
Advancements in data generation, storage, and management technologies have revolutionized the world. Today, we use data to find cures for diseases, construct buildings, and even efficiently target ads on social media.
Machine-readable information or data is essential for data scientists to identify patterns and gain insights. For example, customer data must include details like product purchases to be useful for a product team. Similarly, data must include customer loan status information to be relevant for a financial underwriting team. Data modeling is key to addressing these issues.
A data model is the process of assigning rules to data. It is crucial to uncomplicate data and convert it into useful information that a business can use to form strategies and make decisions.
This article will focus on understanding data modeling and its numerous concepts, such as its purpose, evolution, types, techniques, processes, best practices, etc.
What is Data Modeling?
High-quality data empowers organizations, enabling rapid progress by establishing baselines, objectives, and benchmarks. Well-organized data, with clear descriptions, semantics, and consistency, is essential for effectively measuring and advancing this progress.
A data model is important because it helps users understand the relationships between different data items. For example, an organization might have a huge data repository, but without a standard to ensure accuracy and interpretability, this data becomes more of a liability than an asset.
A data model ensures that the downstream analytics produce actionable results, promote knowledge of best practices regarding data in the organization, and identify the best tools to access and handle different data types.Data modeling visually represents information systems, using diagrams to illustrate data objects and relationships, aiding in database design or application re-engineering. Models can be created through reverse engineering, extracting structures from relational databases.
While the discussion is about what all data models do, let’s take an in-depth look at the various purposes that data models serve, but before that, a short note-
Explore our signature data science courses and join us for experiential learning that will transform your career. We have elaborate courses on AI, ML engineering, and business analytics. Choose a learning module that fits your needs—classroom, online, or blended eLearning. Check out our upcoming batches or book a free demo with us. Also, check out our exclusive enrollment offers
Understanding the Purpose of a Data Model
Data modeling visually represents datasets and their business context, aiding users in pinpointing needed information. It specifies data element characteristics in applications, databases, and file systems, supporting data governance programs by establishing common definitions and standards.
Data modeling documents data blocks and their movement within IT systems, assisting data architects in creating conceptual frameworks. Today, data scientists, analysts, modelers, and architects use data models to develop business intelligence and predictive applications efficiently.
Therefore, the end goal of any data model is to
- Illustrate the data stored and used within a system
- Explain the what, where, why, and who of data elements
- Find and establish the relationship between the different data types
- Establish the methods data can be organized and grouped
- Identify the formats and attributes of the data
Thus, a data model is one of the most useful tools for data management. It allows analytical teams to document data requirements before analyzing data or create predictive models and developers to identify errors before writing code.
Data models play a crucial role in data science, representing a significant development that has evolved over time. Let’s quickly look at the journey of data models and understand where they are today.
Evolution of Data Modeling
While the term ‘data modeling’ may sound new, the concept dates back to the early days of computer programming, data processing, and storage. Planning and architecting data structures are fundamental ideas that have become more structured and sophisticated with the influx of data and new storage technologies.
The term ‘data modeling’ rose to prominence in the 1960s with the development of data management systems. Today, it’s considered a critical skill as professionals cope with vast data sources like IoT sensors, social media, clickstreams, and location-aware devices. This exponential growth includes diverse data types, from structured to unstructured (e.g., audio, video, text, raw sensor output), necessitating advanced data modeling techniques to handle the volume and speed of data generated.
Now that you understand the data models, let’s look at the various models.
