
1. What Is Big Data Engineering?
Data engineering is a field associated with a set of activities & tasks that enables organizations to capture the data from various sources, process, and make it ready for further use such as Business Analytics, AI & Data Science Solutions, etc.
Let us understand some of the key features of Data Engineering:
- Integration of various data sources, making data reliable and consumption ready to perform downstream tasks (Machine Learning, Data Analysis, Visualization, etc.)
- Set up reliable infrastructure (Hardware, Scalable data management systems, and frameworks) to perform data-related tasks.
- Create & Manage centralized data stores/ databases (Enterprise Data Ware House, Data Lake, Data Ocean, etc.)
- Perform data-related tasks like collection, parsing, transferring, storing, updating, querying, sharing, searching, processing, Manipulating, transforming, cleaning, organizing, Analysing & visualizing. However, Reports & Dashboards are not the data engineer’s primary job role.
- Build and Manage Data pipelines to create data lineage process (Real-time & Batch data)
- Also, take care of Data Modelling, Data Security, Data Privacy, Sensitive data protection, Data Compliance ( as per GDPR and other Regulatory Bodies), Data Quality, Data Governance, Data Mining, Capturing & Managing Meta Data and Production, etc.
Data Engineering is not a new phenomenon. If we relate with previous job roles, we can consider Data Engineering is a superset of Enterprise Data Ware Housing & Business Intelligence along with some elements of Software Engineering. This field integrates with a specialization around the ‘Big Data Distributed systems”, “Stream Processing,” and “Computation at Scale.”
Let us understand why Data Engineering is crucial for every enterprise:
- Data engineering plays a huge role in bridging the gap between Data Science and software engineering by efficiently building production code to scale Data Science.
- There is no Data Science (Machine learning & AI) without Data Engineering. Push for Data Science is also increasing the demand for Data Engineering.
- The volume of data is increasing every day, and more data helpful for better predictions.
- Semi-Structured/ Unstructured data is growing in every organization and requires strong big data engineer skills to manage this type of data efficiently.
- The rate of data generation is increasing exponentially, and the hour’s need is to make decisions in real-time. We need timely data along with Data Science to solve these types of problems.
- Data generation systems are increasing (Web, mobile, IoT, Internet, social data, logs, etc.), and data engineering is required to integrate various systems and create data lineage, etc.
