Agglomerative (Hierarchical) clustering
- Spectral Clustering (DBSCAN)
- Association Analysis (Market Basket Analysis)
- Principal Component Analysis
You may also want to read more about Different Types of Machine Learning Algorithms
14. What is Supervised vs. Unsupervised Learning?
In supervised learning, the algorithm learns on the labeled dataset, where the response is known. This acts as a ‘supervisor’ to train the model that provides an answer key that the algorithm can use to evaluate its accuracy on training data. This is used to predict the values for future or unseen data. Examples of Supervised learning are: predicting the sales price of products, how much loan to grant, churn prediction, predicting survivors from Titanic.
In unsupervised learning, the model infers the hidden structure, pattern on the unlabeled data. There is no response or the target variable present in such data to supervise the analysis of what is right or what is wrong. The machine tries to identify the pattern and gives the response. In the absence of the desired output, the data is categorized or segmented using clustering. The algorithm learns to differentiate correctly between a human’s face to the face of a horse or cat. Examples of unsupervised learning: customer segmentation, image segmentation, market basket analysis, delivery store optimization, identifying accident-prone areas.
15. Explain Reinforcement Learning. How does it work?
Reinforcement Learning, a type of Machine learning algorithm, which is based on the feedback loop where an agent and environment is set up.
The way it works is the agent learns to behave in an environment, by performing certain actions and observing the rewards and results which it gets from those actions. Hence This technique is behavior-driven and is based on the reinforcements learned via trial-and-error. Example: to learn how to ride a bicycle. This method can be used to optimize the operational productivity of systems including supply chain logistics, manufacturing, and robotics.
16. Differentiate between Text Mining and NLP.
| Differentiation | Text Mining | Natural Language Processing |
| What is it? | Text Mining is the discovery by computer of new, previously unknown information, by automatically extracting information from textual data (semi-structured and unstructured data). | Natural Language Processing (NLP) is the science of teaching machines how to understand the language we humans speak and write |
| How does it do? | Text mining can be done using text processing languages such as Perl, statistical models. | Using advanced machine learning models, deep neural networks |
| Outcome: | PatternsCorrelationsFrequency of words | Sentiment AnalysisSemantic meaning of text grammatical structure |
17. What is NLP, what are its applications and its components?
Natural Language Processing (NLP), a branch of data science and one of the principal areas of Artificial Intelligence, processes for analyzing, understanding, and deriving information from the text data in a smart and efficient manner.
Applications of NLP are: text classification, text summarization, automated chatbots, multilingual translation, entity detection, machine translation, question answering, sentiment analysis, intent analysis, speech recognition, and topic segmentation.
Natural Language Understanding includes:
- Mapping input to useful representations
- Analyzing different aspects of the language
Natural Language Generation includes:
- Text Planning
- Sentence Planning
- Text Realization
You may also like to read: Top Natural Language Processing (NLP) Interview Questions
18. What is the difference between Stemming and Lemmatization?
Stemming: Stemming is a rudimentary rule-based process of stripping the suffixes (“ing”, “ly”, “es”, “s” etc) from a word.
Lemmatization: Lemmatization, on the other hand, is an organized & step by step procedure of obtaining the root form of the word. It uses vocabulary (dictionary importance of words) and morphological analysis (word structure and grammar relations).
19. What is the difference between Information Extraction and Information Retrieval?
Information retrieval (IR): It is concerned with storing, searching, and retrieving information. It is a separate field within computer science (closer to databases), but IR relies on some NLP methods (stemming). Some current research and applications seek to bridge the gap between IR and NLP.
Information extraction (IE): It is concerned with the extraction of semantic information from text. This covers tasks such as named entity recognition (NER), coreference resolution, relationship extraction.
20. What is an Expert System?
An expert system, an Artificial Intelligence program, has expert-level knowledge about a specific area of data and utilizes the information to react appropriately. These systems tend to have the capability to substitute a human expert and solve real-life problems.
21. List the characteristics of the expert system.
The characteristics of an expert system include:
- High performance
- Adequate response time
- Reliability
- Understandability
- Consistency
- Memory
- Diligence
- Logic
- Multiple expertise
- Ability to reason
- Fast response
- Unbiased in nature
- Easy availability
- Low production costs
- Reduces the rate of errors
22. What are the components of the Expert system?
An expert system mainly contains three components:
- User Interface: It enables a user to interact or communicate with the expert system to find the solution for a problem.