Different Types of Data Models
As data models are visual specifications of business rules and data structures, we build them using a top-down approach, i.e., from understanding the high-level business requirements to the details of databases and file structure. This approach provides three categories of data models: conceptual, logical, and physical. Let’s look at each of these types below:
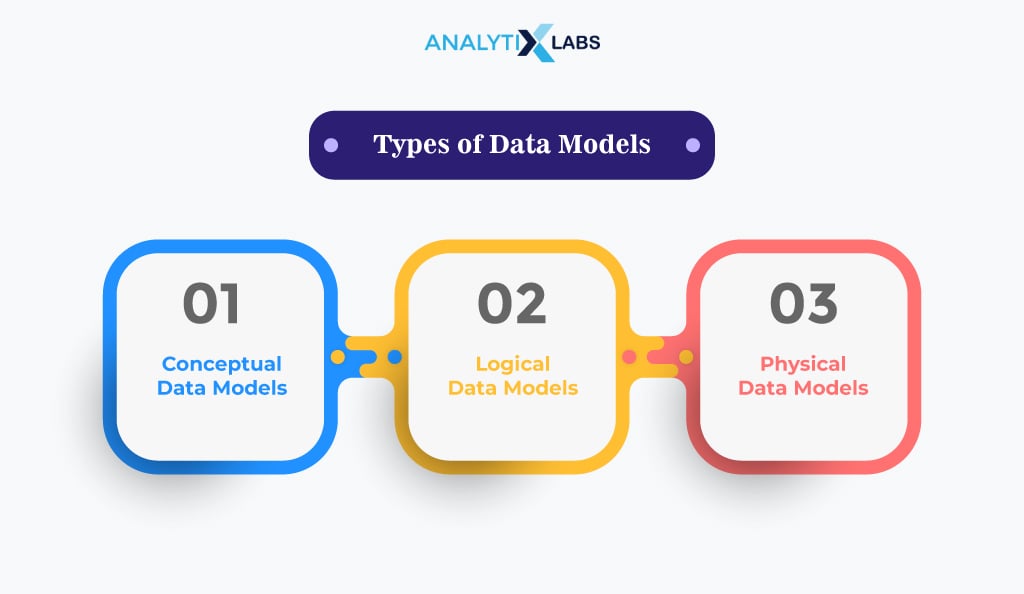
-
Conceptual Data Models
A conceptual model identifies the data required by business processes, analytical and reporting applications, and business concepts and rules. However, conceptual data models don’t define the data processing flow or physical characteristics.
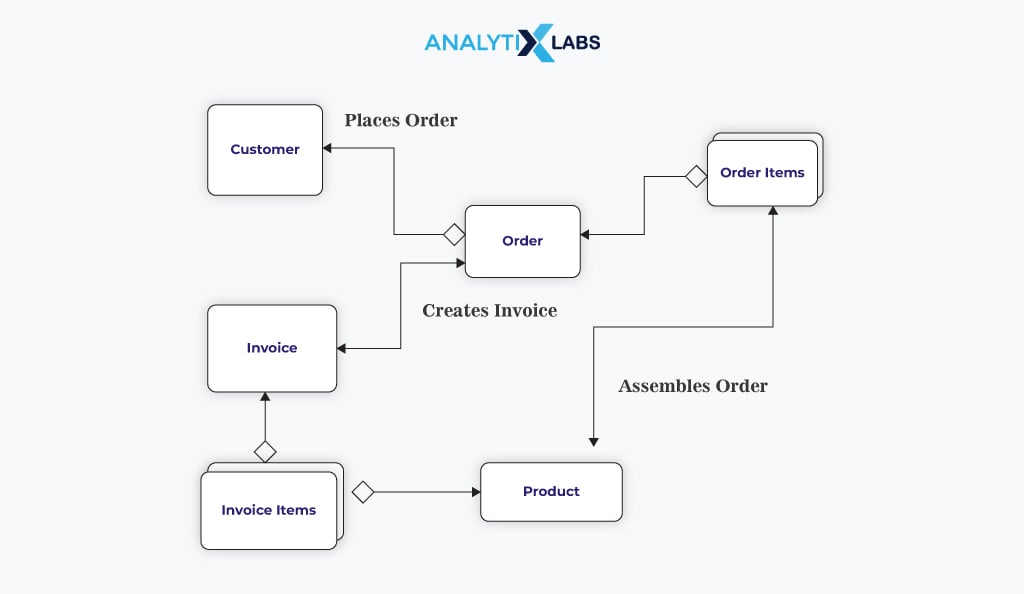
A conceptual data model provides a comprehensive overview of data, detailing content, attributes, conditions, constraints, business rules, organization methods, optimal data structuring recommendations, and specifying data integrity and security requirements. This model is typically presented as a diagram to foster understanding among technical and non-technical stakeholders, aligning everyone on project objectives, design, and scope.