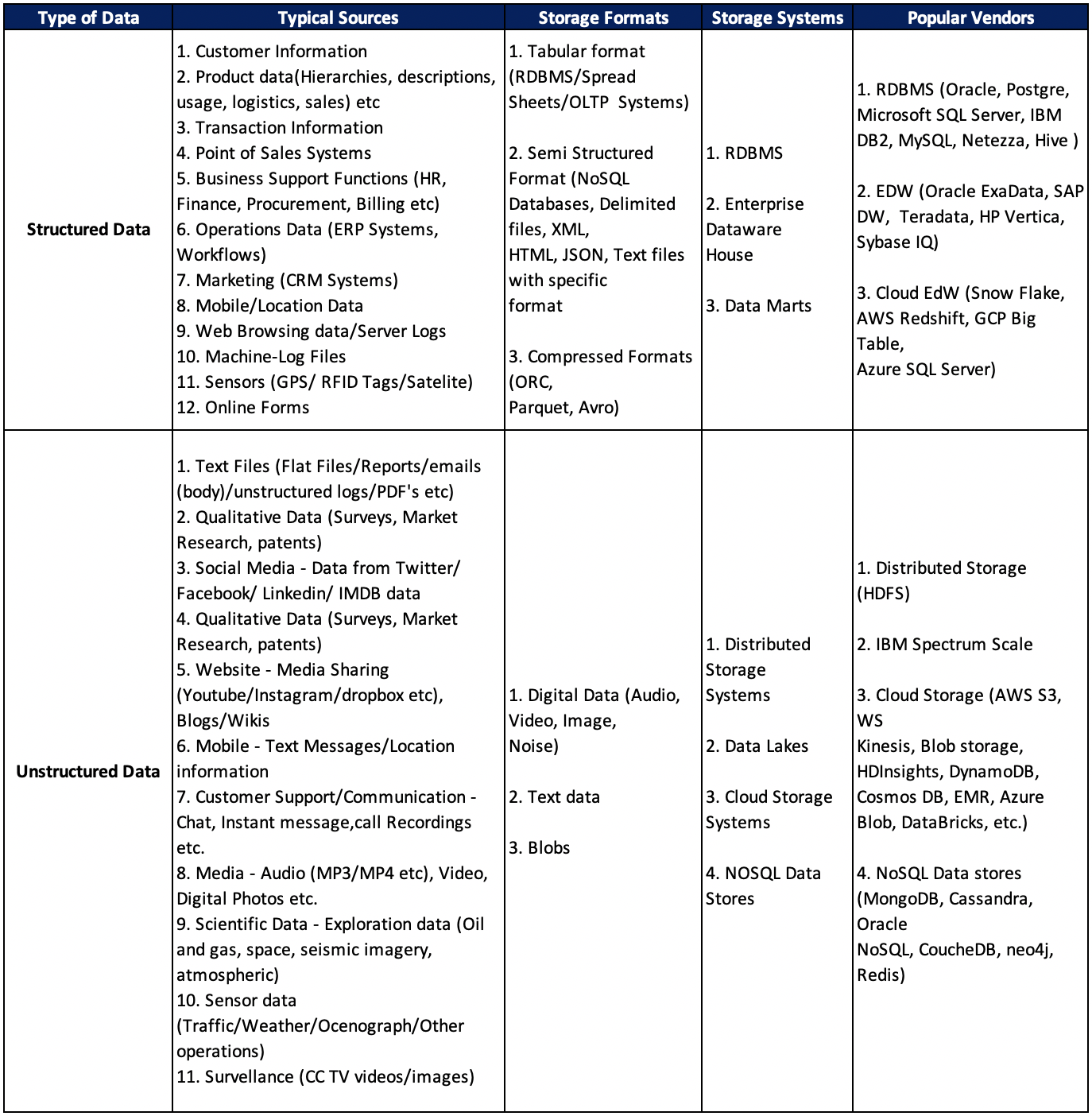
The following table summarizes how data generation sources & formats are increasing and what storage systems and vendors are available to manage different types of data.
What is changing in Data Engineering?
The following are key changes you can observe in Data Engineering in recent days.
- ETL is changing: You can see a clear shift from Drag and Drop ETL tools towards a more programmatic approach because of data complexity. The rate of data generation is increasing exponentially. The traditional ETL tools like Informatica, Microsoft SSIS, Data Stage are obsolete because logic can’t always be coded, and these tools get replaced by more generic, programmatic. Configuration-driven platforms like OOZIE, Airflow, Luigi, etc., and these tools help to manage job scheduler/orchestrator.
- Data Modelling Changing: As part of Data Ware House design, typical data modeling had done using ‘Star Schema’ for the analytical workloads. Because Storage and computing is cheaper and scale-out using distributed storage & computing systems, there are many changes taken place in Data Modelling like
- Further denormalization
- Blob Storage
- Dynamic Schemas Etc…
- Managing Big Data using SQL like Language: In the past, we used to use the MapReduce framework to manage Big Data. However, MapReduce requires knowledge of programming, and writing programs for every small task will be a challenge. Of late, we can observe a big shift from the MapReduce framework to SQL like languages, for example, Hive.
What is Modern Data Engineering?
Data Engineering required specialized skills to perform various tasks. However, modern Data Engineering deals with technology/platforms to support ‘Citizen Data Engineers’ (like Business Analysts, Data Analysts, Data Scientists, database administrators, Database operators, etc.) to perform these tasks quickly manner with minimal skill set. It also helps to streamline operations and reduce costs with minimal workforce interruption.
Example: Modern data engineering platforms providing SQL like interfaces to interact with Big Data or distributed databases without writing MapReduce or spark jobs.
Modern Data Engineering platforms abstracting the complexity of these tasks and supporting end-to-end and operationalized data pipelines, which can run on cloud/on-premises using modern distributed processing frameworks like Spark. Most of these platforms support continuous integration, continuous deployment, monitoring, alerting, security compliance, etc. These solutions are also less expensive, more flexible, and easily scalable to store and manage data.
