
Machine Learning (ML), Data Mining, and Pattern Recognition are highly relevant topics most often used in the field of automation with Artificial Intelligence (AI). Irrespective of their overlapping similarities, these ideas are not identical. Over the past few years, there have been huge leaps in Data Science and Big Data, which have led an average business user to grapple with the lexicon on tech terminology. This development has caused nothing but confusion among people since they aren’t sure of the differences between terms and concepts. In our opinion, Machine Learning, Pattern Recognition, and Data Mining are significant examples of this.
This is the reason why we have created this post. Our goal is to define all three approaches and set out how data mining, pattern recognition, and machine learning differ from each other. As an aspirant who wants to explore these fields or as an enthusiast who has never quite grasped the dissimilarities, you can look through our ML, Data Science, Data Analytics, and many more courses that can help propel your technical career after reading this article.
Machine Learning (ML) vs. Pattern Recognition vs. Data Mining
It is always a challenge to describe the difference between the three fields since there is considerable confusion because of significant overlap regarding the objectives and approaches.
Pattern recognition is the most ancient of the three fields, dating back to the early 1950s when practitioners and researchers were trying to develop systems for speech recognition and optical character recognition (OCR). It is a field that revolves around the design and development of machines to group or recognizes patterns, such as processes, signals, images, and objects, apprehended through a sensing mechanism.

When we talk about machine learning, it is a subset of artificial intelligence, and it is focused on learning relationships present in data for building classification models. Machine learning emphasizes the algorithmic models to access their properties and learn.
The data mining process, on the other hand, is the latest of all (in terms of origin) and first time appeared in 1990. It is used to designate activities with a strong application focus. In simple terms, the data mining process is focused on extracting useful patterns from data – essentially from business data.
Both machine learning and pattern recognition approaches form a critical component for any data mining effort. The three fields overlap so much so that one can, without a doubt, think that they are the same. For instance, machine vision and computer vision are only distinguished by applicability. That is, machine vision focuses more on the engineering side, and computer vision focuses on the research/academic side; however, technically, they are the same.
With that said, let’s discuss each of the approaches in detail.
Pattern Recognition
Simply put, pattern recognition gives a company a strategic advantage, which makes it capable of steady evolution and improvement in the ever-changing market.
It is the process of segmenting and distinguishing data as per common elements or set criteria, which is performed by special algorithms. Pattern recognition enables room for further improvement, which makes it an integral part of machine learning technology. It identifies patterns in data that tell the data stories through spikes and flat lines, ebbs, and flows.