The major advantage of such a model type is that it can be used as a starting point for future models. It helps define the project scope, allows all technical and non-technical stakeholders to participate in the early design process, and allows for a broad view of the information system.
The disadvantage, however, is that the return on time and effort is relatively low. It fails to produce a deep and nuanced understanding of the information system and is unsuitable for large systems, big applications, and the later stages of a project.
-
Logical Data Models
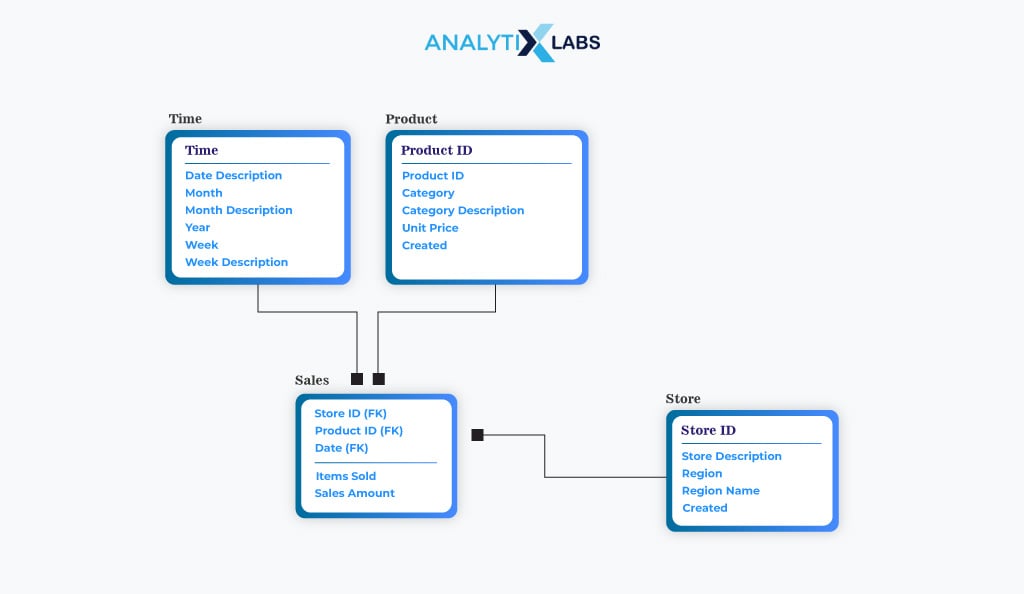
Logical data models identify the data structures, such as the tables, columns, and relationships between different data structures (typically through foreign keys). Thus, a logical model defines the specific entities and attributes. The data model is independent of a specific file structure or database and can be implemented on various databases such as columnar, relational, multidimensional, and NoSQL systems (and even on an XML or JSON file).
Organizations use logical data models to delve into complex data concepts and relationships beyond the conceptual stage. Developed collaboratively by data experts, these models are crucial for designing extensive databases like data warehouses and automated reporting systems. They bridge the gap between conceptual and physical data models, though agile teams may skip this step and move directly to physical modeling.
The primary advantages of logical models include facilitating feature impact analysis, enabling easy access and maintenance of model documentation, and expediting information system development through component reuse and adaptation based on user feedback.
However, drawbacks include rigid structure, limited depth of data relationships, inefficiency with large databases due to increased time and resource consumption, and difficulty detecting development errors.