2. How Data Engineering Is Related To Data Science?
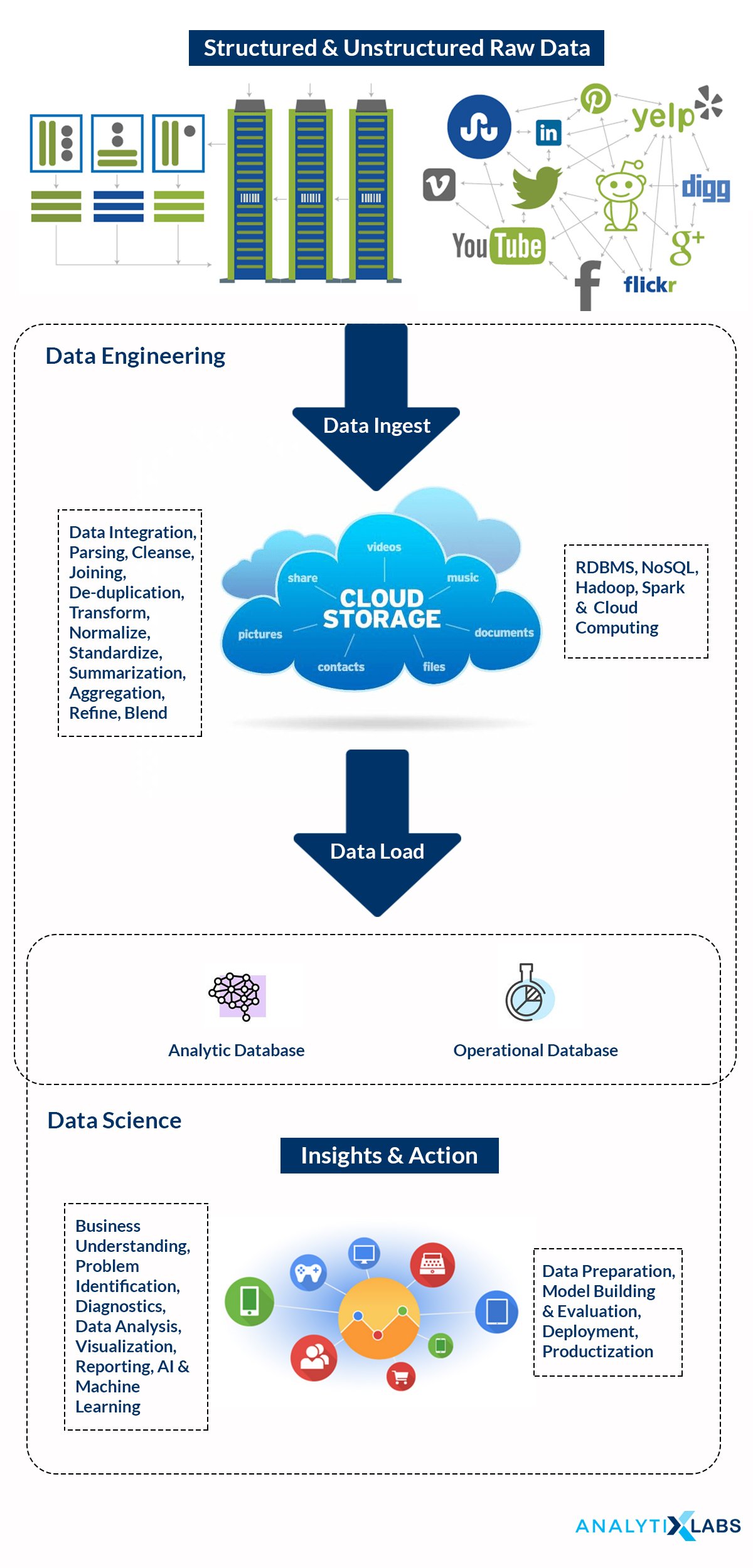
The famous phrase “Garbage In, Garbage Out” explains the relationship between Data Engineering and Data Science. It emphasizes the importance of quality input to the model for Data Analytics to get valid and reliable results.
Data Engineering and Data Science feed and complement each other. The Data Engineering team organizes and delivers data to systems and consumers (like Analysts, Business Analysts, Data Analysts, Data Scientists, System Architects, Business Leaders) in a reliable, consistent, quick, and secure manner. On the other side, Data Science teams use this data for performing data exploration and diagnostics to find answers to specific business questions, building predictive models to solve complex business problems, and other data analysis to provide insights for business executives to understand the status and define strategy.
The Data Engineering team works with various groups from Data Science teams to understand the data requirements & requisite formats so that the Data Engineering team builds data pipelines accordingly that can source, transform and deliver the data as per the required format and is production-ready.