The data can be anything from:
- Sentiments
- Sounds
- Images
- Texts, and others
The three main models of pattern recognition are:
- Template Matching: to match the features of the object using a predefined template and analyse the object by proxy. One of the examples of template matching is ‘Plagiarism Checking.’
- Syntactic/Structural: to interpret a complex relationship between components, such as ‘parts of speech.’
- Statistical: to determine where the particular pieces belong. For example, to identify whether the object is cake or not.
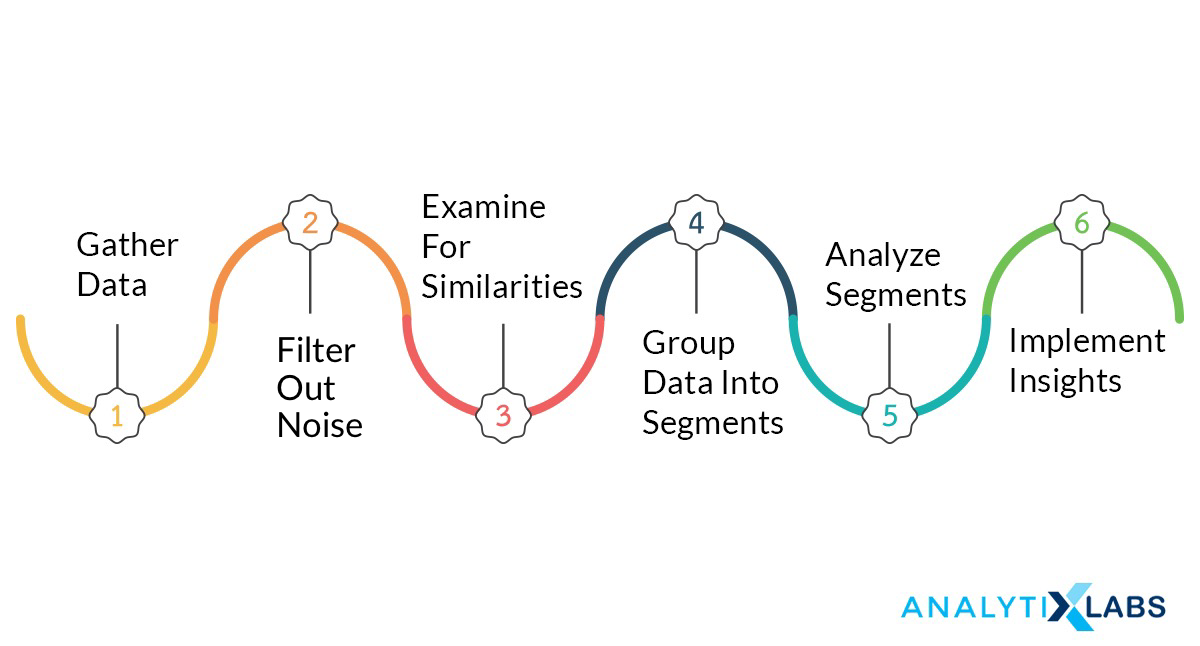
The process involved in pattern recognition include:
- Through input or tracking, data is gathered from its sources
- Using special tools, data is swabbed from noise
- The information retrieved is scrutinized for common elements or relevant features
- These elements or features are later grouped in particular categories
- Next, these categories are examined for insights into data sets
- Finally, the derived insights are executed into the business operation
The prominent use cases of pattern recognition are:
- Data Analysis: Audience Research and Stock Market Forecasting – for the comparative study of stock exchanges and forecasting of possible outcomes, as well as analysing user data
- Natural Language Processing: Chatbots, Text Translation, Text Analysis, and Text Generation- for topic discovery, plagiarism detection, finding the meaning of the text, and recreation of the message in other languages
- Optical Character Recognition: Signature Verification and Document Classification – for processing handwriting samples, text transcription, and deeper processing of the document
You may also like to read: How Is Machine Learning Used for Stock Market Prediction?
Data Mining Process
Data mining also referred to as knowledge discovery, is the process of identifying and discovering useful insights from significant volumes of data that are stored in data warehouses and databases. It is done for decision-making processes in businesses.
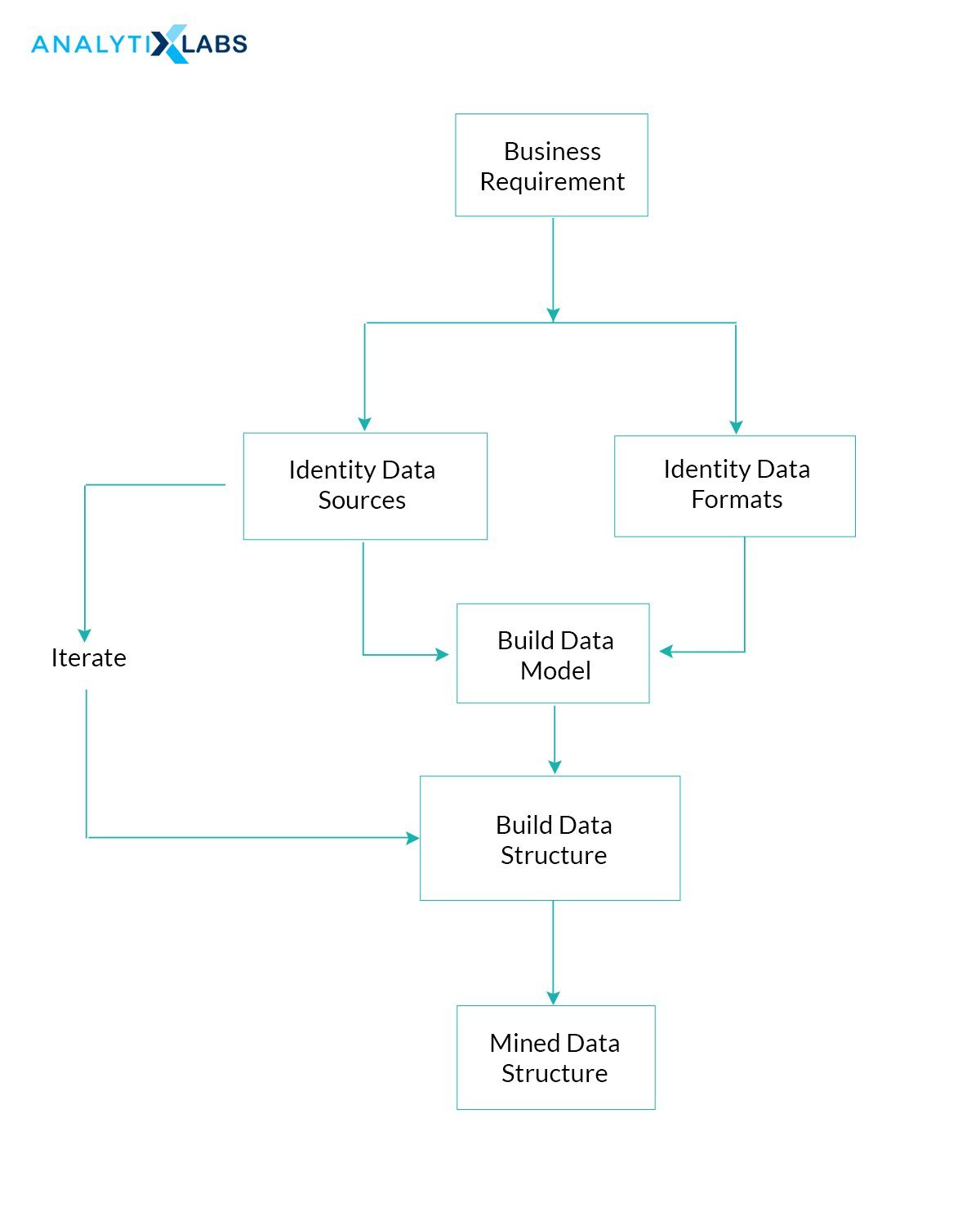
The process is carried out using numerous types of techniques that involve association, clustering, regression and decision tree, and sequential pattern analysis. In simple terms, it discovers knowledge and interesting patterns from large amounts of data. Over the years, the data mining process has become prevalent. Big Data has voluminous information about the varied content of varied types. Therefore, with the amount of data generated every single day, simple statistics with the manual intervention will not do any good. This void is filled by the data mining process.
In this process, the relevant information is extracted from raw data. This may include flat files, videos, photos, and transactions. The information is processed automatically to generate reports that are useful for the business so that they can take necessary actions.
Hence, data mining is critical for businesses to help them make better decisions by discovering trends and patterns in data, compiling the data, and retrieving relevant information.
Basically, the process is divided into two categories
- Data processing
- Data mining
In data processing, the steps involved are:
- Data Acquisition
- Data preprocessing
- Data integration
- Data reduction