Also read: A Guide to Data Warehouse: Definition, Concepts, Types, and More
-
Physical Data Models
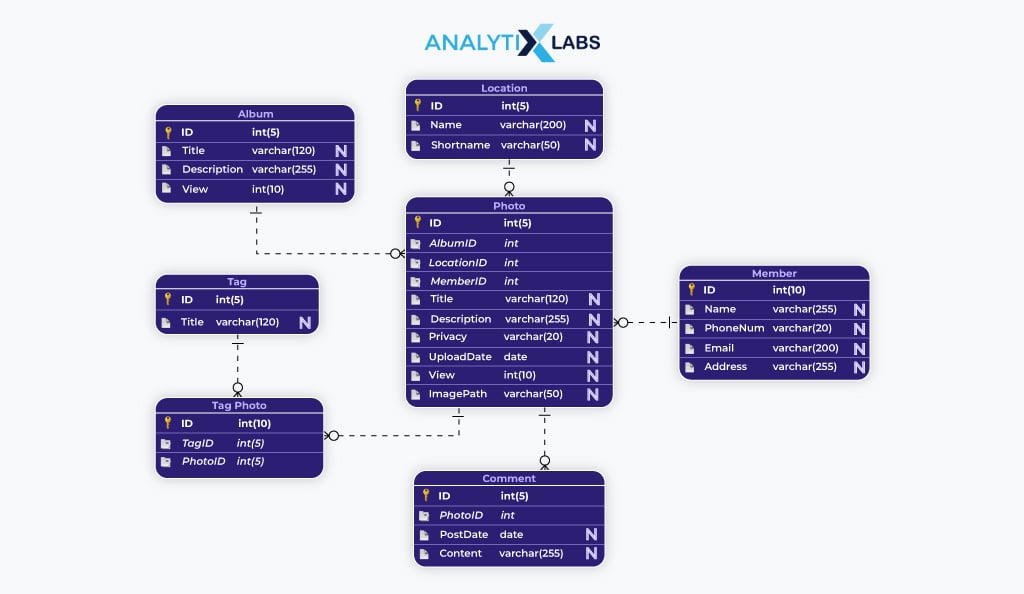
Physical data models are a bit more specific as they specify the file structure or database used in the system. For a database, these specifications include information about items like tables, columns, primary and foreign keys, indexers, triggers, data types, tablespaces, partitions, etc.
Thus, physical data models are created specifically for a particular DBMS technology and use that software’s terminology. Data engineers typically develop such models; they give details about the data file, types, and data relationships as represented in the DBSM, along with other details such as performance tuning, etc. Such models are created right before the final design is implemented.
Physical models offer benefits like preventing faulty system implementation, providing detailed database structure representation, enabling direct transition from data model to database design, and simplifying error detection compared to logical models. However, they require advanced technical skills, involve complex design, and are inflexible to last-minute changes.
Earlier, we mentioned that these model categories are developed using specific formal data modeling techniques, which dictate the precise design and infrastructure for visualizing the models.
Let’s explore various data modeling techniques (data model infrastructures).
Important Data Modeling Techniques
The data modeling techniques (and concepts) refer to the methods used to create the three data models discussed above. These techniques are approaches to developing data models that have evolved due to innovation in data concepts and new data governance guidelines. The main types of data modeling techniques are discussed below:

#1. Hierarchical Data Models
Data is stored in a hierarchical tree-like structure. Here, the collection of data fields is defined in terms of parent and child records. In such a structure, the child record has only one parent, whereas the parent can have more than one child.
Such a model comprises links that connect the records and their types (specifying the data contained within a field). Hierarchical models originated in the 1960s when they were developed for mainframe databases.
#2. Network Data Modeling
An extension of hierarchical data models is network data models. It differs from hierarchical models because one child record can have more than one parent. The CODASYL model is also known as the network data model because the Conference on Data Systems Languages (CODASYL) adopted a standard specification of this model in 1969.