Data Engineering makes Data Science teams more productive; else, these teams would spend the majority of time preparing data for analysis rather than solving complex business problems and developing Data Science solutions.
Data Engineering requires a strong understanding of engineering, technologies, tools, and best practices for faster execution of large data sets with reliability and consistency.
Relationship between Data Engineering & Data Science
3. Who is a Data Engineer and Role of Data Engineer?
A Big Data Engineer is responsible for preparing and make data useful and ready for analytical and operational use cases.
The responsibilities of Data Engineers may vary from organization to organization based on the size of data, infrastructure (software & hardware), domain, size of the company, size of the team, data sources, priority, data strategy, etc. However, the list of key responsibilities as following:
Key Responsibilities of Big Data Engineer:
- Work with various teams, including Business Leaders, Product Managers, Data Scientists, Modellers, AI Engineers, IT Specialists, Software Developers, and Architects, to assist with the required data appropriately and support their data infrastructure needs.
- Prepare and optimize data pipeline, making data collection flow more efficient for cross-functional teams and improvise functionality in existing data systems.
- Managing a variety of complex data sets with the size of terabytes/petabytes that meets business requirements
- Build & maintain optimal data pipelines in reliability that can feed various use cases
- Develop, maintain, test, and evaluate Big Data solutions. Storing and processing data securely at all times.
- Develop, construct, test, and maintain infrastructure/architecture related to large-scale data processing systems and data warehousing solutions along with data modeling, ETL (extraction, loading & transformation). Ensure infrastructure like data storage and collection systems meet business requirements with acceptable industry standards.
- Identify, design, implement, and manage internal process improvements by automating manual processes, re-designing existing data infrastructure for greater scalability, reliability, efficiency, security, quality, and information security compliance.
- Building streamlines for delivering “on the fly” solutions and also should be comfortable with data processing patterns (Batch Processing, near real-time processing, and real-time Processing), etc.
The following table summarizes the key areas in Data engineering & key tasks under each area.
| Sr. No. | Key Areas of Data Engineering | Key Tasks |
| 1. | Database Design/ Data Architecture/ Infrastructure Setup | Designing of data systems (How to model & flatten particular systems) |
| 2. | Data Acquisition/ Ingestion/ Instrumentation | – Sourcing data from different systems (scrapping web source, loading log files, getting real-time data from streaming sources, fetching data from internal/external data stores with the help of connectors & API) – Log events and attributes related to those events |
| 3. | Big Data Storage & Handling | – Storing data in databases/Dataware house/Datalake/ Distributed databases/ Cloud storage systems – Handling of huge data, combining large datasets, etc |
| 4. | Data Manipulation/ Cleansing/ Wrangling/ Preparation/ Curation | – Identify and correct errors – Convert data from one format to another format – Normalize/Standardize Data – Remove disambiguation, Duplicates, etc – Calculating new metrics – Transform, Summarize/Aggregate data |
| 5. | Anomaly Detection | Generate automated alerts to identify anomalous events occur in terms of data consumption or when there are unusual trends observed |
| 6. | Meta Data management | Create an automated process of generating & consuming metadata to find information in the data store easy manner |
| 7. | A/B Testing | Experimentation frameworks to optimize & fine-tune the process |
| 8. | Pipeline Building/ Sessionization | Creating pipelines of a series of actions at a time which helps to perform a specific task |
| 9. | Data Security & Governance | – Take care of centralized security controls like LDAP – Encryption of data (Specifically sensitive information etc.) – Auditing access to the data |
| 10. | Soft Skills | Problem-solving, Perseverance, Team spirit, etc. |
4. How to become a Big Data Engineer: Key Skills
Most of the companies prefer below mentioned big data engineer skills. However, the skillset may vary from organization to organization based on the employer, role, type of data sources, etc.
- Education Background: Quantitative academic backgrounds like Engineering Discipline (B.Tech, M.Tech), Computer Science (BCA, MCA), and information systems with familiarity with different software tools to manage the life cycle of data.