- Inference Engine: It is called the main processing unit or brain of the expert system. It applies different inference rules to the knowledge base to draw a particular solution.
- Knowledge Base: The knowledge base is a type of storage area that stores the domain-specific and high-quality knowledge.
23. What is an agent in AI?
In reinforcement learning, a domain of artificial intelligence uses agents that senses or perceives the environment by sensors that allow them to understand the settings. The agents have specific goals, and can learn and use the knowledge to achieve the goals.

Intermediate Level AI Interview Questions and Answers
While talking about intermediate-level AI viva questions, the interviewer wants to see how you present your work experience while answering the artificial intelligence interview questions and answers.
24. Explain the term Q-Learning.
Q-learning is a popular reinforcement learning algorithm. In this, the agent tries to learn the optimal policies that can provide the best actions to maximize the environment’s rewards. The agent learns these optimal policies from past experiences.
25. What is a Turing Test?
A Turing Test allows checking the intelligence of a machine as compared to human intelligence. In this test, the computer challenges human intelligence, and only on passing the test is a machine considered intelligent.
26. What is the Tower of Hanoi?
Tower of Hanoi is a mathematical puzzle that shows how recursion is utilized to build an algorithm to solve a specific problem. In artificial intelligence, the Tower of Hanoi can be solved using a decision tree and a breadth-first search (BFS) algorithm.
27. What is the A* algorithm search method?
When you want to find the best route between two nodes, you will use an A* algorithm search. Its purpose is to traverse a graph or find a path for this purpose.
A* algorithm, based on the best first search method, is the algorithm used to find the paths or traversing graph. The purpose is to find the most optimal route between the nodes. It is extensively used in solving video games for pathfinding. A* is formulated with weighted graphs, and meaning can find the best route by the shortest distance and time, making the algorithm flexible and versatile.
28. What is the difference between breadth-first and depth-first search algorithms?
Both breadth-first search (BFS) and depth-first search (DFS) algorithms are used to search tree or graph data structures.
| Breadth-first search algorithm | Depth-first search algorithm |
| It is based on FIFO (first-in, first-out) method. | It is based on the LIFO (Last-in, Last Out) approach. |
| It starts from the root node, proceeds through neighboring nodes, and finally moves towards the next level of nodes. Till the arrangement is found and created, it produces one tree at any given moment | It starts at the root node and searches as far as possible along every branch before it performs backtracking. |
| The method strategy gives the shortest path to the solution. | The path is stored in each iteration from root to leaf nodes in a linear fashion with space requirements. |
Learn more about Data Types, Structures and Applications
29. Explain a bidirectional search algorithm. What is it?
In a bidirectional search algorithm, two searches are run simultaneously. The first search begins forward from the initial state, and the second goes backward in reverse from the goal state. Both the searches meet to identify a common state, and this way, the search ends. The initial state is linked with the goal state in a reverse manner.
30. How would you explain a uniform cost search algorithm?
In a uniform cost search algorithm, the search starts from the initial state and goes to the neighboring state to choose the ‘least costly’ state. It performs in increasing the cost of the path to a node and expands the least cost node. A breadth-first search algorithm will become a uniform cost search algorithm if it has the same cost in every iteration. It investigates ways in the expanding order of the cost.
31. What are iterative deepening depth-first search algorithms?
In iterative deepening DFS algorithms, the search process of levels 1 and 2 takes place. The search process continues until the solution is found. It generates nodes until it finds the goal node and saves the stack of nodes it had created.
32. What is fuzzy logic? List its applications.
A subset of AI, fuzzy logic is a way of encoding human learning for artificial processing. It is represented as IF-THEN rules and the digital values of YES and NO. It is based on degrees of truth.
Some of its important applications include:
- Facial pattern recognition
- Air conditioners, washing machines, and vacuum cleaners
- Anti Skid braking systems and transmission systems
- Control of subway systems and crewless helicopters
- Weather forecasting systems
- Project risk assessment
- Medical diagnosis and treatment plans
- Stock marketing prediction and trading
You may also like to read: Stock Market Prediction Using Machine Learning & AI Techniques
33. What is partial order planning?
In partial-order planning, the search takes place over the space of possible plans rather than searching over all the possible situations. The partial-order plan specifies all actions that need to be undertaken but specifies the actions only when required. The goal is to construct a planned piece by piece.