This data model was largely used for mainframes; however, it was replaced with the advent of relational databases in the late 1970s. Network data models are considered to be the precursor to graph data models.
#3. Graph Data Modeling
Derived from network data models, graph data models are used in graph databases to represent complex relationships, including in NoSQL databases. The core elements of this model are nodes and edges. Nodes assign a unique identity to each entity, like rows in a relational model’s table. Edges connect nodes, defining their relationships—hence, nodes are also called links or relationships.
Each node must have at least one connected edge to define the structure properly. Edges can be undirected, bidirectional, or directed, specifying the nature of the relationship. Additionally, nodes and edges are represented using name-value pairs. Querying is simplified by labeling nodes and grouping them into sets. Nodes can be assigned multiple labels, accommodating diverse classifications.
#4. Relational Data Models
In relational data models, tables and columns store data that help define and identify the relationship between data elements. Several data management features, like containers and triggers, are included in such models. While this modeling technique was popular in the 1980s, its variation, such as the entity-relationship and dimensional data model, is commonly used for database modeling today.
#5. Entity Relationship (ER) Data Models
The entity-relationship (ER) model derives from relational data models and is a foundational infrastructure that we use widely in enterprise-level applications like transaction processing within relational databases.
ER models are particularly efficient in capturing and updating data as they have minimal redundancy and follow a well-defined relationship. Such a model contains entities representing people, things, places, concepts, events, etc., based on which the data is stored and processed as tables.
It also contains attributes that act as distinct properties and characters for a subject or entity, stored and maintained as columns. Lastly, relationships are crucial in ER models, defining the logical links between entities representing the business constraint or rule.
#6. Dimensional Data Models
Dimensional data models, derived from relational models like ER models, consist of attributes, relationships, facts, and dimensions. Facts represent numeric measurements of activities (e.g., product purchases, device events) stored in fact tables designed to minimize redundancy. Dimensions provide business context to facts, defining attributes like who, what, why, and where.
These models, often called star schemas, depict a star-like structure with facts at the center surrounded by dimensions. However, this representation oversimplifies model complexity, as most dimensional models include multiple fact tables linked to numerous dimensions.
Dimensional data models are widely used today, especially in analytical and business intelligence applications.
#7. Object-Oriented Data Models
We use this model when relational data models and object-oriented programming are combined. Here, an object represents data and relationships within a structure. Attributes also define an object’s behavior by establishing its methods and properties.
Such a model is useful because the objects can have numerous relationships between them. The two main concepts of object-oriented data models are classes and inheritance, where classes refer to a collection of similar objects due to their common attributes and behaviors. In contrast, the inheritance concept allows new classes to inherit behaviors (attributes) from other classes. If you are into software development, you might know these concepts.
No matter what type or technique of data model you choose, there is a specific process for building one. Below, the most common data modeling process is discussed.
