
In the evolution of computer science, we’ve shifted from manually crafted programs to machine learning-driven solutions. The recent game-changer is deep learning, leveraging vast data to tackle once-deemed insurmountable challenges. Deep learning outpaces traditional techniques with artificial neurons mirroring the human brain, hidden layers, and backpropagation.
Different parts of the human brain are responsible for activities like intuitive decision-making, language processing, image recognition, etc.; similarly, different deep learning algorithms are responsible for solving different problems.
For example, while multilayer perception is responsible for decision-making based on historical data, a recursive neural network solves language-based problems.
“Deep” in deep learning refers to networks with more than three layers, while networks with two or three layers are basic neural networks.
This article will focus on one such neural network algorithm responsible for creating computer vision applications – Convolutional Neural Network, i.e., the CNN algorithm. However, before getting into the details and answering what CNN is, let’s start with some background and a basic understanding of this class of artificial neural networks.
What is CNN?
Today, CNN is the one algorithm that started the revolution in the field of computer vision. Its capability lies in its architectural design. While that will be discussed, let’s first understand where the CNN algorithm comes from and what we mean by it.
Background
Before understanding CNN in detail, let us first look at the origin and development of the field over time.
-
1950s – 1980s
Since the early days of AI, researchers, while convinced of the potential of artificial neural networks, have found it difficult to solve complex non-linear problems. It is, therefore, no surprise that they were also having a hard time understanding and processing visual data through neural networks.
The research for the solution kept on going. The search that started in the 1950s found some solution when, in the 1980s, a new neural network technique known as Convolutional Neural Network (CNN) was developed by researcher Yann LeCun.
-
1980s – 2010s
While initially, LeNet (the early version of CNN named after LeCun) could only recognize handwritten digits, it was considered a great leap forward in deep learning as previously it was unknown to solve such complex problems using computers.
The algorithm started gaining traction when it was adopted to read pin and zip codes in postal sectors. The issue at that time was that the algorithm in its current form could not scale due to its design and the limited resources available.
Also read: Understanding Genetic Algorithm: Guide to Types, Advantages, and Limitations
CNN required large, well-labeled data to be processed, and enough computing resources were not readily available then, which restricted its widespread adoption.
Things began to change with the advancement of computer hardware, and with the revolution of GPUs, cloud computing, microchip processing, etc., the capability of CNN began to surface.

The watershed moment happened in 2012 when an AI system, AlexNet, developed and named after its primary creator, Alex Krizhevsky, won the ILSVRC (ImageNet Large-Scale Visual Recognition Challenge).
Rather than using two convolutional and pooling layers in addition to two fully connected layers and an RBD classifier in the output layer as done in LeNet, Krizhevsky went for a more complex architecture with five convolutional, three pooling, and two fully connected layers using the softmax function in the output layer.
Using large datasets like the well-labeled ImageNet dataset and advanced computational resources allowed him to retrieve CNN, making AlexNet win the 2012 ImgeNet computer vision contest.
The system won the competition with 85% accuracy, while the runner-up scored only 74%, making it an undisputed winner.
The AlexNet system could mimic the workings of human vision, instilling confidence in other researchers to revisit multiple-layered neural networks, i.e., deep learning, for solving computer vision problems. Since then, much work has gone into this branch of AI.

Defining Convolutional Neural Network
Convolutional Neural Network, aka. CNN or ConvNet is a type of deep learning algorithm where a mathematical operation known as convolution is used instead of the traditional general matrix multiplication, at least in one of the hidden layers.
The difference here is that in convolution, a mathematical operation on two functions produces a third function that explains how the shape of one modifies the other.
While one can get into the complicated mathematics behind the functioning of CNN, one needs to have a proper knowledge of the architecture of CNN and the way it functions to implement CNN properly and perform computer vision tasks.
This is exactly what will be explored in the next two sections.
Also read: Fundamentals Concepts of Neural Networks & Deep Learning
To master the concept of neural networks, you must thoroughly understand the core concepts of Deep Learning. Our Deep Learning Course covers the core concepts of AI, Deep Learning, computer visual applications, Chatbots, text mining, language models, and more.
Transform your career with experiential learning at a pace that suits your needs. We offer classroom, online, and self-paced eLearning options to make learning easy.
- Explore the curriculum and projects covered in our Deep Learning with Python certification course. Opt for a free demo today.
You can also explore our signature data science and business analytics courses for a complete 360-degree learning experience. We have certification and PG courses. Currently, we are offering courses as follows –
- Data Science 360 Certification Course
- PG in Data Science
- Business Analytics 360 certification course
- Data Visualization and Analytics
- PG in Data Analytics
Have some more questions? Book a free demo with us. Also, check out our exclusive enrollment offers.
How does CNN work?
Convolutional Neural Network comprises multiple layers that work in distinct ways to solve computer vision problems. To understand the different layers of CNN, you first need an overall idea of how a convolution neural network functions.