When a plan specifies all the actions you need to perform but specifies the order of the steps only when necessary, it’s called a partial-order plan.
34. What is FOPL?
First-Order Predicate Logic (FOPL) is a collection of formal systems, where each statement is divided into a subject and a predicate. The predicate refers to only one subject, and it can either modify or define the properties of the subject. It provides:
- A language to express assertions about certain “World”
- An inference system to deductive apparatus whereby we may draw conclusions from such assertion
- A semantic based on set theory
35. What does FOPL consist of?
FOPL consists of:
- A set of constant symbols
- A set of variables
- A set of predicate symbols
- A set of function symbols
- The logical connective
- The Universal Quantifier and Existential Quantifier
- A special binary relation of equality
36. Explain Hidden Markov Model.
The hidden Markov model (HMM) is a statistical model used to represent the probability distributions over a chain of observations. In the model, the hidden layer defines a property that assumes the state of a process is generated at a particular time and is hidden from the observer. It assumes that the process satisfies the Markov property. The HMM is used in various applications such as reinforcement learning, temporal pattern recognition in almost all the current speech recognition systems.
37. What is a Minimax Algorithm? Explain the terminologies involved in a Minimax problem.
Minimax algorithm is a recursive and backtracking algorithm. It is used for decision making in game theory. The algorithm is used to select the optimal moves for a player by assuming that another player is also playing optimally. It is based on two players, one is called MAX, and the other is called the MIN.
The terminologies that are used in the Minimax Algorithm are:
- Game tree: A tree structure encompassing all the possible moves.
- Initial State: The initial position of the board and showing whose move it is.
- Terminal State: It is the position of the board when the game finishes.
- Utility Function: The function that assigns a numeric value for the outcome of the game.
- Successor function: It defines the possible legal moves a player can make.
38. What is the difference between parametric and non-parametric models?
| Differentiation | Parametric Model | Non-Parametric Model |
| No of Features | Uses a fixed number of parameters to build the model. | Uses an unbounded number of parameters to build the model. |
| Assumptions | It considers strong assumptions about the data. | There are fewer assumptions about the data. |
| Algorithms | Linear Regression, Logistic Regression, Naive Bayes | KNN, Decision Trees,Support Vector Machines |
| Benefits | These take compute faster and require less data | Have higher flexibility, power and performance |
| Algorithms | Linear Regression, Logistic Regression, Naive Bayes | KNN, Decision Trees,Support Vector Machines |
| Limitations | These are constrained, have limited complexity and poor fit | These compute slower and require more data |
Read More on How to Choose The Best Algorithm for Your Applied AI & ML Solution
39. What is a hyperparameter and how is it different from the model parameter?
| Differentiation | Model Parameters | HyperParameters |
| What is it? | These are internal to the model and can be estimated from the data | These are external to the model and cannot be estimated from the data. |
| How does it work? | These are features of the training that will learn on its own from the training data. | These are the parameters that will determine the entire training process. |
| Manually set up? | These are often not set manually by the practitioner. | These are often specified and set manually by the practitioner. |
| Used in: | These are required by the model when making predictions. | These are used in processes to help estimate the model parameters. |
| Examples | Split points in Decision TreesWeights and biases | Learning Rate in gradient descentNumber of epochs in ANNNumber of layers in ANN |
40. What are different algorithms used for hyperparameter optimization?
The three main hyperparameter optimization algorithms are:
- Grid Search: It is a way to detect the family of models parameterized by a grid of parameters. It trains the model for all the possible combinations from the value of hyperparameters provided.
- Random Search: In this, it randomly searches the sample space and evaluates the sets from a probability distribution. Here, the model is run only a fixed number of times.
- Bayesian Optimization: It uses Bayes theorem to direct the search to find the minimum or maximum objective function. It is most useful for objective functions that are complex, noisy, and/or expensive to evaluate.