How to Build a Data Model: Step-by-Step Process
Typically, data model building moves from a simplistic conceptual model to a complicated physical one. There are six steps that you should follow when developing a data model. The workflow of the data modeling process looks like the following:
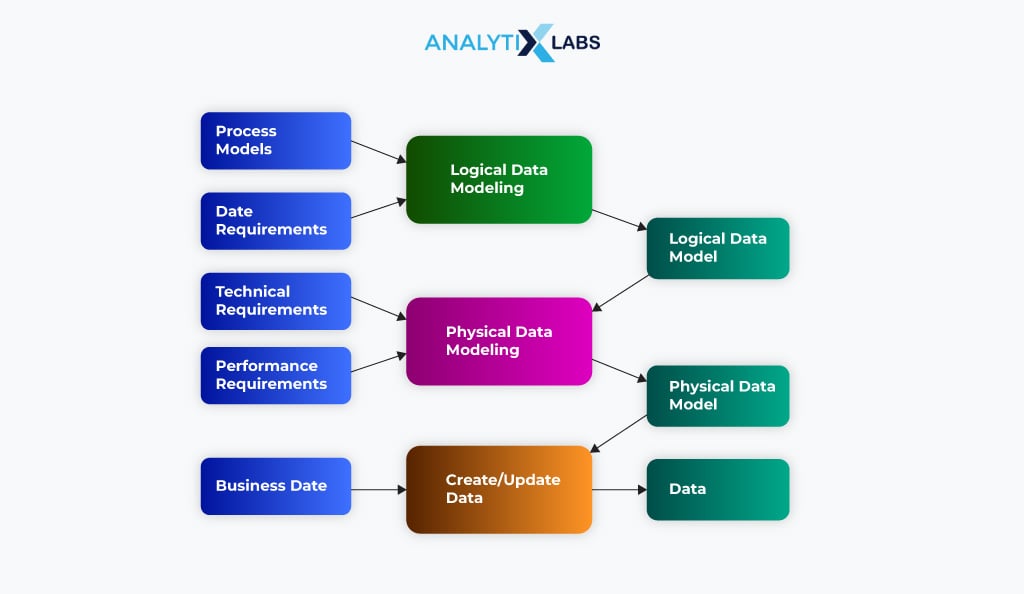
-
Step 1: Identification of Entities
The first step is to identify the events, things, subjects, or concepts represented in the dataset you need to model. You must ensure that every entity is logically discrete and cohesive.
-
Step 2: Identification of Key Properties
The next step is to ensure that each entity type is easily different and distinguishable from the other. This is to be done by carefully defining the properties of different entities. As each entity can have one or more unique properties referred to as attributes (making them different from each other), identification of the correct key properties becomes crucial.
-
Step 3: Identification of Relationships
The crucial aspect of any data model is how it defines the relationship different entities have with each other. You must carefully understand how different entities are related to each other, as this can affect how the information flows within the system.
-
Step 4: Mapping Attributes
Another crucial step is to ensure that the model makes the user aware of how the business should use the data. Several modeling patterns have been used to accomplish this. For example, object-oriented developers use design or analysis patterns, while stakeholders from other business domains use other formal patterns.
-
Step 5: Assigning Keys and Normalization
In data models, keys represent relationships between different data elements without redundancy. This is achieved through normalization, where numerical identifiers (keys) efficiently organize the data models and the represented data.
-
Step 6: Finalization and Validation of the Data Model
The last step in the data modeling process is to finalize the model by obtaining feedback from all stakeholders. This step is iterative; the data models are refined as business needs change.
You must be familiar with common tools in this field to develop a data model for your organization. Let’s discuss them next.
Top 6 Most Useful Data Modeling Tools
There are a few commonly used tools for performing data modeling. These include-

-
ER/Studio
It is a database design and data architecture tool compatible with multiple dataset platforms. It creates, manages, and documents database design and data assets. ER/Studio supports a wide range of platforms such as NoSQL (e.g., MongoDB) and numerous relational databases, JSON schema, automation, scripting, forward and reverse engineering, etc.
-
Domo
Domo provides a secure data foundation and a cloud-native experience. The tool can be used to optimize business processes at scale.
-
Enterprise Architect
It is a graphical tool with multi-user access that allows multiple stakeholders to collaborate in data model development. Anyone from beginners to advanced data modelers can use Enterprise Architect. It has many built-in capabilities that help create data models, such as data visualization, maintenance, testing, reporting, documentation, etc.
-
Apache Spark
Apache Spark, an open-source processing system is typically used for managing and modeling big data. Its high fault tolerance allows for its widespread popularity.
-
Oracle SQL Developer Data Modeler
While it is not open source like Spark, Oracle SQL Developer is free to use for developing data models. It allows you to create, browse, and edit all three types of data models (conceptual, logical, and physical).