-
Multilayer Network
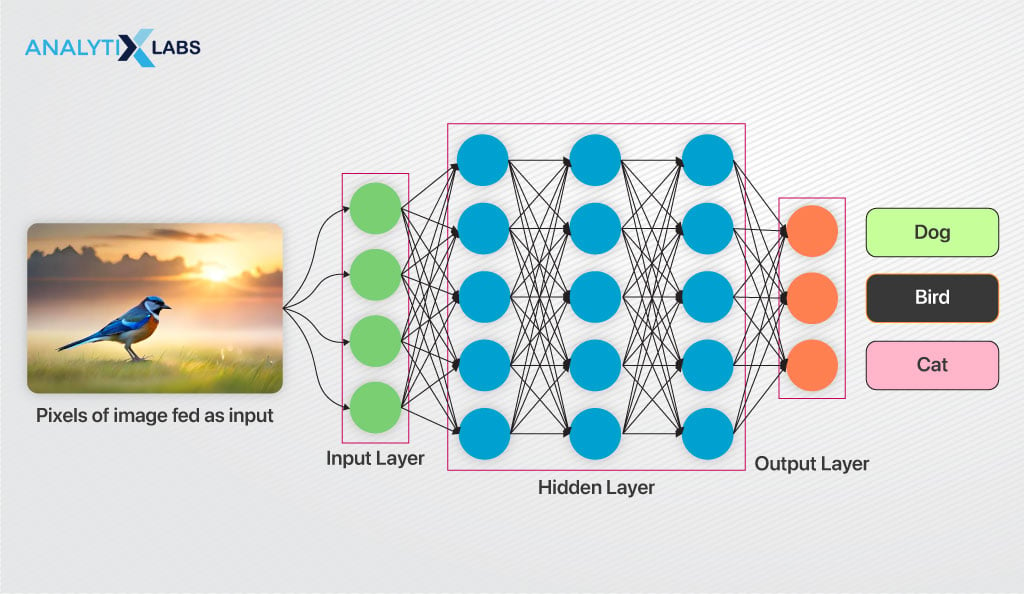
As CNN is a deep learning algorithm, it, therefore, is comprised of multiple layers of artificial neurons. As you might know, an artificial neuron mimics the working of the human brain cell.
The artificial neuron calculates the weighted sum of the inputs and runs it by an activation function that returns an output. The weights dictate the behavior of each neuron.
-
Convolution
An image consists of pixels, serving as input for a CNN. Each hidden layer generates activation maps, emphasizing vital features.
Neurons in the CNN consider pixel patches as input, multiplying pixel color values by assigned weights. The neuron sums these products and passes the result through an activation function, capturing essential image characteristics.

In simple terms, multiplying pixel values with neuron weights and summing them is known as convolution, and the layer is referred to as a convolution layer. However, it’s important to note that this multiplication is more peculiar, as discussed in the next section.
A Convolutional Neural Network can comprise multiple such convolutional layers (along with other layers of CNN discussed in the next section), each having an activation function to detect features.
The activation function in the convolution layers is typically responsible for inducing non-linearity in the network so that complex learning can occur.
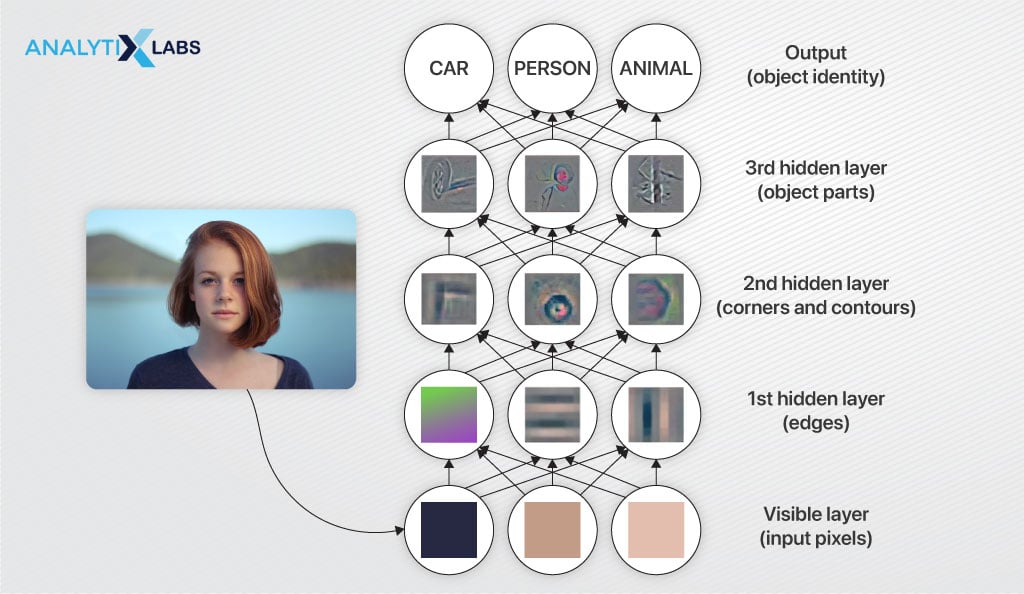
While the first hidden layer detects basic features in an image, such as the vertical, diagonal, and horizontal edges, the next few layers extract more complicated features.
The output of the first hidden layer gets fed to the next layer, which extracts corners, a combination of edges, and other complicated features.
The third layer considers the output of the second layer as its input and, in turn, extracts even more complicated features.
As you progress deeper into the network, increasingly complex features are extracted, and the final layers specialize in detecting higher-level features such as faces, objects, and so on.
-
Output
The output layer’s activation function decides how the output is provided. Typically, the activation function is set to return values between 0 and 1, indicating the network’s confidence in associating the input image with a class.
For example, a convolution network classifies apples, oranges, and peaches will return probabilities for each class for an input image.
These probabilities will indicate how likely the input image belongs to each class. So if we get 40% for apples, 25% for oranges, and 35% for peaches, then as per the network, the input image is probably of an apple.
-
Backpropagation
The key aspect of deep neural networks, including Convolutional Neural Networks (CNNs), involves adjusting neuron weights to extract accurate features from images. This process, known as training, begins with a large, well-labeled training dataset.
For instance, the ImageNet contest dataset comprised 14 million labeled images, while the MNIST dataset contained 70,000 images of handwritten digits.
The training begins by assigning random weights to each neuron. Each labeled image in the training dataset is processed with these random values, producing a predicted label.
The predicted label is then compared with the image’s actual label. If they don’t match, which is likely initially, the neurons’ weights are slightly adjusted, and the network is re-run to make a new prediction.
This adjustment process, called backpropagation, incrementally brings the network’s output closer to the ground truth.
In backpropagation, we employ the principle of gradient descent, utilizing mathematical concepts like partial derivatives to adjust neuron weights and minimize the loss function (the measure of error).
Each iteration, where we use the entire training dataset to make predictions, calculate errors, and adjust weights using backpropagation, is an epoch.