41. What is Gradient Descent?
Gradient descent is an optimization algorithm used to minimize the cost function, which is the error term. It is an iterative method that converges to the optimum solution by moving in the direction of the steepest descent as defined by the negative of the gradient. The gradient descent technique has a hyperparameter called learning rate, α that specifies the jumps the algorithm takes to move towards the optimal solution.
42. What are ensemble techniques?
The general principle of an ensemble method is to train multiple models and combine those predictions with improving robustness over a single model. The technique trains multiple weak predictors on a dataset. These get slightly different results, some models learn some patterns better, and others learn other patterns and then combine their predictions to get overall better performance.
43. What are the two paradigms of ensemble methods?
The two paradigms of ensemble methods are:
- Parallel ensemble methods: these methods build the several estimators or models independently and then take average for regression or voting for classification problems. Example are: Bagging methods, Random Forest
- Sequential ensemble methods: These fall under the family of Boosting methods where the base estimators are butilt sequentially and then reduces thes bias of the combined estimator. Examples: AdaBoost, Gradient Boost, XGBoost.
Advanced Level AI Interview Questions and Answers
44. What is Alpha-beta Pruning?
Alpha–Beta pruning is a search algorithm that tries to reduce the number of nodes searched by the minimax algorithm in the search tree. It can be applied to ‘n’ depths and can prune the entire subtrees and leaves.
45. Explain Artificial Neural Networks. Explain the commonly used ANNs.
Artificial Neural Networks (ANN) are the statistical models that are inspired by the functioning of human brain cells called neurons. ANN can mathematically model the way the biological brain works allowing the machine to think and learn the same way the humans do- making them capable of recognizing things such as speech, objects and animals in the same way a human does. Some of the most commonly used ANNs are:
- Feedforward Neural Network (FNN)
FNN is the first and simplest form of ANN wherein the connections between the nodes do not form a cycle. That means the data or the input travels in one direction and the data passes through the input nodes and exits on the output nodes. In this network, there may or may not be hidden layers.
- Convolutional Neural Network (CNN)
CNN is a type of feed-forward artificial neural network with variations of multilayer perceptrons designed to use minimal amounts of preprocessing. A convolutional neural network takes the input features batch-wise like a filter, assigns importance (learnable weights and biases) to various aspects or objects in the image, and is able to differentiate one from the other. The network is able to remember the images in parts and compute the operations. It is mostly used to analyze visual imagery, for signal and image processing.
- Recurrent Neural Network (RNN)
A recurrent neural network works on the principle of saving the output of a layer and feeding this back to the input to help in predicting the outcome of the layer. This network uses the internal state (or memory) to process the variable-length sequences of inputs and hence can handle the arbitrary input or output lengths.
- Autoencoders:
This type of artificial neural network learns the data codings in an unsupervised manner. These unsupervised learning models have input, output and hidden layers connecting them. These are mostly applicable for dimensionality reduction, by training the network to ignore signal “noise” and for learning generative models of data. It is applicable in image reconstruction and image colorization.
46. What are the hyperparameters of ANN?
The hyperparameters of ANN are:
- Activation function: it defines how a neuron or a group of neurons activate (‘spikes’) based on the input connections and bias terms.
- Learning rate: The learning rate implies how fast the network learns its parameters. It is the step size for the gradient descent.
- Number of Layers: ANN contains multiple layers: input, output layers and the layers between these are called as hidden layers.
- Momentum: It is the momentum for the gradient descent. This parameter helps in coming out of the local minima and smoothening the jumps while the gradient descents.
- Number of epochs: It defines the number of times that the learning algorithm will work through the entire training dataset.
47. What is Long short-term memory (LSTM)?
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network capable of learning order dependence in sequence prediction problems. It uses special units in addition to the standard units which include a ‘memory cell’ that can maintain the information in memory for long periods of time. LSTMs are complex areas of deep learning used in domains such as machine translation, speech recognition.
For more deep learning focussed questions, you may also read Top 40 Deep Learning Interview Questions
48. List the variants of RNN.
- LSTM: Long Short-term Memory
- GRU: Gated Recurrent Unit
- End-to-end Network
- Memory Network
49. What is perceptron?
Perceptron is an algorithm for the supervised classification of the input into several possible non-binary outputs. It is a linear classifier that makes all of its predictions based on a linear predictor function combining a set of weights with the feature vector.