- Data transformation
In data mining, the steps involved are:
- Data mining
- Data modelling
- Pattern evaluation
- Knowledge representation
All these steps are critical to the success of the data mining process since they help in determining the usefulness of data, which includes timelines, consistency, completeness, and accuracy. The data processed and mined has to satisfy the intended purpose. Therefore, processing is a crucial step in the mining process.
The prominent use cases of data mining are
- Financial Data Analysis
- Retail and Telecommunication Industries
- Science and Engineering
- Intrusion Detection and Prevention
You may also like to read: Data Mining Techniques, Concepts, and Its Application
Machine Learning (ML)
Machine learning is the process of enabling computer systems to carry out tasks that have been carried out by people. Simply put, it is teaching a computer system to make accurate decisions and predictions by feeding data.

The decisions or predictions could be anything from determining whether an email is a spam, the use of the term ‘book’ in a sentence relates to hotel reservation or a paperback, identifying people crossing the street in front of a self-driving vehicle, and answering a piece of vegetable in a picture is avocado or orange.
In a machine learning model, the computer systems are trained on a large amount of data to enable them to distinguish between the various elements of data reliably. Data is the key to making machine learning possible.
Machine learning is divided into two primary categories:
- Supervised learning
- Unsupervised learning
In supervised learning, computer systems are exposed to vast amounts of data that are labeled. For instance, they can be pictures of handwritten figures defined to illustrate which numbers they correspond to. A supervised learning system will learn to identify the clusters of shapes and pixels associated with each figure and hence, ultimately will be able to identify handwritten figures, among other aspects such as reliably differentiating between the numbers 7 and 5 or 1 and 0. You may also like to read about Classification in Machine Learning to understand more about supervised learning.
In unsupervised learning, machine learning algorithms are tasked with the identification of patterns in data. The goal is to identify similarities that divide that data into categories. For example, it can be a new website grouping stories on similar topics every day.
Final Words
Machine Learning, Pattern Recognition, and Data Mining are all essential features of this digital age. They all are unique by themselves and have highly incisive features to aid technological advancements and elevate the functionality of businesses. Coupled together, these superlative components can revolutionize how businesses operate and grow in the very near future, and bring in new prospects of the mingling of technology and operations in every industry all across the globe. Head on to AnalytixLabs and search through a multitude of ML, Applied AI, and Data Science courses, and make use of the knowledge to stay ahead in the industry.
You may also like to read:
1. Difference between Data Science vs Machine Learning vs AI Deep Learning
2. Difference Between Data Analysis and Interpretation – An Overview
3. Difference Between Data And Information? Data Vs Information