As a result, we anticipate the network’s accuracy to improve with each epoch and the weight adjustments become smaller. You complete the training once the network converges, meaning there is a plateau in the accuracy improvement, and no further weight adjustments occur.
-
Validation
After completing the training, the network is evaluated on the test dataset, an untouched labeled dataset not used for training. The trained network makes predictions on this test dataset. If the network performs similarly to the testing phase, the model is considered to generalize well. If, for some reason, it performs worse, the model is considered ‘overfitted’.
Overfitting typically happens due to a lack of variety in images in the training data, networking going through too many epochs during the training, or other reasons arising from incorrect values of various parameters.
As you can see, the working of CNN is similar to other neural networks, with the difference being how it processes the input. However, to better understand the nitty-gritty of CNN, you need to understand the various types of layers involved in its working.
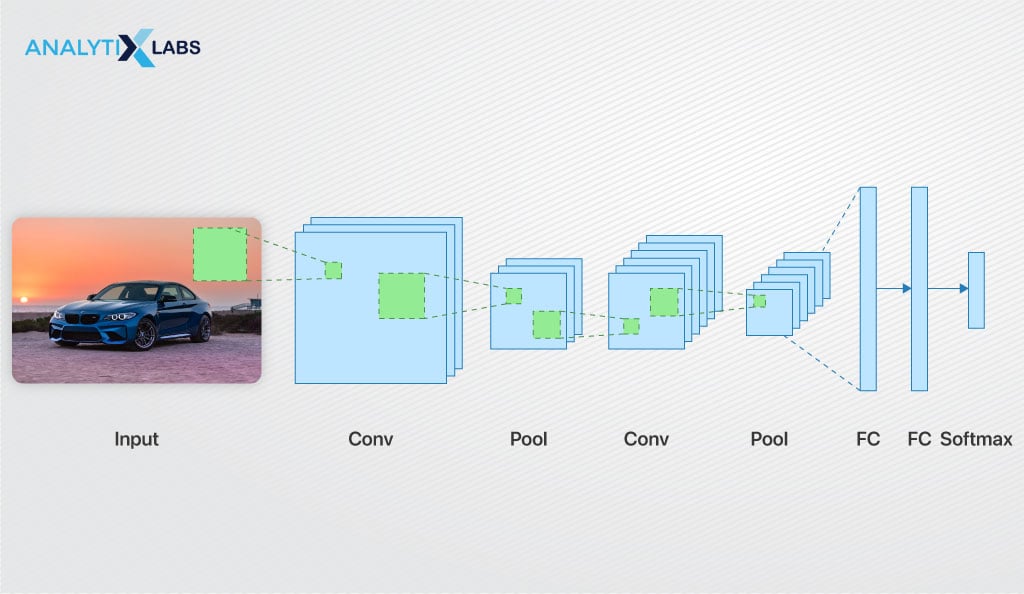
Understanding the CNN Architecture
So far, we have discussed that convolution is a mathematical tool that separates and identifies various input image features in a feature extraction process. The process discussed so far only mentioned a hidden layer (a convolution layer), whereas, in reality, there are a few more layers in addition to the convolution layers stacked together to create the architecture of CNN.
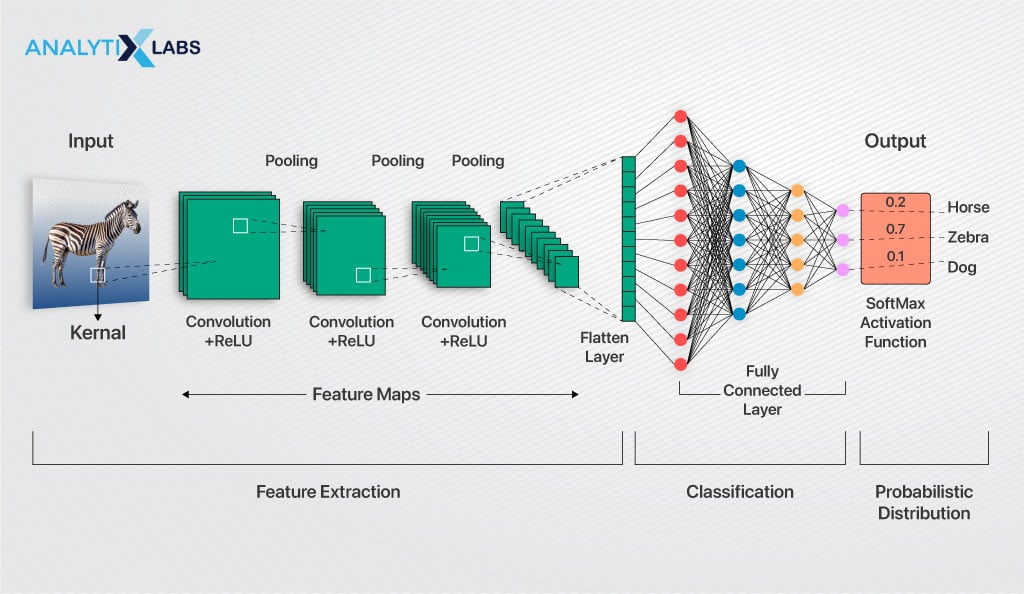
The following are the most crucial layers in working a convolutional neural network that will help you understand what a convolutional neural network is.
-
Convolution Layer
Of the many layers of CNN, the first layer (after the input layer) is the convolutional layer that extracts the features from the data. As discussed previously, with each successive convolution layer, more complex features are identified and extracted from the image.
However, a few key details regarding its working were missed.