For further reading on perceptrons refer here.
50. What are Bayesian Networks? How is it used in AI?
Bayesian networks are graphical models showing the probabilistic relationship between the set of variables. It depicts the variables and their respective conditional probabilities in the form of a directed acyclic graphical. These are based on the Bayes theorem, which uses conditional probabilities. It is used to detect anomalies, classification of e-mail as spam in medical diagnosis.
51. What is the use of Computer Vision in AI?
Computer vision, a field of Artificial Intelligence, is used to obtain information from images or multi-dimensional data. The computers are trained to interpret and obtain information from the visual world, such as images. Computer vision uses AI technologies to solve complex problems such as image processing, object detections. In machine learning algorithms, K-means is used for Image Segmentation; Support Vector Machine is used for Image Classification
52. What is game theory? Is it related to AI?
Game theory is a specialized branch of mathematics dealing with opposing and rational players trying to achieve a specific set of goals. A rational player means each of the players has the same understanding and knowledge. AI is useful in this scenario. The players have to choose between the given set of options in a multi-agent environment where one player’s choice affects the choice of the other or opponent players.
53. Which algorithm does Facebook use for face verification and how does it work?
Facebook uses DeepFace for verification. This deep learning algorithm identifies the digital images’ faces using neural network models and allows the photo tag suggestions upon uploading a photo on Facebook.
Following are the things to consider when understanding how to face verification works are:
- Input: Scanning an image or a group of images
- The process is:
- Detection of facial features
- Feature comparison and alignment
- Key pattern representation
- Final image classification
- Output: Face representation, which is a result of a multilayer neural network
- Training data: Involves the usage of thousands of millions of images
54. How can AI be used in fraud detection?
For Fraud detection problems, AI is implemented using Machine Learning algorithms to detect anomalies and studying hidden patterns in data. The steps used in fraud detection are:
- Data Extraction: The first step is to extract data. The data to collect depends on the type of the model. It is collected either through a survey or web scraping. This includes information such as personal details, demographic, transactional details, shopping,
- Data Cleaning: In this step, the irrelevant or redundant data is removed in this step. Any inconsistencies or missing values may lead to wrongful predictions, therefore such inconsistencies must be dealt with at this step.
- Data Exploration & Analysis: This is one of the important steps which involves finding out the relationship between various predictor variables.
- Building Models: To detect the fraud, build the model using either Logistic Regression or any of the classifiers.
- Model Evaluation: It is an important step to evaluate and validate the efficiency of the machine learning model. To improve the accuracy of the model, can perform hyperparameter tuning.
55. What is a heuristic function and where is it used?
A heuristic function estimates how close a state is to the goal. It is used in Informed Search that is in the search algorithms that ranks the alternatives at each branching step based on the available information to decide which branch to follow. It calculates the cost of an optimal path between the pair of states.
56. What is market basket analysis and how can AI be used to perform it?
The term market basket analysis explains the combinations of products that frequently co-occur in transactions. In the retail business, it allows the retailers to gain insight into the product sales patterns by analyzing the historical sales records and customers’ online browsing behavior. This is applied in machine learning using the technique of Association Rule, which discovers the probability of the co-occurrence of items in a collection.
For instance: a supermarket chain had discovered in its analysis that customers who bought diapers had also bought beer and they started placing diapers close to beer coolers which increased their sales dramatically.
57. What is the Bias-Variance tradeoff?
Bias is the difference between a model’s predicted values and the observed or the actual values. Variance of a model is the difference between predictions of the model when fit to the train and the test data set.