Also read: Guide to master SQL for Data Science
-
RapidMiner
While RapidMiner is an enterprise-level data science platform, it can collate, analyze, and visually represent data. With its user-friendly interface, this tool is especially suitable for beginners with little experience. It allows for the easy creation of basic data models.
Lastly, before concluding, let’s look at the major advantages and disadvantages of the data model, as no technique is without its flaws.
Advantages and Disadvantages of Data Models
Creating a data model to manage your data has several benefits and downsides. A few of the crucial pros and cons of data models are the following-
Advantages
- Data models help standardize definitions, terminologies, concepts, and formats on an enterprise level, which helps increase harmony and internal agreement of standards and definitions within an organization.
- A data model often has multiple stakeholders and requires inputs from multiple places. This enables the involvement of different individuals in the data management process. The collaboration of various teams eventually helps build a better system that is more robust to organizational changes.
- Data models provide a blueprint to database designers, allowing efficient database design. They streamline the work of data designers and reduce the risk of missteps.
- Data models inform about the available data at an enterprise level, allowing for better data use and increasing overall business performance. Thus, data models help maximize the utility of available data.
- Data models can also enhance data accuracy. Identifying several inconsistencies and errors in the data during the development of data models helps increase the overall data quality.
Disadvantages
- Stakeholder engagement is crucial for successful data modeling efforts. Without participation from corporate and business executives, developing valid data models can be challenging. Bringing together individuals from various teams for data model development is inherently difficult due to differing perspectives and levels of understanding.
- Given the nature of data models, some business stakeholders struggle to grasp the process. This is mainly due to the abstract nature of the data model-building process. To avoid this issue, developers should start with conceptual and logical data models based on the business concepts and terminology familiar to all technical and non-technical stakeholders.
- Data models can become highly complex, especially when creating physical data models. If the data and databases within an organization are large, then the data model can become complex with each iteration.
- It’s tough to set the scope of a data model. As it’s an iterative process, the urge to completely understand every nook and corner where the data resides can make the initiative’s scope out of reach. Therefore, clearly defining a data model development initiative’s objective is important.
- Incomplete comprehension of business requirements during application development can result in invalid data models that fail to address business problems effectively. Engaging stakeholders to define clear business requirements is essential to avoid this issue.
Conclusion
Data models are crucial as they play a great role in storing data per the business’s requirements. As today’s organizations deal with vast amounts of data, there is a greater need for individuals who know how to develop data models, as data models ensure smooth data management. Create data models that make sense and explain how data is related and communicates with each other. Therefore, you must know about the various data modeling types and techniques.
FAQs
- What is the data model and type?
In software engineering and data science, professionals use the data model to assess all data dependencies for an application, define various data types, and illustrate the use of data and its relationships with other datasets, typically through visualization. The three main types of data models are conceptual, logical, and physical.
- What is a data model in DBMS?
In a DBMS, a data model explains the logical structure of it. Database modeling helps the user understand how different data elements are related and how the data is stored, accessed, handled, and changed within the information system. This information is provided using peculiar symbols and language to ensure that all the members within a particular organization understand the DBMS’s structure.
- What is a data model and its components?
Different data model infrastructures have different components. Common data modeling infrastructures (techniques) are hierarchical, network, graph, relational, entity relationship, dimensional, and object-oriented. The common components found in such data models are classes, inheritance, entities, attributes, relationships, facts, dimensions, nodes, edges, datasets, event triggers, etc.
We hope this article helped you expand your understanding of data models and answered the question of what data modeling is. You can enroll in our industry-ready courses to learn more about data science!
- Datalake vs. Data Warehouse: Understanding the Concepts, and Related Terms
- Data Analyst vs Data Scientist: Which career option to choose in 2024?
- Data Warehouse Interview: Top 30 Questions and Answers to Crack Your Next Interview [2024 edition]
- What is a Data Pipeline? Types, Benefits, Best Practices and More