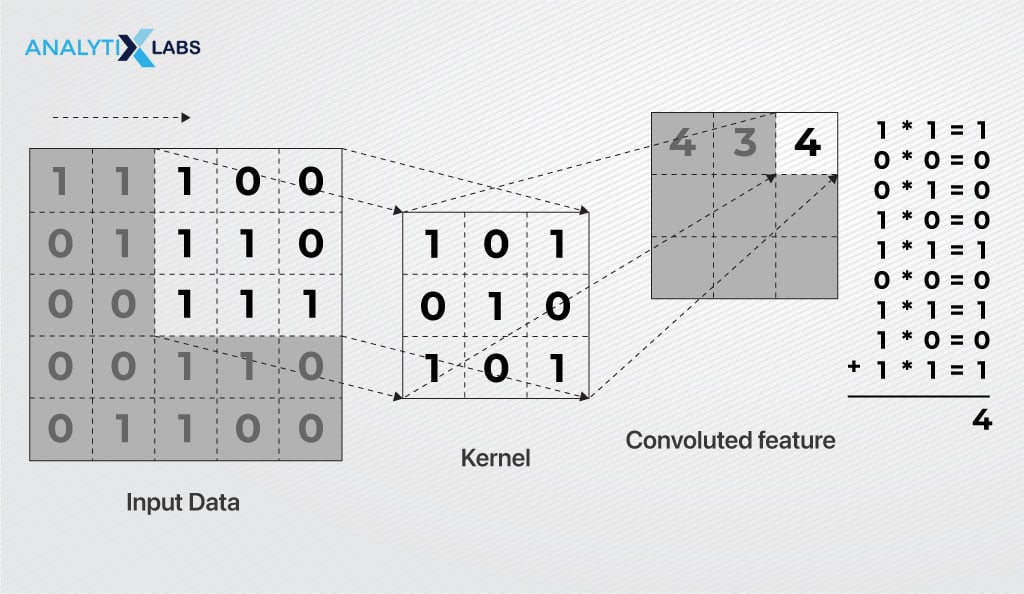
In convolution, the initial matrix is a filter, also known as a kernel, with a size of MxN. This filter comprises learnable parameters (kernel weights) that modify its functions. The second matrix is a confined portion of the image.
The dot product between these matrices occurs by sliding the filter over the input image, with the dot product calculated between the filter and the restricted part of the image, limited by the filter size (MxN).
To be precise, the filter for the non-colored image is MxNx1, while for the colored image, it is MxNx3.
Here, M and N are the height and width of the image while 3 is the depth of the image (the depth is 3 for a colored image as it comprises stacked R (red), G (green), and B (blue) colored images).
The filter slides across the image, or the entire input volume, step by step, with each step referred to as a stride.
This process produces an outcome known as a feature map or a convolved feature, highlighting key features such as corners, edges, and other essential information in an image.
Preserving the spatial relationship between pixels is crucial for the feature map. The convolution layer then passes its output to the next layer but does not directly proceed to the subsequent layer.
Instead, the output experiences a non-linear activation function, like ReLU, and transmits the resulting output to the following layer.
-
Pooling Layer
Typically, a pooling layer follows a convolution layer to reduce the dimensions of the input data. As a result, convolution and pooling layers generally form pairs and work together.
The convolved feature map is large and can increase the computational cost and chance of overfitting; reducing its size is important.
Achieving this involves analyzing a restricted neighborhood, also known as a pooling region, in the input matrix and extracting its dominant features.
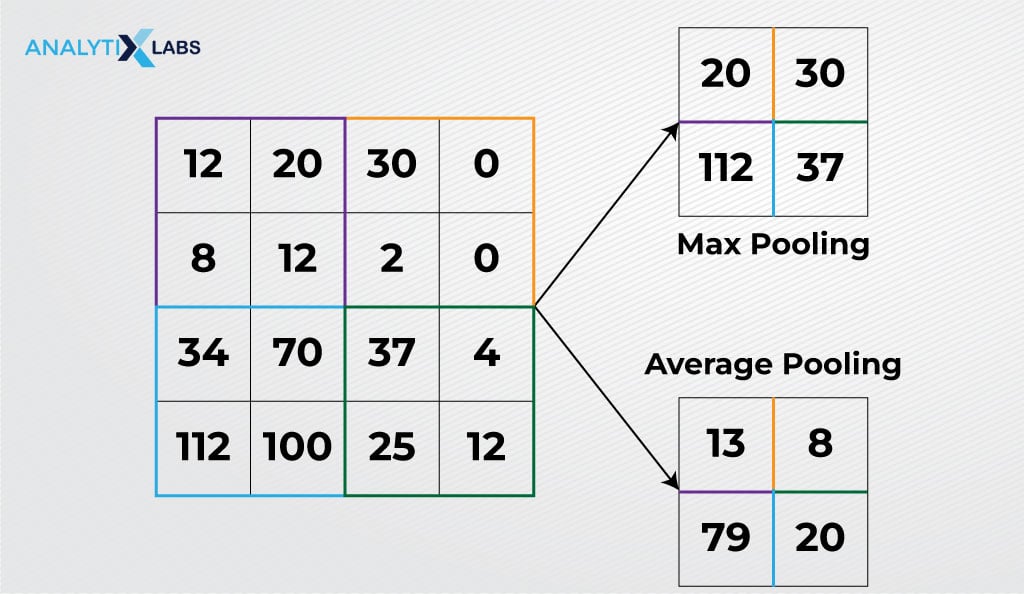
This extraction can happen in two ways – average pooling or max pooling. In average pooling, the average of all the values in the pooling region is calculated, while in max pooling, the maximum value within the pooling region is considered.
By performing such a process, the resultant matrix comprises the main features of the input matrix (i.e., the input image) in fewer dimensions or, in other words, summarizes the features extracted by the convolution layer.