When a model is too simple, then it cannot make perfectly accurate predictions. However, the predictions will be consistent. In such a case, the model will be underfitting and have high bias and low variance. On the other hand, if the model is too complex, it can predict accurately but not consistently. In this case, the model is said to have high variance low bias indicating it will much better fit the train data than the test. Such a model is an overfitted model. This is the trade-off between the bias and variance illustrated by the graph below:
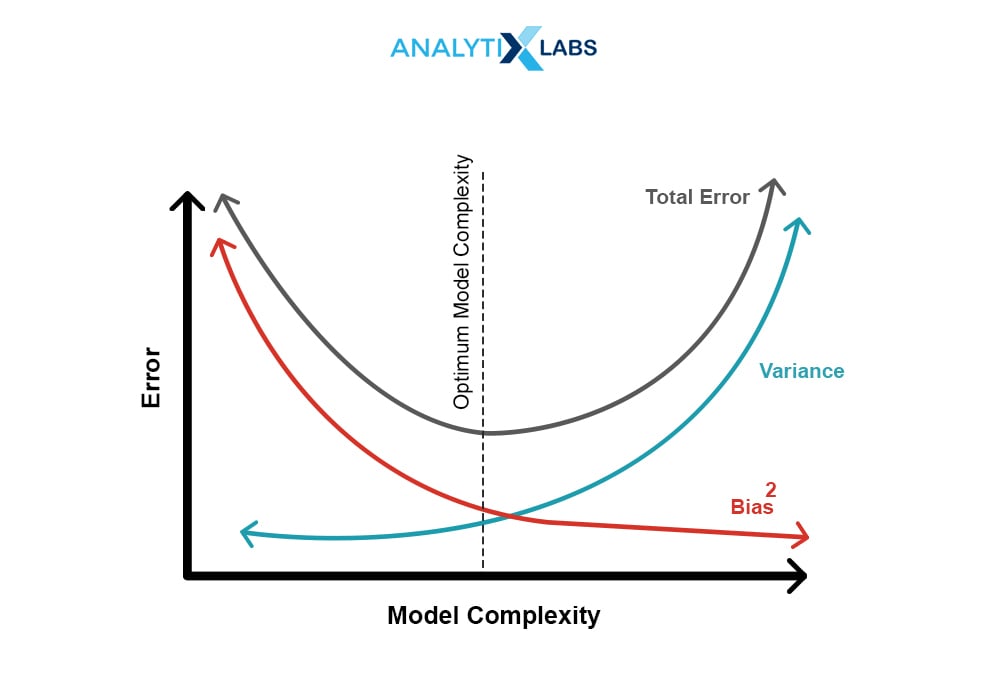
58. What is regularization in Machine Learning?
Regularization refers to the modifications made to an algorithm that helps it in reducing the generalization error. It adds a penalty term to the cost function such that the model with higher variance receives a larger penalty. It chooses a model with smaller parameter values (i.e., shrunk coefficients) that has less error.
For more details on Q57 and Q58, please read: What Is Regularization in Machine Learning?
59. What is a hash table?
A hash table is a data structure used to produce an associative array that is mostly used for database indexing.
60. What interests you most about AI? What is your favorite use case of AI?
There is no ready answer to this question. It requires you to genuinely introspect, see what inspires and motivates you to take all the pain to walk on this path of getting into the domain of Artificial Intelligence.
FAQs – Frequently Asked Questions
Ques. What is Artificial Intelligence?
“Artificial Intelligence (AI) is an area of computer science that emphasizes the creation of intelligent machines that work and react like humans.” “The capability of a machine to imitate intelligent human behavior.”
To know more about the basics of AI, you may also like to read:
101 of Artificial Intelligence (AI) – What to Know as a Beginner?
Ques. What are the four types of Artificial Intelligence?
The four types of Artificial Intelligence are:
- Reactive Machines
- Limited Memory
- Theory of Mind
- Self Aware
Ques. How to prepare for the interview?
- Must do basic research on the organization that you are thinking of applying to. The employer will certainly assess your interest in the role based on your knowledge of the firm.
- Be punctual even in the times of virtual online interviews. Ensure you log in before time and be present as you would have for an in-person interview.
- Be honest and integral if you don’t know anything. Do not add anything on your resume that you haven’t worked on and don’t know fully. Try to answer that question most logically based on your knowledge and understanding.
- Listen to the interviewer and answer only when asked to do so. Ask if you are not clear about the question. It is good to clear your doubts rather than answering without understanding the question.
- It is good to have a list of questions to ask the interviewer at the end of the interview. It reflects your interest both in the company, the role applied, and your willingness to learn.
If you have any questions or want to share your feedback, please reach out to us in the comments section below. Happy Studying!
For hands-on AI projects, also refer to 18 (Interesting) Artificial Intelligence Projects Ideas
You may also like to read:
1. Top 75 Natural Language Processing (NLP) Interview Questions