- Having experience in writing high quality, maintainable SQL, NoSQL queries on large datasets
- In-Depth Knowledge of data sources including relational databases, NoSQL Databases, distributed storage & processing systems, and cloud platforms
- Strong analytical & problems solving skills on internal and external data and processes to answer specific business questions and identify opportunities for improvement
- Having a working knowledge of dealing with structured/unstructured datasets and extracting value from large disconnected datasets
- hands-on knowledge of creating workflows supporting data acquisition (batch & stream processing), data manipulation/transformation, data structures, metadata, message queuing, and workload management.
- Experience in supporting and working with cross-functional teams and performing root cause analysis on internal and external data and processes to answer specific business questions and identify opportunities for improvement.
- Experience with cloud environments like (AWS/Azure/GCP) especially data warehouses like Redshift, Azure SQL DW, Snowflake, Google Big Query and knowledge in Elastic search & Kibana, REST APIs
- Technical Stack: Most of the companies use the software tool kit below to manage data engineering-related tasks. Not everything is required for every project – so you need to target relevant tools/software as per the role and number of job opportunities.
| Sr. No. | Area | Software Stack |
| 1. | Data Modeling Tools | Oracle, Erwin |
| 2. | Data Integration | Microsoft SSIS, Talend, Informatica, Datastage, Pentaho, RedPoint, Knime, Cognos, AbInitio |
| 3. | Big Data (Ingestion, Storage, Computing) | Hadoop (HDFS, Sqoop, Hive, Impala), Spark (SQL, Streaming, ML, Graph), Kafka, etc. |
| 4. | Relational Databases (SQL Based Databases) | MS SQL Server, MySQL, Teradata, Postgres, IBM DB2, SAP Data Ware House, Oracle Exadata, Netezza, Greenplum, Presto (Running Interactive SQL Queries on Different data stores) |
| 5. | Cloud Relational Databases | Redshift, Azure SQL Server, Snowflake, Athena, Google BigTable |
| 6. | NoSQL databases | MongoDB, Casandra, Oracle NoSQL, neo4j, Hbase, Redis, Couch Base |
| 7. | Data pipeline and workflow management tools | Airflow, Azkaban, Luigi, Cloud Data flow, Oozie, etc. |
| 8. | Cloud Platforms | AWS (EC2, EMR, RDS, Redshift, S3, Data Pipeline, Glue, CloudWatch, Lambda, IAM, ), Azure, GCP (Data proc, BigQuery, Data Flow, Pub-Sub, etc.), DataBricks, Oracle Cloud, IBM Cloud |
| 9. | Stream-processing systems | Storm, Flink, Spark-Streaming, Kafka, NiFi, Samza, Heron etc. |
| 10. | Data Wrangling/Data Preparation/Data Manipulation | Python(pandas, NumPy, re, etc.), R (data.table etc.), Spark, SQL, etc |
| 11. | Data Quality Tools & Framework | Cloudingo, Informatica Master Data Management, Talend Data Quality, TIBCO Clarity, Quality Control, Backoffice, Experian, etc. |
| 12. | Containers | Virtual Machines, Docker, Kubernetes |
| 13. | Connectors & API’s | ODBC, JDBC, REST, sFTP etc |
| 14. | Automaton Tools | Jenkins, Travis |
| 15. | Scripting languages/Programming Languages | Python, Java, Scala, etc. |
| 16. | Reporting & Data Visualization | PowerBI, Tableau, Qlik, Spotfire, d3.js etc. |
| 17. | Version control | Git |
| 18. | Development Proces | Agile |
| 19. | Operating Systems | Linux, windows |
5. Which Courses & Certifications Are Available For Data Engineering?
Below are the popular learning options and available courses in different formats:
Following are some acclaimed professional certifications offering by reputed organizations:
- Certified Big Data Engineering Course from AnalytixLabs: This is one of the most comprehensive and well-rounded courses designed & crafted by industry experts in collaboration with IBM. Keeping pace with the changing industry landscape, this course has evolved several times since 2015 to ensure job-oriented skills. Participants get hands-on experience related to:
- RDBMS using SQL
- NoSQL Databases using MongoDB
- Distributed storage & processing using Hadoop Ecosystem
- Spark Streaming & Scalable Machine Learning
- Cloud computing for Analytics
Available in both classroom & online format, this program extensively course covers all the aspects & necessary skills related to data engineering.
- Certifications offered by Technology Companies: The below companies are offering certifications related to their products.