-
Fully Connected Layer
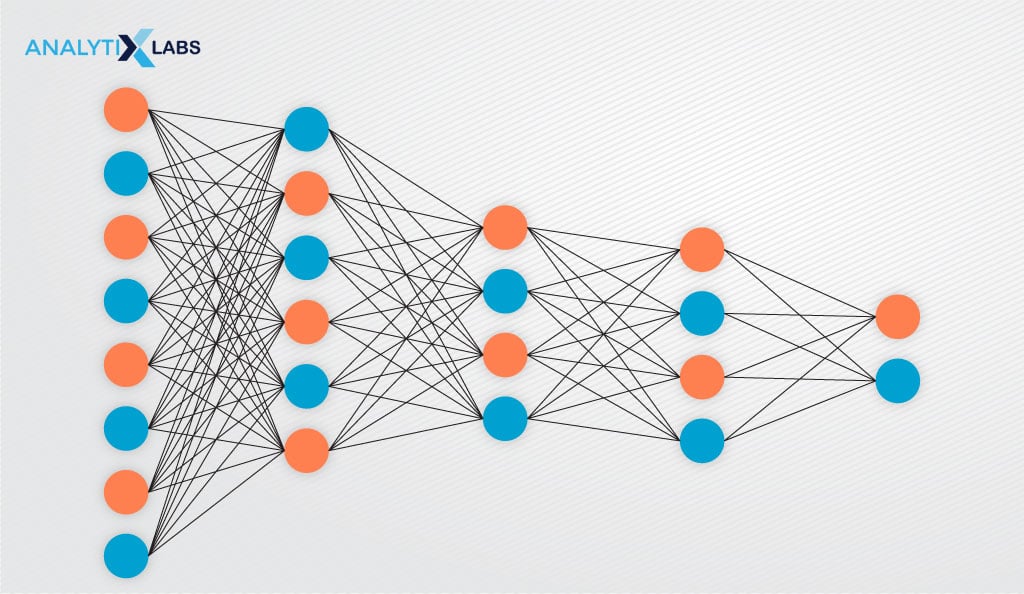
Until now, the network has only extracted the relevant features and reduced its dimensions; however, no classification has occurred. Flattening the input image into a single-column vector allows the utilization of a conventional, fully connected, dense, feed-forward neural network for classification.
In a fully connected layer, nodes from one layer connect to every other node in the next layer.
Multiple fully connected layers process the flattened vector, akin to data in a frame, distinguishing crucial features for image classification. Positioned just before the output layer, they conclude the process, refining the model after feature extraction for accurate classification.
-
Output Layer
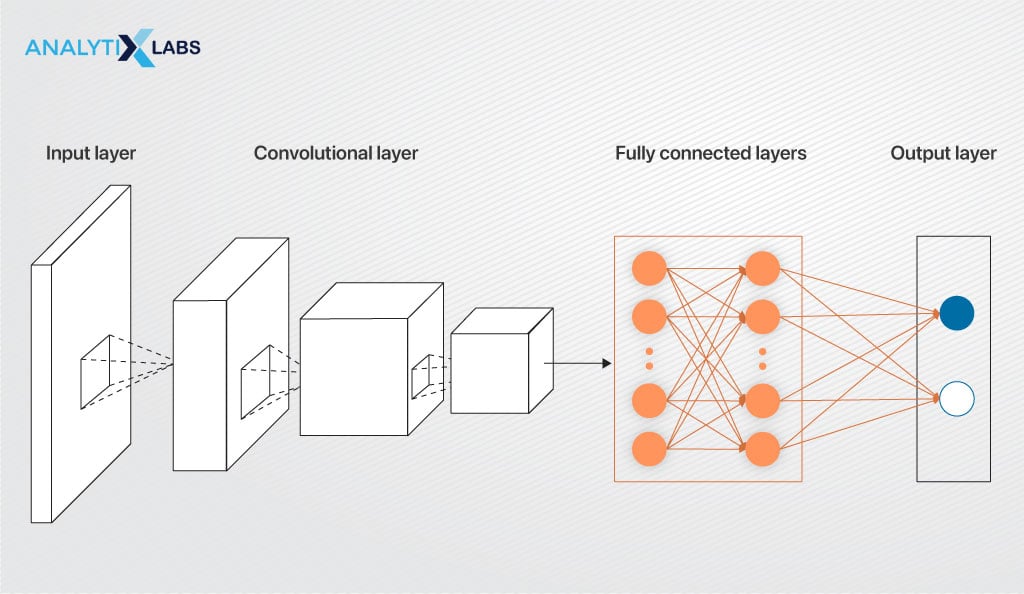
An output layer typically utilizes a logistic function like sigmoid or softmax to perform classification on the output of the final fully connected layer. This process assigns a probability score to each class, enabling classification.
-
Dropout Layers
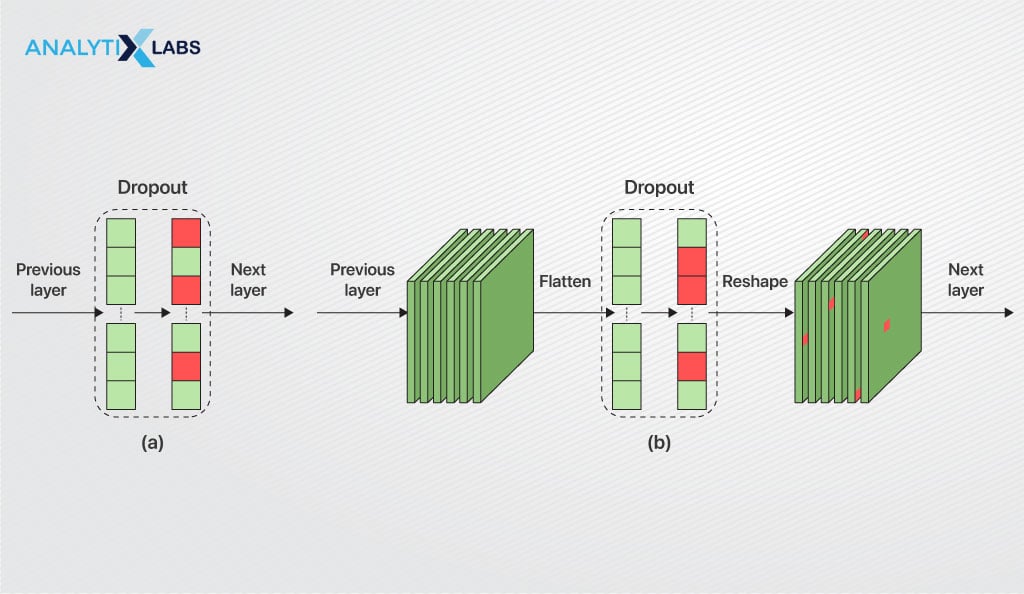
One issue with the fully connected layer is its dense architecture can easily cause the model to overfit the training dataset. A dropout layer randomly drops a few neurons from the network to address this issue.
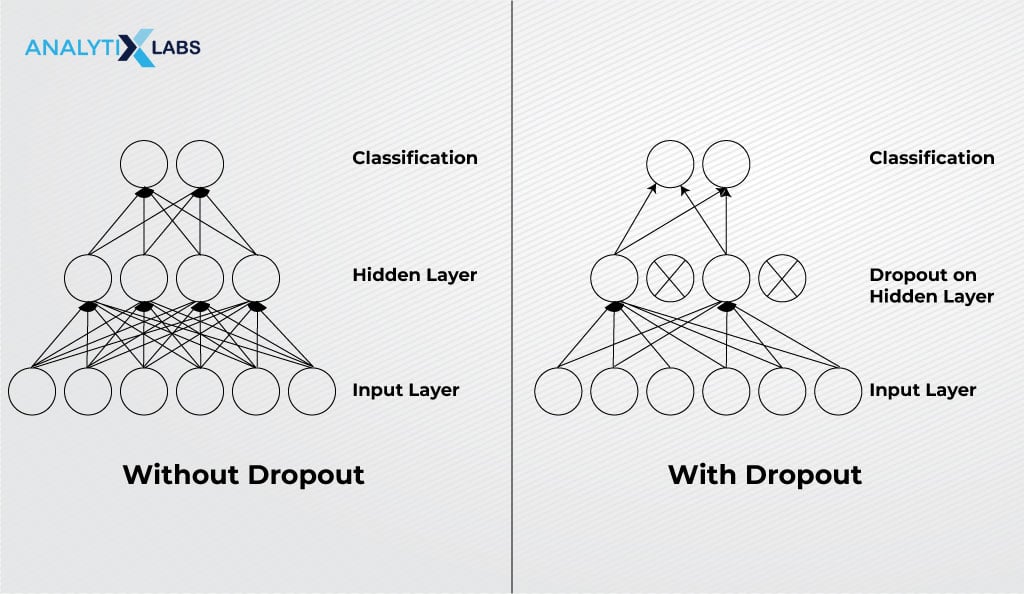
For example, a dropout value 0.15 can make 15% of the neurons drop out from the network, ensuring that the model doesn’t overfit during training.
As you may have noticed, the architecture of the Convolutional Neural Network is complex, with a lot of room to play around. This is why numerous variations to this architecture give rise to various types of CNN.
As the core of the convolutional neural network is explained, you can explore its types, as discussed next.
Types of convolutional neural networks
The following are the most common types of neural networks that are still commonly used.
1) LeNEt
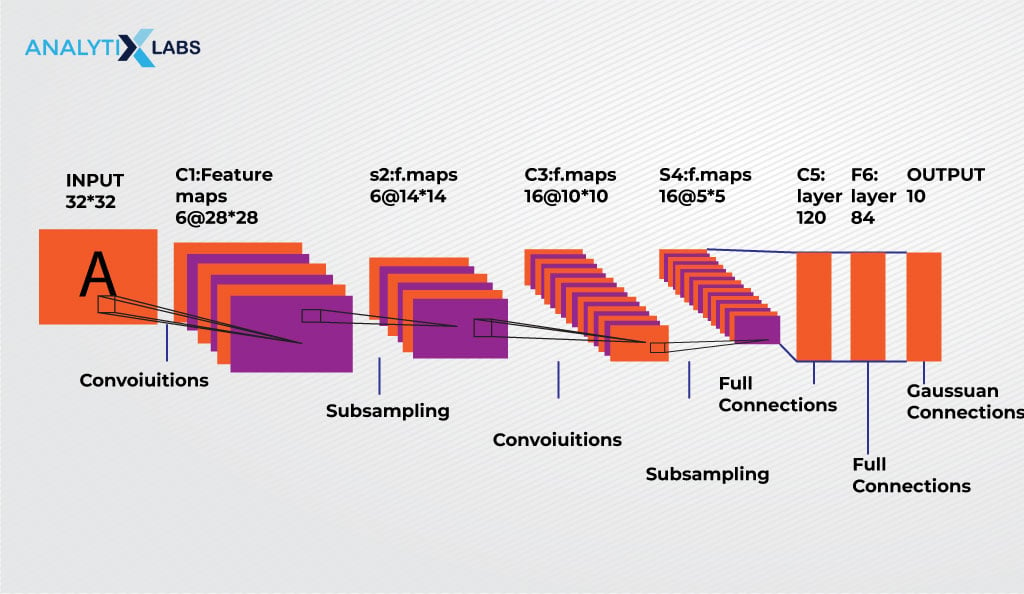
LeNet, the pioneering design of CNN, was created to recognize handwritten characters. It considers a series of convolutional and pooling layers followed by a fully connected layer and a softmax classifier.