- Amazon Web Services (AWS) Certified Big Data – Specialty
- Google Cloud Certified Professional Data Engineer
- Microsoft Certified Solutions Associate (MCSA) in Data Engineering with Azure
- MongoDB’s Certified Developer certification.
- IBM Certified Data Engineer – Big Data
- IBM Certified Data Architect – Big Data
- Cloudera Certified Professional (CCP) Data Engineer
- Oracle Business Intelligence Foundation Suite 11 Certified Implementation Specialist
- SAS Certified Big Data Professional
Etc…
- Certified Data Management Professional (CDMP): Data Management Association International (DAMA) offering certification at two levels (Mastery & Practitioner) who got complete three exams (1. Information systems 2. Data management, 3. Choose one exam from the choices (Data warehousing, Business Intelligence Analytics, Data & Information Quality, Data Development, Data Operations, Zachman Enterprise architecture framework)
- Data Science Council of America (DASCA): DASCA offering two different certifications (Associate Big Data Engineer, Senior Big Data engineer)
Massive Open Online Courses (MOOC)
- EDX (Data Science and Engineering with Apache Spark, Computational thinking, Big Data, etc.)
- Coursera (Big Data Specialization, Data Engineering & Big Data on Google Cloud Platform, Data Engineering with Google cloud, Big Data & Data Engineer Certification, Professional Data Engineer, Data Warehousing for Business Intelligence Specialization)
- Become a Data Engineer: Mastering the Concepts by Lynda
- Data Engineering Nanodegree Certification (Udacity)
Courses Offering By Universities:
- UC San Diego: Big Data Specialization
- Introduction to Data Engineering Program by the University of Washington Etc.
6. Job Market & Average Salary of a Data Engineer?