2) VGGNet
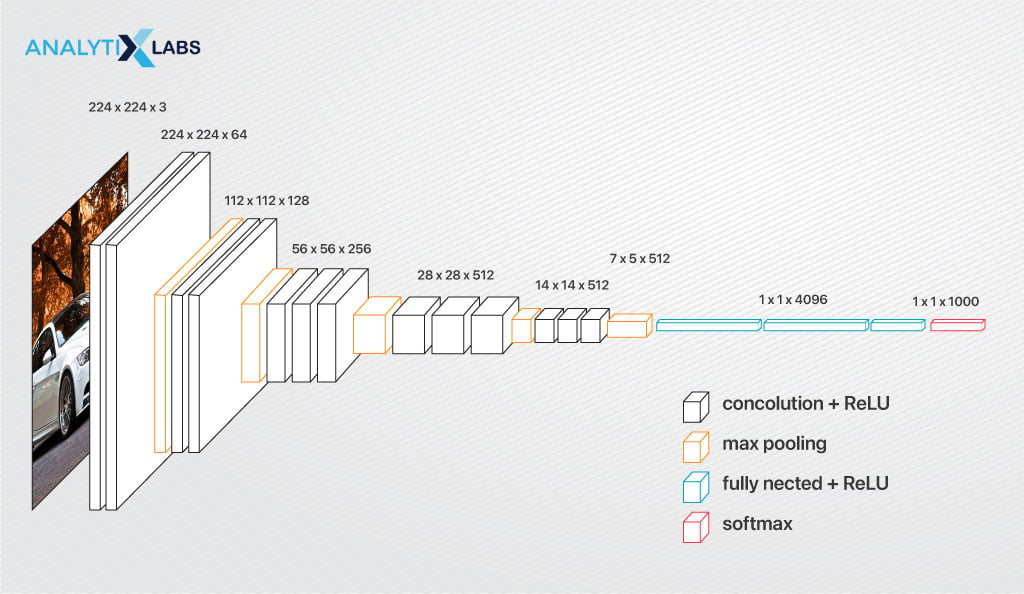
Visual Geometry Group – an engineering science research group at the University of Oxford designed and developed VGGNet that uses small convolutional filters of size 3×3 but has a deep architecture with layers up to 19.
This allows the network to learn increasingly complex features. It uses max pooling layers to reduce the feature map’s spatial resolution and increase the receptive field, making the network recognize objects of varying orientations and scales.
3) AlexNet

The winner of ILSVRC 2012, AlexNet uses five convolutional layers with max pooling and three fully connected layers with ReLU as the activation function used throughout the network. Apart from the usual small convolutional filters of size 3×3, it also uses filters of 5×5 and 11×11.
4) GoogLeNet
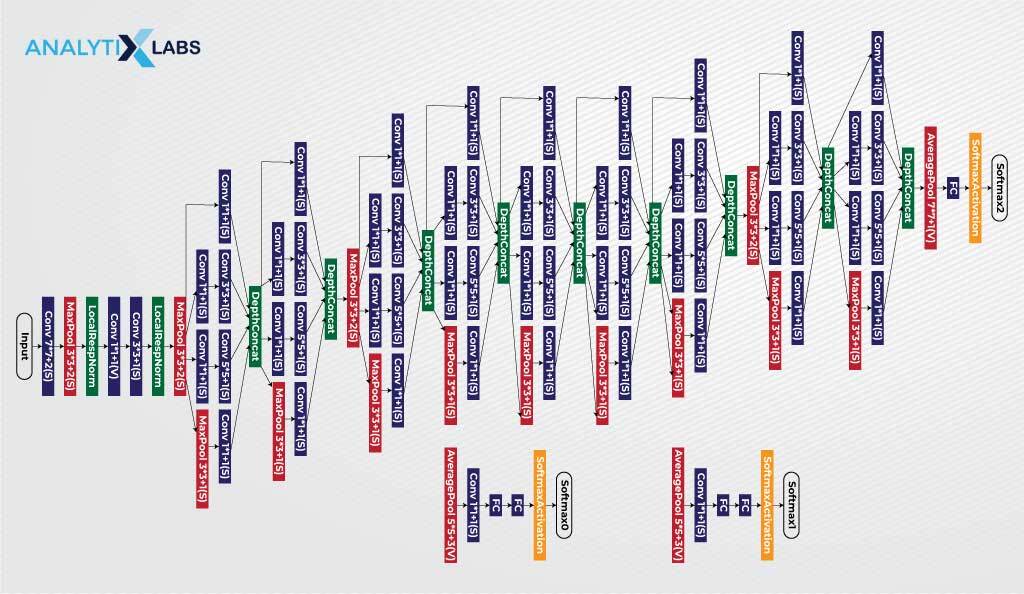
Developed by researchers at Google, GoogleNet won the ILSVRC. It consists of multiple parallel convolutional layers. Each of these parallel layers has different filter sizes, followed by a pooling layer and the concatenation of outputs. This parallel architecture allows for learning features at multiple resolutions and scales.
At intermediate layers, auxiliary classifiers manage overfitting, enabling the network to learn more discriminative features.
Beyond this brief overview, explore additional CNN types like ResNet, MobileNet, R-CNN, Fast R-CNN, Faster R-CNN, etc., to enrich your understanding. We will explore this remarkable network’s advantages, disadvantages, and applications.
Benefits and Limitations of CNN
Before implementing CNN into your projects, you must familiarize yourself with its benefits and limitations.
Benefits
Limitations
Applications of CNN
Any situation where computer vision needs to be performed becomes an avenue for applying CNN. While it’s impossible to list down all the applications of CNN, the common ones include-
- Automotive : CNN is used for running self-driving cars and autonomous vehicles
- Social Media : CNN helps identify different individuals, objects, places, etc., in users’ photographs.
- Healthcare : CNN powers software that detects anomalous conditions, such as the presence of cancer cells in patients.
- Law Enforcement : Many law enforcement have used CNN to perform facial recognition on fugitives who have changed their look to hide from authorities.
- Optical Character Recognition : Today, with the help of CNN, one can digitally recognize handwritten or printed text from scanned documents, images, or other sources. This is later used downstream for performing real-time translation, as Google does.
As there are so many applications of CNN, it’s no surprise that many want to build such a network to solve some practical problem. The crucial thing yet to be discussed is how to design a CNN. We have discussed a few general tips that you should follow.
How to Design a CNN?
Certain rules can help you when you are designing your own CNN. The crucial ones are the following-
Filter size
While the filters’ weights are derived during training, it’s up to you to set the size of the filter. If you need to recognize small and local features, use a smaller filter, such as 3×3 or 5×5.
However, suppose there is a requirement to capture high-level, global, and representative information.
In that case, a larger amount of pixels for the network is needed, and to achieve this, larger filters such as 9×9 or 11×11 are used. You should typically use filters with odd sizes.