The field of Data Engineering is constantly evolving. Since 2014, job postings related to Data Engineers have increased as Big Data is a crucial and indispensable part of every modern age organization’s data strategy. The average increase in the US job postings is ~83% Year on year from the last 12 months based on the recent data taken by Burning Glass’s Nova platform.
The data is growing faster than ever, and data is created in the last two years more than data created in the entire history of mankind. As data becomes more complex & keeps growing, the role of Data Engineering will be critical and continue to grow in importance. Companies want to get the maximum value out of this data, and most of them are looking for data pipeline builders as they migrate to the cloud.
Different Roles in Data Engineering: You may come across job titles below related to data engineering.
- Data Engineer
- Big Data Engineer
- Data Architect
- Database Engineer
- Analytics Data Engineer
- Cloud Computing Engineer
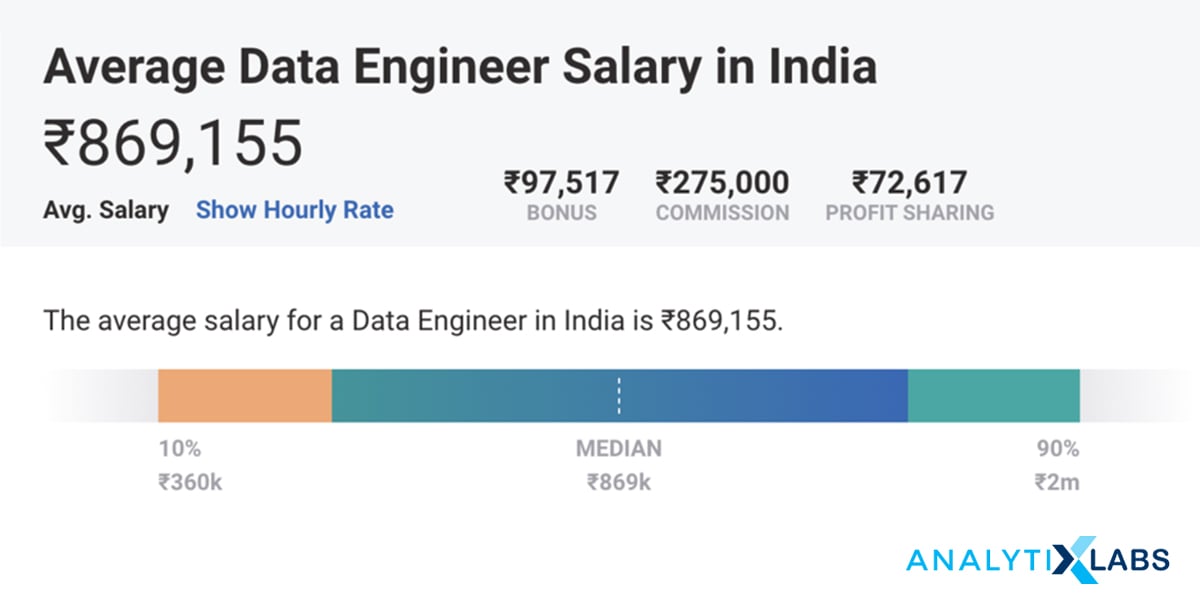
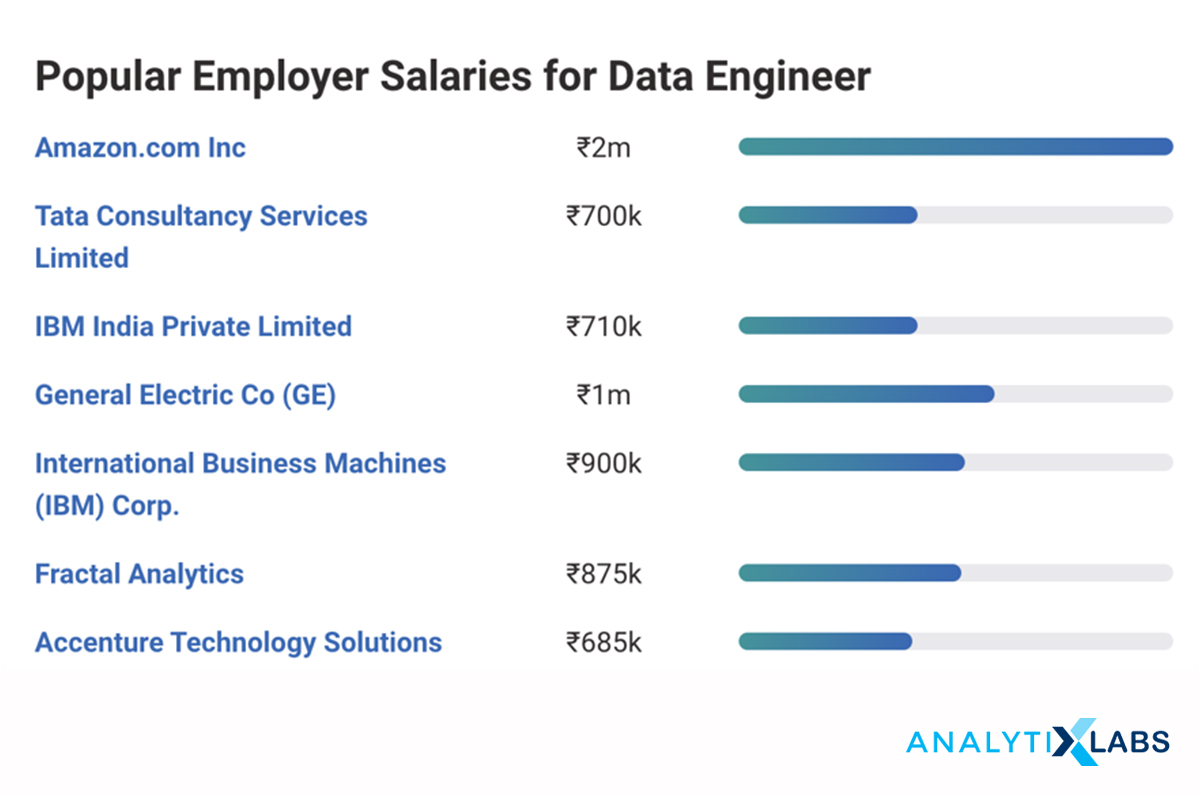
Salary of Data Engineer: The answer to this question will vary “from year to year,” “from location to location,” and “from Role to Role” and “Employer to Employer.” The salary numbers in India are different from the salary in other parts of the globe.
The below snapshot provides us a good sense of the salaries of Data Engineer & related job roles based and how it varies from organization to organization. As per the recent data from Glassdoor & PayScale, a data engineer’s average salary is around INR 8.5 lakhs per annum in India and goes up to INR 20 lakhs per annum.
You may also like to read:
1. Big Data Job Opportunities and Trends | Career in Big Data
2. What is Big Data Architecture, Its Types, Tools, and More?






1 Comment
Thanks for sharing valuable article about every aspect of data engineering.