Stride
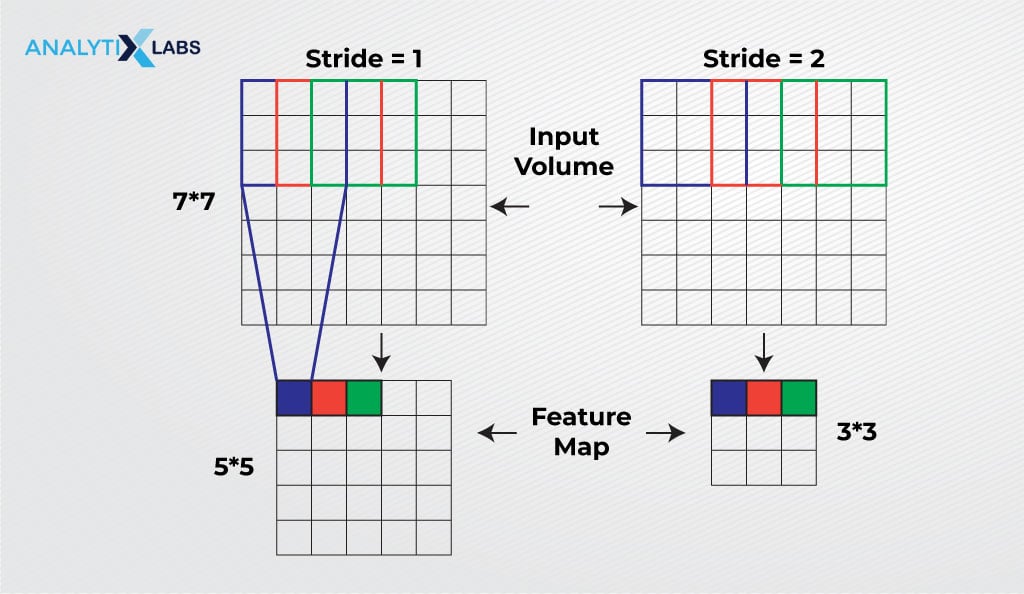
As discussed earlier, the stride is the step during convolution where the filter slides over the image. It is used to decrease the input size as one can set the number of pixels to skip after each element- multiplication. After convolution, the size shrinks, and this reduction is a function of the stride value because the function of size shrinkage is-
ceil(n+f-1)/s)where,
- n = input dimensions
- f = filter size
- s = stride length
- ceil = rounding off output to closest highest integer
Number of channels
When you use more channels, you employ more filters that, in turn, learn more features, increasing the chances of the network overfitting.
Therefore, you must consider this relationship when setting the number of channels. Typically, for color images, you can keep it to 3.
Pooling Layer
Generally, max pooling is used among all the pooling options. The typical filter size used for max pooling is 2×2 or 3×3, with the stride set to 2.
Activation Function
For hidden layers, you should use ReLU. If you don’t get the desired results, try Leaky RELU or ELU.
Types
The classic CNN types such as LeNet, VGG-16, VGG-19, and AlexNet work the best, and their architecture should be used for inspiration. Common architecture is Conv- Conv-Pool- Conv- Conv-Pool or Conv-Pool-Conv-Pool .
Evolution
- Start with smaller filters and gradually increase the filter size, first learning local and later learning global features. It would help if you kept adding layers until the model overfits. Once desired accuracy is achieved, use regularization methods like dropout layer, l1/l2 regularization, batch norm, etc., to address overfitting.
- For simple problems, start with one hidden layer, 10 kernels with 3×3 dimension, and one max pooling layer, and slowly increase the number of layers and kernels. Manipulate batch size, learning rate, optimizer, and other parameters to increase training time and accuracy gradually.
- In case of data scarcity or complex tasks, employ pre-trained networks for a head start using transfer learning. Adjust the last layer, add a new layer, or tune parameters to align the network with your specific data, leveraging features learned on a previous dataset.
You can refer to this paper for a deeper understanding of designing a convolutional neural network.
Before concluding, let’s address a common question individuals have when they start learning CNN for the first time- what is the difference between CNN and regular neural networks?
There are reasons why CNN is preferred over regular neural networks for solving computer vision problems; these reasons are discussed next.
CNN vs. Neural Networks
Regular neural networks face scalability challenges, especially when dealing with larger and more complex input images. As image size and complexity increase, the failure manifests in the demand for larger, costlier neural networks, leading to a substantial escalation in resource and computational requirements.
Apart from scalability issues, there are design flaws with regular neural networks. When several details are attempted to be learned by the regular neural network, it tends to overfit. Ultimately, such a network learns noise and fails to identify the required features and patterns in the data, causing it to fail.
On the other hand, CNN uses parameter sharing, i.e., as the filter of a layer moves across the image, their associated weights remain fixed, making the network less computationally intensive.
Also read: Activation Functions In Neural Networks
Conclusion
The Convolutional Neural Networks (CNN) domain is undergoing rapid evolution, significantly reshaping the landscape of artificial intelligence.
As a practitioner, it is imperative to comprehensively explore CNN, delving into its operational mechanisms, architectural intricacies, diverse types, inherent advantages, and attendant limitations before practical implementation.
While cognizant of its drawbacks, this network is here to stay for a while, and you must learn and implement it.
FAQs:
- Why is it called Convolutional Neural Network?
A specialized kind of linear mathematical operation called convolution gives CNN its name. In at least one of the hidden layers in CNN, this operation performs multiplication by sliding over two functions and returning a third function. We refer to it as a convolutional layer.
- What are the three layers of CNN?
Like any other neural network, the three CNN layers are the input, hidden, and output layers.
- What are the four hidden layers of CNN?
The four hidden layers of CNN are the convolutional layer, the pooling layer, the fully connected layer, and the dropout layer.
- What are the main components of a CNN?
Important components of a CNN are convolution, activation functions, backpropagation, and subsampling (pooling).
We hope this article answered questions like what CNN is and its various layers and types and helped expand your understanding of CNN. You can contact us to expand your knowledge horizons on CNN!
: How GANs are Transforming AI?")




